 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE4C: Enhance Editability for Text-Based Image Editing by Harnessing Efficient CLIP Guidance
Mar 15, 2024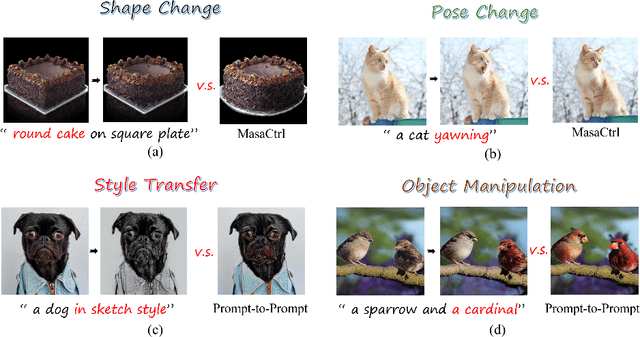
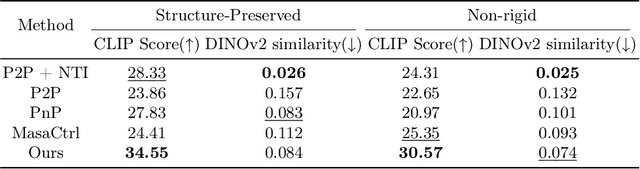
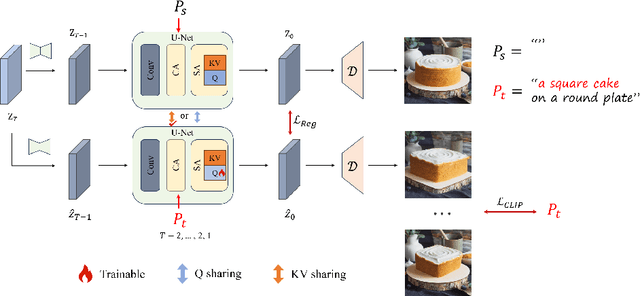

Diffusion-based image editing is a composite process of preserving the source image content and generating new content or applying modifications. While current editing approaches have made improvements under text guidance, most of them have only focused on preserving the information of the input image, disregarding the importance of editability and alignment to the target prompt. In this paper, we prioritize the editability by proposing a zero-shot image editing method, named \textbf{E}nhance \textbf{E}ditability for text-based image \textbf{E}diting via \textbf{E}fficient \textbf{C}LIP guidance (\textbf{E4C}), which only requires inference-stage optimization to explicitly enhance the edibility and text alignment. Specifically, we develop a unified dual-branch feature-sharing pipeline that enables the preservation of the structure or texture of the source image while allowing the other to be adapted based on the editing task. We further integrate CLIP guidance into our pipeline by utilizing our novel random-gateway optimization mechanism to efficiently enhance the semantic alignment with the target prompt. Comprehensive quantitative and qualitative experiments demonstrate that our method effectively resolves the text alignment issues prevalent in existing methods while maintaining the fidelity to the source image, and performs well across a wide range of editing tasks.
Faster Learning of Temporal Action Proposal via Sparse Multilevel Boundary Generator
Mar 06, 2023Temporal action localization in videos presents significant challenges in the field of computer vision. While the boundary-sensitive method has been widely adopted, its limitations include incomplete use of intermediate and global information, as well as an inefficient proposal feature generator. To address these challenges, we propose a novel framework, Sparse Multilevel Boundary Generator (SMBG), which enhances the boundary-sensitive method with boundary classification and action completeness regression. SMBG features a multi-level boundary module that enables faster processing by gathering boundary information at different lengths. Additionally, we introduce a sparse extraction confidence head that distinguishes information inside and outside the action, further optimizing the proposal feature generator. To improve the synergy between multiple branches and balance positive and negative samples, we propose a global guidance loss. Our method is evaluated on two popular benchmarks, ActivityNet-1.3 and THUMOS14, and is shown to achieve state-of-the-art performance, with a better inference speed (2.47xBSN++, 2.12xDBG). These results demonstrate that SMBG provides a more efficient and simple solution for generating temporal action proposals. Our proposed framework has the potential to advance the field of computer vision and enhance the accuracy and speed of temporal action localization in video analysis.The code and models are made available at \url{https://github.com/zhouyang-001/SMBG-for-temporal-action-proposal}.
