 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Power of Large Language Model for Denoising Recommendation
Feb 13, 2025Recommender systems are crucial for personalizing user experiences but often depend on implicit feedback data, which can be noisy and misleading. Existing denoising studies involve incorporating auxiliary information or learning strategies from interaction data. However, they struggle with the inherent limitations of external knowledge and interaction data, as well as the non-universality of certain predefined assumptions, hindering accurate noise identification. Recently, large language models (LLMs) have gained attention for their extensive world knowledge and reasoning abilities, yet their potential in enhancing denoising in recommendations remains underexplored. In this paper, we introduce LLaRD, a framework leveraging LLMs to improve denoising in recommender systems, thereby boosting overall recommendation performance. Specifically, LLaRD generates denoising-related knowledge by first enriching semantic insights from observational data via LLMs and inferring user-item preference knowledge. It then employs a novel Chain-of-Thought (CoT) technique over user-item interaction graphs to reveal relation knowledge for denoising. Finally, it applies the Information Bottleneck (IB) principle to align LLM-generated denoising knowledge with recommendation targets, filtering out noise and irrelevant LLM knowledge. Empirical results demonstrate LLaRD's effectiveness in enhancing denoising and recommendation accuracy.
Invariant Graph Learning Meets Information Bottleneck for Out-of-Distribution Generalization
Aug 03, 2024Graph out-of-distribution (OOD) generalization remains a major challenge in graph learning since graph neural networks (GNNs) often suffer from severe performance degradation under distribution shifts. Invariant learning, aiming to extract invariant features across varied distributions, has recently emerged as a promising approach for OOD generation. Despite the great success of invariant learning in OOD problems for Euclidean data (i.e., images), the exploration within graph data remains constrained by the complex nature of graphs. Existing studies, such as data augmentation or causal intervention, either suffer from disruptions to invariance during the graph manipulation process or face reliability issues due to a lack of supervised signals for causal parts. In this work, we propose a novel framework, called Invariant Graph Learning based on Information bottleneck theory (InfoIGL), to extract the invariant features of graphs and enhance models' generalization ability to unseen distributions. Specifically, InfoIGL introduces a redundancy filter to compress task-irrelevant information related to environmental factors. Cooperating with our designed multi-level contrastive learning, we maximize the mutual information among graphs of the same class in the downstream classification tasks, preserving invariant features for prediction to a great extent. An appealing feature of InfoIGL is its strong generalization ability without depending on supervised signal of invariance. Experiments on both synthetic and real-world datasets demonstrate that our method achieves state-of-the-art performance under OOD generalization for graph classification tasks. The source code is available at https://github.com/maowenyu-11/InfoIGL.
Dynamic Sparse Learning: A Novel Paradigm for Efficient Recommendation
Feb 05, 2024In the realm of deep learning-based recommendation systems, the increasing computational demands, driven by the growing number of users and items, pose a significant challenge to practical deployment. This challenge is primarily twofold: reducing the model size while effectively learning user and item representations for efficient recommendations. Despite considerable advancements in model compression and architecture search, prevalent approaches face notable constraints. These include substantial additional computational costs from pre-training/re-training in model compression and an extensive search space in architecture design. Additionally, managing complexity and adhering to memory constraints is problematic, especially in scenarios with strict time or space limitations. Addressing these issues, this paper introduces a novel learning paradigm, Dynamic Sparse Learning (DSL), tailored for recommendation models. DSL innovatively trains a lightweight sparse model from scratch, periodically evaluating and dynamically adjusting each weight's significance and the model's sparsity distribution during the training. This approach ensures a consistent and minimal parameter budget throughout the full learning lifecycle, paving the way for "end-to-end" efficiency from training to inference. Our extensive experimental results underline DSL's effectiveness, significantly reducing training and inference costs while delivering comparable recommendation performance.
EXGC: Bridging Efficiency and Explainability in Graph Condensation
Feb 05, 2024Graph representation learning on vast datasets, like web data, has made significant strides. However, the associated computational and storage overheads raise concerns. In sight of this, Graph condensation (GCond) has been introduced to distill these large real datasets into a more concise yet information-rich synthetic graph. Despite acceleration efforts, existing GCond methods mainly grapple with efficiency, especially on expansive web data graphs. Hence, in this work, we pinpoint two major inefficiencies of current paradigms: (1) the concurrent updating of a vast parameter set, and (2) pronounced parameter redundancy. To counteract these two limitations correspondingly, we first (1) employ the Mean-Field variational approximation for convergence acceleration, and then (2) propose the objective of Gradient Information Bottleneck (GDIB) to prune redundancy. By incorporating the leading explanation techniques (e.g., GNNExplainer and GSAT) to instantiate the GDIB, our EXGC, the Efficient and eXplainable Graph Condensation method is proposed, which can markedly boost efficiency and inject explainability. Our extensive evaluations across eight datasets underscore EXGC's superiority and relevance. Code is available at https://github.com/MangoKiller/EXGC.
