 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconfounded Training for Graph Neural Networks
Paper and Code
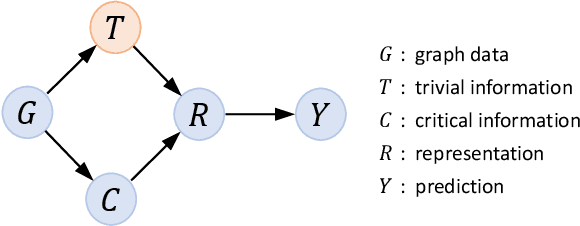
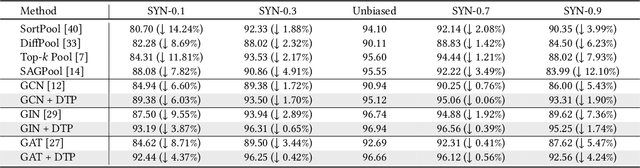
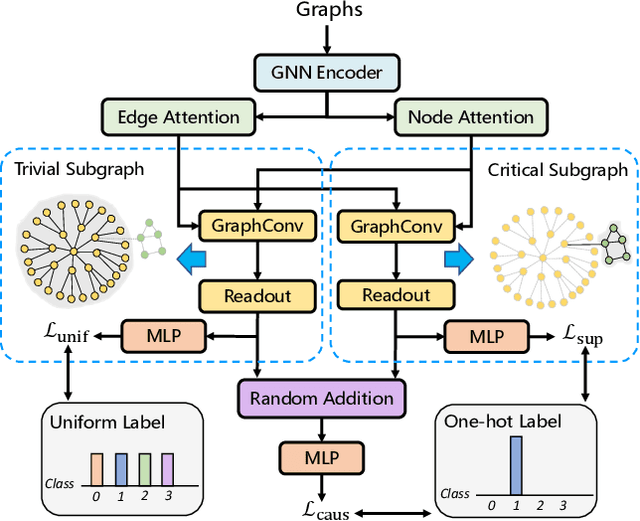
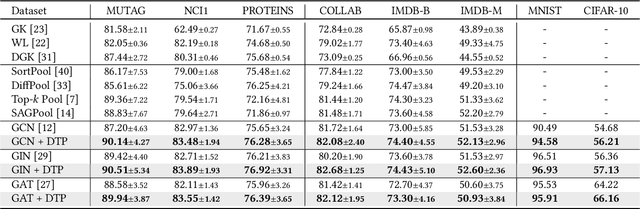
Learning powerful representations is one central theme of graph neural networks (GNNs). It requires refining the critical information from the input graph, instead of the trivial patterns, to enrich the representations. Towards this end, graph attention and pooling methods prevail. They mostly follow the paradigm of "learning to attend". It maximizes the mutual information between the attended subgraph and the ground-truth label. However, this training paradigm is prone to capture the spurious correlations between the trivial subgraph and the label. Such spurious correlations are beneficial to in-distribution (ID) test evaluations, but cause poor generalization in the out-of-distribution (OOD) test data. In this work, we revisit the GNN modeling from the causal perspective. On the top of our causal assumption, the trivial information serves as a confounder between the critical information and the label, which opens a backdoor path between them and makes them spuriously correlated. Hence, we present a new paradigm of deconfounded training (DTP) that better mitigates the confounding effect and latches on the critical information, to enhance the representation and generalization ability. Specifically, we adopt the attention modules to disentangle the critical subgraph and trivial subgraph. Then we make each critical subgraph fairly interact with diverse trivial subgraphs to achieve a stable prediction. It allows GNNs to capture a more reliable subgraph whose relation with the label is robust across different distributions. We conduct extensive experiments on synthetic and real-world datasets to demonstrate the effectiveness.