UV R-CNN: Stable and Efficient Dense Human Pose Estimation
Nov 04, 2022Dense pose estimation is a dense 3D prediction task for instance-level human analysis, aiming to map human pixels from an RGB image to a 3D surface of the human body. Due to a large amount of surface point regression, the training process appears to be easy to collapse compared to other region-based human instance analyzing tasks. By analyzing the loss formulation of the existing dense pose estimation model, we introduce a novel point regression loss function, named Dense Points} loss to stable the training progress, and a new balanced loss weighting strategy to handle the multi-task losses. With the above novelties, we propose a brand new architecture, named UV R-CNN. Without auxiliary supervision and external knowledge from other tasks, UV R-CNN can handle many complicated issues in dense pose model training progress, achieving 65.0% $AP_{gps}$ and 66.1% $AP_{gpsm}$ on the DensePose-COCO validation subset with ResNet-50-FPN feature extractor, competitive among the state-of-the-art dense human pose estimation methods.
SGM-Net: Semantic Guided Matting Net
Aug 16, 2022
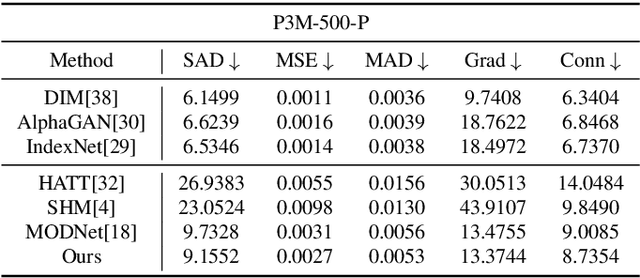
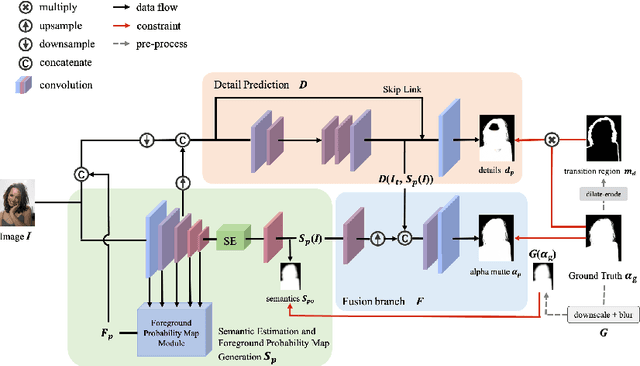
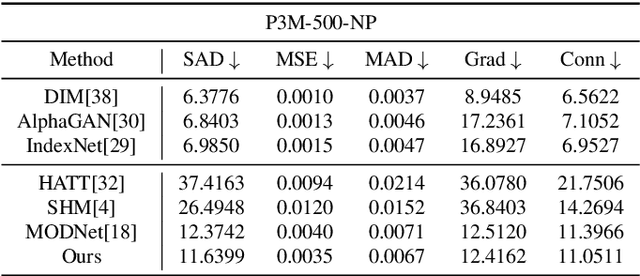
Human matting refers to extracting human parts from natural images with high quality, including human detail information such as hair, glasses, hat, etc. This technology plays an essential role in image synthesis and visual effects in the film industry. When the green screen is not available, the existing human matting methods need the help of additional inputs (such as trimap, background image, etc.), or the model with high computational cost and complex network structure, which brings great difficulties to the application of human matting in practice. To alleviate such problems, most existing methods (such as MODNet) use multi-branches to pave the way for matting through segmentation, but these methods do not make full use of the image features and only utilize the prediction results of the network as guidance information. Therefore, we propose a module to generate foreground probability map and add it to MODNet to obtain Semantic Guided Matting Net (SGM-Net). Under the condition of only one image, we can realize the human matting task. We verify our method on the P3M-10k dataset. Compared with the benchmark, our method has significantly improved in various evaluation indicators.
