 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGM-Net: Semantic Guided Matting Net
Aug 16, 2022
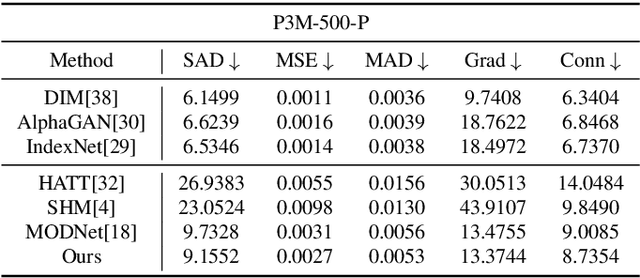
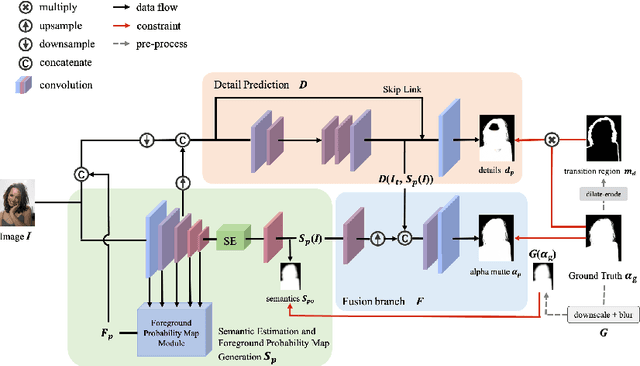
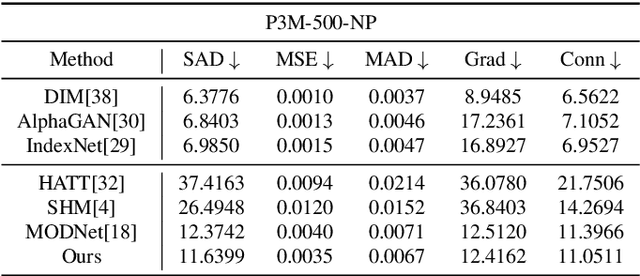
Human matting refers to extracting human parts from natural images with high quality, including human detail information such as hair, glasses, hat, etc. This technology plays an essential role in image synthesis and visual effects in the film industry. When the green screen is not available, the existing human matting methods need the help of additional inputs (such as trimap, background image, etc.), or the model with high computational cost and complex network structure, which brings great difficulties to the application of human matting in practice. To alleviate such problems, most existing methods (such as MODNet) use multi-branches to pave the way for matting through segmentation, but these methods do not make full use of the image features and only utilize the prediction results of the network as guidance information. Therefore, we propose a module to generate foreground probability map and add it to MODNet to obtain Semantic Guided Matting Net (SGM-Net). Under the condition of only one image, we can realize the human matting task. We verify our method on the P3M-10k dataset. Compared with the benchmark, our method has significantly improved in various evaluation indicators.