Two Heads Are Better Than One: Boosting Graph Sparse Training via Semantic and Topological Awareness
Feb 02, 2024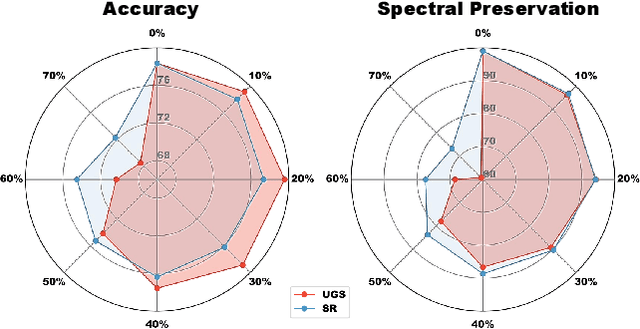
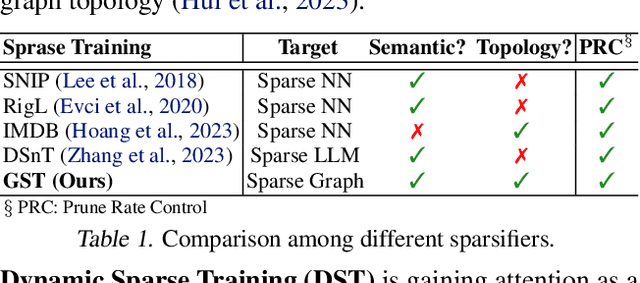
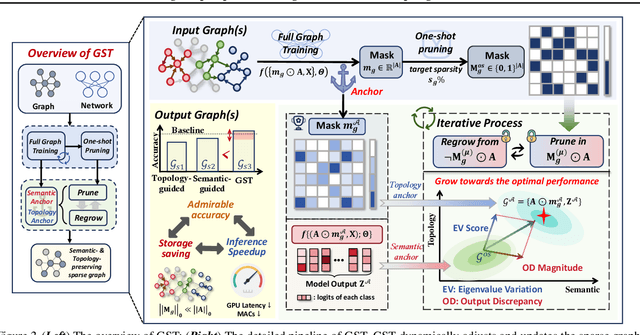
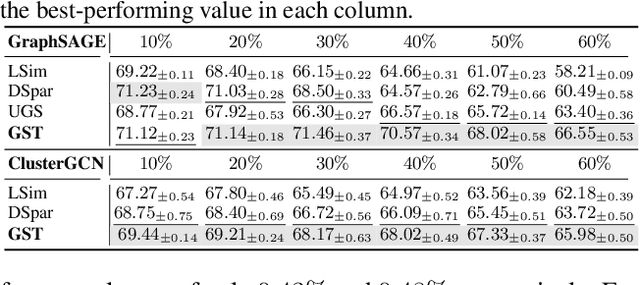
Graph Neural Networks (GNNs) excel in various graph learning tasks but face computational challenges when applied to large-scale graphs. A promising solution is to remove non-essential edges to reduce the computational overheads in GNN. Previous literature generally falls into two categories: topology-guided and semantic-guided. The former maintains certain graph topological properties yet often underperforms on GNNs due to low integration with neural network training. The latter performs well at lower sparsity on GNNs but faces performance collapse at higher sparsity levels. With this in mind, we take the first step to propose a new research line and concept termed Graph Sparse Training (GST), which dynamically manipulates sparsity at the data level. Specifically, GST initially constructs a topology & semantic anchor at a low training cost, followed by performing dynamic sparse training to align the sparse graph with the anchor. We introduce the Equilibria Sparsification Principle to guide this process, effectively balancing the preservation of both topological and semantic information. Ultimately, GST produces a sparse graph with maximum topological integrity and no performance degradation. Extensive experiments on 6 datasets and 5 backbones showcase that GST (I) identifies subgraphs at higher graph sparsity levels (1.67%~15.85% $\uparrow$) than state-of-the-art sparsification methods, (II) preserves more key spectral properties, (III) achieves 1.27-3.42$\times$ speedup in GNN inference and (IV) successfully helps graph adversarial defense and graph lottery tickets.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
GIF: A General Graph Unlearning Strategy via Influence Function
Apr 06, 2023With the greater emphasis on privacy and security in our society, the problem of graph unlearning -- revoking the influence of specific data on the trained GNN model, is drawing increasing attention. However, ranging from machine unlearning to recently emerged graph unlearning methods, existing efforts either resort to retraining paradigm, or perform approximate erasure that fails to consider the inter-dependency between connected neighbors or imposes constraints on GNN structure, therefore hard to achieve satisfying performance-complexity trade-offs. In this work, we explore the influence function tailored for graph unlearning, so as to improve the unlearning efficacy and efficiency for graph unlearning. We first present a unified problem formulation of diverse graph unlearning tasks \wrt node, edge, and feature. Then, we recognize the crux to the inability of traditional influence function for graph unlearning, and devise Graph Influence Function (GIF), a model-agnostic