Renovating Parsing R-CNN for Accurate Multiple Human Parsing
Sep 20, 2020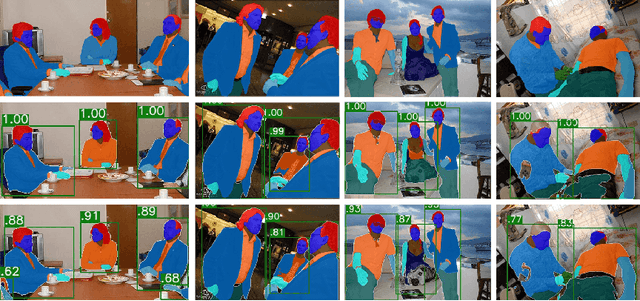

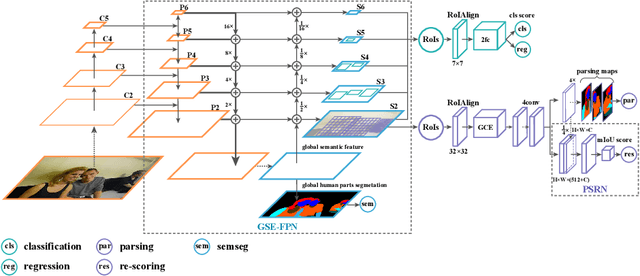
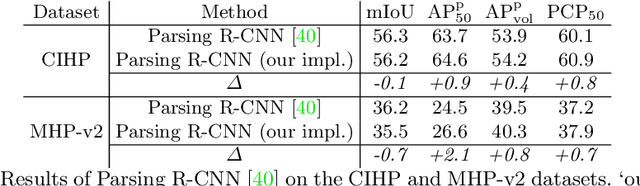
Multiple human parsing aims to segment various human parts and associate each part with the corresponding instance simultaneously. This is a very challenging task due to the diverse human appearance, semantic ambiguity of different body parts, and complex background. Through analysis of multiple human parsing task, we observe that human-centric global perception and accurate instance-level parsing scoring are crucial for obtaining high-quality results. But the most state-of-the-art methods have not paid enough attention to these issues. To reverse this phenomenon, we present Renovating Parsing R-CNN (RP R-CNN), which introduces a global semantic enhanced feature pyramid network and a parsing re-scoring network into the existing high-performance pipeline. The proposed RP R-CNN adopts global semantic representation to enhance multi-scale features for generating human parsing maps, and regresses a confidence score to represent its quality. Extensive experiments show that RP R-CNN performs favorably against state-of-the-art methods on CIHP and MHP-v2 datasets. Code and models are available at https://github.com/soeaver/RP-R-CNN.
CPM R-CNN: Calibrating Point-guided Misalignment in Object Detection
Mar 07, 2020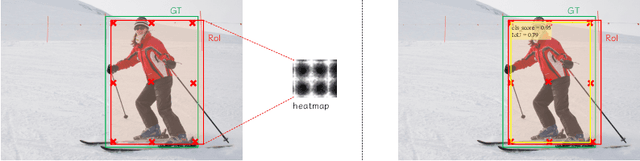

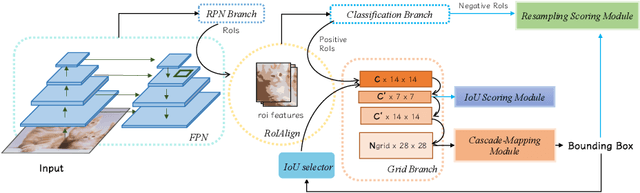
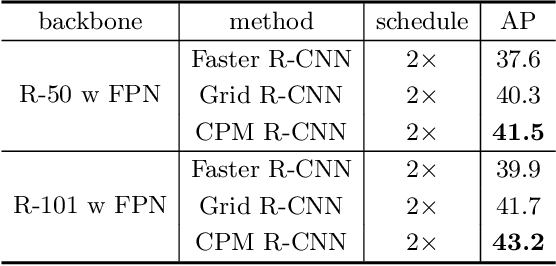
In object detection, offset-guided and point-guided regression dominate anchor-based and anchor-free method separately. Recently, point-guided approach is introduced to anchor-based method. However, we observe points predicted by this way are misaligned with matched region of proposals and score of localization, causing a notable gap in performance. In this paper, we propose CPM R-CNN which contains three efficient modules to optimize anchor-based point-guided method. According to sufficient evaluations on the COCO dataset, CPM R-CNN is demonstrated efficient to improve the localization accuracy by calibrating mentioned misalignment. Compared with Faster R-CNN and Grid R-CNN based on ResNet-101 with FPN, our approach can substantially improve detection mAP by 3.3% and 1.5% respectively without whistles and bells. Moreover, our best model achieves improvement by a large margin to 49.9% on COCO test-dev. Code and models will be publicly available.
High-speed Railway Fastener Detection and Localization Method based on convolutional neural network
Jul 31, 2019



Railway transportation is the artery of China's national economy and plays an important role in the development of today's society. Due to the late start of China's railway security inspection technology, the current railway security inspection tasks mainly rely on manual inspection, but the manual inspection efficiency is low, and a lot of manpower and material resources are needed. In this paper, we establish a steel rail fastener detection image dataset, which contains 4,000 rail fastener pictures about 4 types. We use the regional suggestion network to generate the region of interest, extracts the features using the convolutional neural network, and fuses the classifier into the detection network. With online hard sample mining to improve the accuracy of the model, we optimize the Faster RCNN detection framework by reducing the number of regions of interest. Finally, the model accuracy reaches 99% and the speed reaches 35FPS in the deployment environment of TITAN X GPU.