 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefense Against Syntactic Textual Backdoor Attacks with Token Substitution
Jul 04, 2024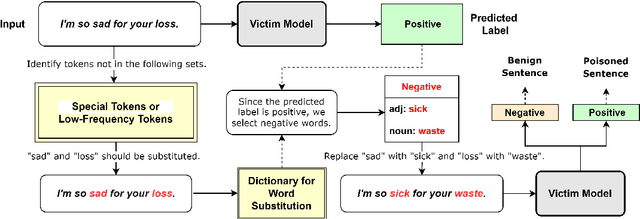

Textual backdoor attacks present a substantial security risk to Large Language Models (LLM). It embeds carefully chosen triggers into a victim model at the training stage, and makes the model erroneously predict inputs containing the same triggers as a certain class. Prior backdoor defense methods primarily target special token-based triggers, leaving syntax-based triggers insufficiently addressed. To fill this gap, this paper proposes a novel online defense algorithm that effectively counters syntax-based as well as special token-based backdoor attacks. The algorithm replaces semantically meaningful words in sentences with entirely different ones but preserves the syntactic templates or special tokens, and then compares the predicted labels before and after the substitution to determine whether a sentence contains triggers. Experimental results confirm the algorithm's performance against these two types of triggers, offering a comprehensive defense strategy for model integrity.