unlearning method that can efficiently and accurately estimate parameter changes in response to a $\epsilon$-mass perturbation in deleted data. The idea is to supplement the objective of the traditional influence function with an additional loss term of the influenced neighbors due to the structural dependency. Further deductions on the closed-form solution of parameter changes provide a better understanding of the unlearning mechanism. We conduct extensive experiments on four representative GNN models and three benchmark datasets to justify the superiority of GIF for diverse graph unlearning tasks in terms of unlearning efficacy, model utility, and unlearning efficiency. Our implementations are available at \url{https://github.com/wujcan/GIF-torch/}.
Adversarial Causal Augmentation for Graph Covariate Shift
Nov 05, 2022Out-of-distribution (OOD) generalization on graphs is drawing widespread attention. However, existing efforts mainly focus on the OOD issue of correlation shift. While another type, covariate shift, remains largely unexplored but is the focus of this work. From a data generation view, causal features are stable substructures in data, which play key roles in OOD generalization. While their complementary parts, environments, are unstable features that often lead to various distribution shifts. Correlation shift establishes spurious statistical correlations between environments and labels. In contrast, covariate shift means that there exist unseen environmental features in test data. Existing strategies of graph invariant learning and data augmentation suffer from limited environments or unstable causal features, which greatly limits their generalization ability on covariate shift. In view of that, we propose a novel graph augmentation strategy: Adversarial Causal Augmentation (AdvCA), to alleviate the covariate shift. Specifically, it adversarially augments the data to explore diverse distributions of the environments. Meanwhile, it keeps the causal features invariant across diverse environments. It maintains the environmental diversity while ensuring the invariance of the causal features, thereby effectively alleviating the covariate shift. Extensive experimental results with in-depth analyses demonstrate that AdvCA can outperform 14 baselines on synthetic and real-world datasets with various covariate shifts.
Deconfounded Training for Graph Neural Networks
Dec 30, 2021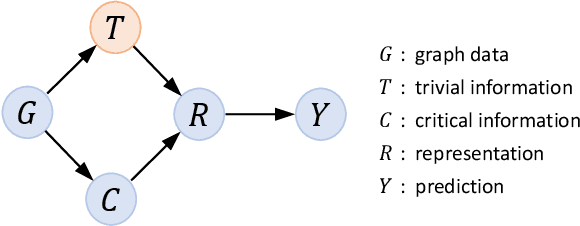
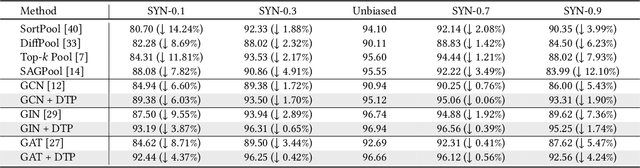
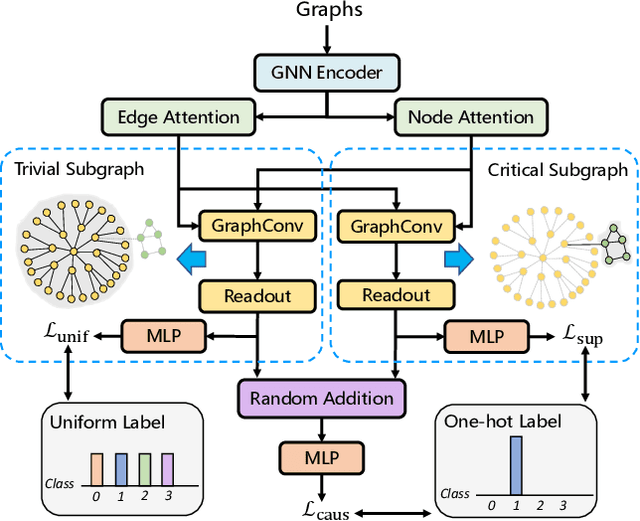
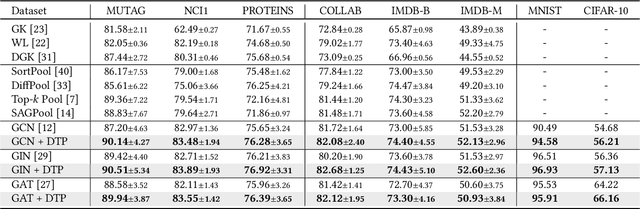
