 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Lottery Ticket Hypothesis in Media Recommender Systems
Paper and Code
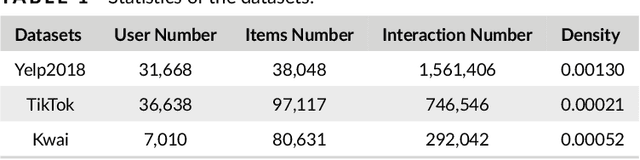
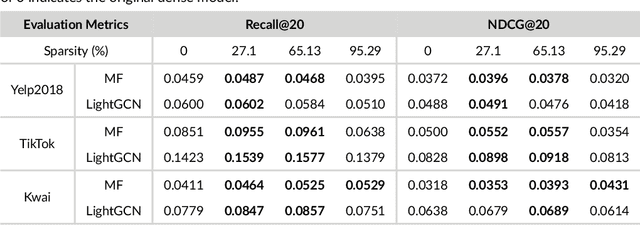
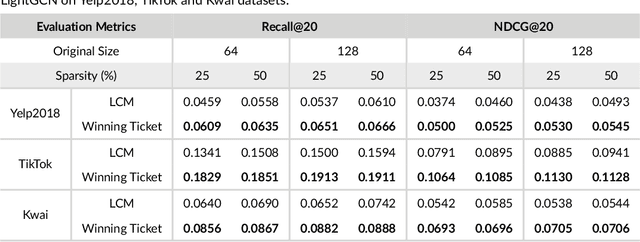
Media recommender systems aim to capture users' preferences and provide precise personalized recommendation of media content. There are two critical components in the common paradigm of modern recommender models: (1) representation learning, which generates an embedding for each user and item; and (2) interaction modeling, which fits user preferences towards items based on their representations. Despite of great success, when a great amount of users and items exist, it usually needs to create, store, and optimize a huge embedding table, where the scale of model parameters easily reach millions or even larger. Hence, it naturally raises questions about the heavy recommender models: Do we really need such large-scale parameters? We get inspirations from the recently proposed lottery ticket hypothesis (LTH), which argues that the dense and over-parameterized model contains a much smaller and sparser sub-model that can reach comparable performance to the full model. In this paper, we extend LTH to media recommender systems, aiming to find the winning tickets in deep recommender models. To the best of our knowledge, this is the first work to study LTH in media recommender systems. With MF and LightGCN as the backbone models, we found that there widely exist winning tickets in recommender models. On three media convergence datasets -- Yelp2018, TikTok and Kwai, the winning tickets can achieve comparable recommendation performance with only 29%~48%, 7%~10% and 3%~17% of parameters, respectively.