 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemBLIP: Efficient Bootstrapping of Multilingual Vision-LLMs
Jul 13, 2023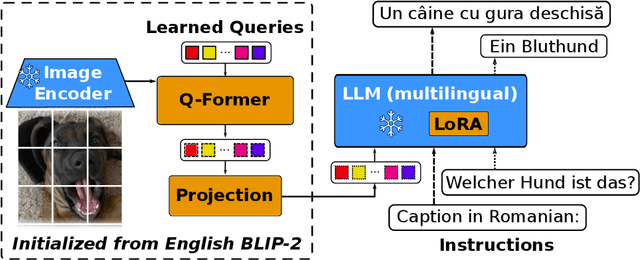
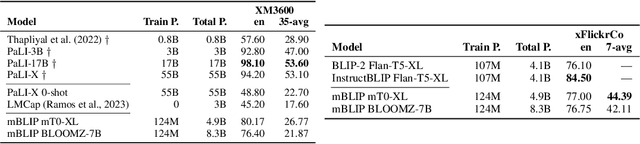
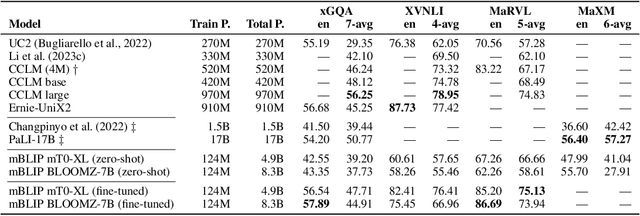
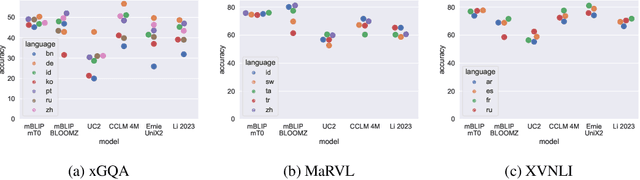
Modular vision-language models (Vision-LLMs) align pretrained image encoders with (pretrained) large language models (LLMs), representing a computationally much more efficient alternative to end-to-end training of large vision-language models from scratch, which is prohibitively expensive for most. Vision-LLMs instead post-hoc condition LLMs to `understand' the output of an image encoder. With the abundance of readily available high-quality English image-text data as well as monolingual English LLMs, the research focus has been on English-only Vision-LLMs. Multilingual vision-language models are still predominantly obtained via expensive end-to-end pretraining, resulting in comparatively smaller models, trained on limited multilingual image data supplemented with text-only multilingual corpora. In this work, we present mBLIP, the first multilingual Vision-LLM, which we obtain in a computationally efficient manner -- on consumer hardware using only a few million training examples -- by leveraging a pretrained multilingual LLM. To this end, we \textit{re-align} an image encoder previously tuned to an English LLM to a new, multilingual LLM -- for this, we leverage multilingual data from a mix of vision-and-language tasks, which we obtain by machine-translating high-quality English data to 95 languages. On the IGLUE benchmark, mBLIP yields results competitive with state-of-the-art models. Moreover, in image captioning on XM3600, mBLIP (zero-shot) even outperforms PaLI-X (a model with 55B parameters). Compared to these very large multilingual vision-language models trained from scratch, we obtain mBLIP by training orders of magnitude fewer parameters on magnitudes less data. We release our model and code at \url{https://github.com/gregor-ge/mBLIP}.