Learning powerful representations is one central theme of graph neural networks (GNNs). It requires refining the critical information from the input graph, instead of the trivial patterns, to enrich the representations. Towards this end, graph attention and pooling methods prevail. They mostly follow the paradigm of "learning to attend". It maximizes the mutual information between the attended subgraph and the ground-truth label. However, this training paradigm is prone to capture the spurious correlations between the trivial subgraph and the label. Such spurious correlations are beneficial to in-distribution (ID) test evaluations, but cause poor generalization in the out-of-distribution (OOD) test data. In this work, we revisit the GNN modeling from the causal perspective. On the top of our causal assumption, the trivial information serves as a confounder between the critical information and the label, which opens a backdoor path between them and makes them spuriously correlated. Hence, we present a new paradigm of deconfounded training (DTP) that better mitigates the confounding effect and latches on the critical information, to enhance the representation and generalization ability. Specifically, we adopt the attention modules to disentangle the critical subgraph and trivial subgraph. Then we make each critical subgraph fairly interact with diverse trivial subgraphs to achieve a stable prediction. It allows GNNs to capture a more reliable subgraph whose relation with the label is robust across different distributions. We conduct extensive experiments on synthetic and real-world datasets to demonstrate the effectiveness.
Exploring Lottery Ticket Hypothesis in Media Recommender Systems
Aug 02, 2021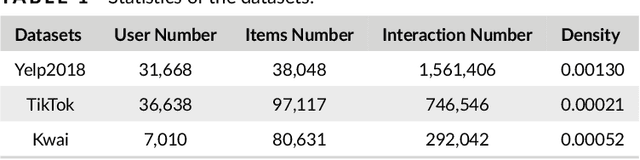
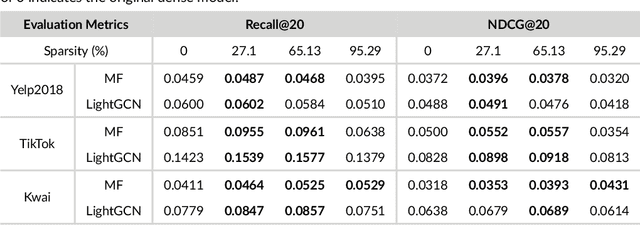
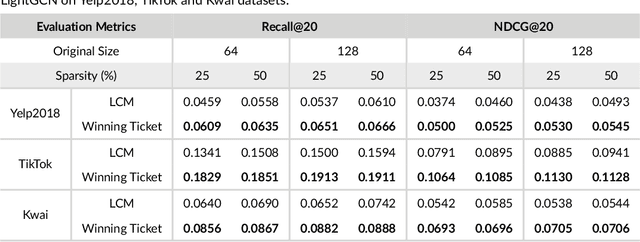
Media recommender systems aim to capture users' preferences and provide precise personalized recommendation of media content. There are two critical components in the common paradigm of modern recommender models: (1) representation learning, which generates an embedding for each user and item; and (2) interaction modeling, which fits user preferences towards items based on their representations. Despite of great success, when a great amount of users and items exist, it usually needs to create, store, and optimize a huge embedding table, where the scale of model parameters easily reach millions or even larger. Hence, it naturally raises questions about the heavy recommender models: Do we really need such large-scale parameters? We get inspirations from the recently proposed lottery ticket hypothesis (LTH), which argues that the dense and over-parameterized model contains a much smaller and sparser sub-model that can reach comparable performance to the full model. In this paper, we extend LTH to media recommender systems, aiming to find the winning tickets in deep recommender models. To the best of our knowledge, this is the first work to study LTH in media recommender systems. With MF and LightGCN as the backbone models, we found that there widely exist winning tickets in recommender models. On three media convergence datasets -- Yelp2018, TikTok and Kwai, the winning tickets can achieve comparable recommendation performance with only 29%~48%, 7%~10% and 3%~17% of parameters, respectively.