 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Information Matters: A Rethink of Crowd Counting
Aug 23, 2025The motivation of this paper originates from rethinking an essential characteristic of crowd counting: individuals (heads of humans) in the crowd counting task typically occupy a very small portion of the image. This characteristic has never been the focus of existing works: they typically use the same backbone as other visual tasks and pursue a large receptive field. This drives us to propose a new model design principle of crowd counting: emphasizing local modeling capability of the model. We follow the principle and design a crowd counting model named Local Information Matters Model (LIMM). The main innovation lies in two strategies: a window partitioning design that applies grid windows to the model input, and a window-wise contrastive learning design to enhance the model's ability to distinguish between local density levels. Moreover, a global attention module is applied to the end of the model to handle the occasionally occurring large-sized individuals. Extensive experiments on multiple public datasets illustrate that the proposed model shows a significant improvement in local modeling capability (8.7\% in MAE on the JHU-Crowd++ high-density subset for example), without compromising its ability to count large-sized ones, which achieves state-of-the-art performance. Code is available at: https://github.com/tianhangpan/LIMM.
Distribution-aware Dataset Distillation for Efficient Image Restoration
Apr 21, 2025With the exponential increase in image data, training an image restoration model is laborious. Dataset distillation is a potential solution to this problem, yet current distillation techniques are a blank canvas in the field of image restoration. To fill this gap, we propose the Distribution-aware Dataset Distillation method (TripleD), a new framework that extends the principles of dataset distillation to image restoration. Specifically, TripleD uses a pre-trained vision Transformer to extract features from images for complexity evaluation, and the subset (the number of samples is much smaller than the original training set) is selected based on complexity. The selected subset is then fed through a lightweight CNN that fine-tunes the image distribution to align with the distribution of the original dataset at the feature level. To efficiently condense knowledge, the training is divided into two stages. Early stages focus on simpler, low-complexity samples to build foundational knowledge, while later stages select more complex and uncertain samples as the model matures. Our method achieves promising performance on multiple image restoration tasks, including multi-task image restoration, all-in-one image restoration, and ultra-high-definition image restoration tasks. Note that we can train a state-of-the-art image restoration model on an ultra-high-definition (4K resolution) dataset using only one consumer-grade GPU in less than 8 hours (500 savings in computing resources and immeasurable training time).
Boosting Adverse Weather Crowd Counting via Multi-queue Contrastive Learning
Aug 12, 2024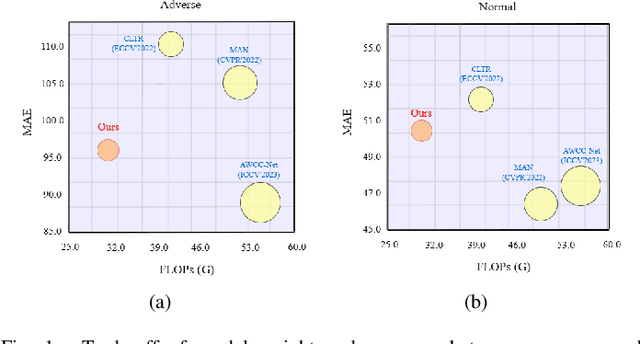
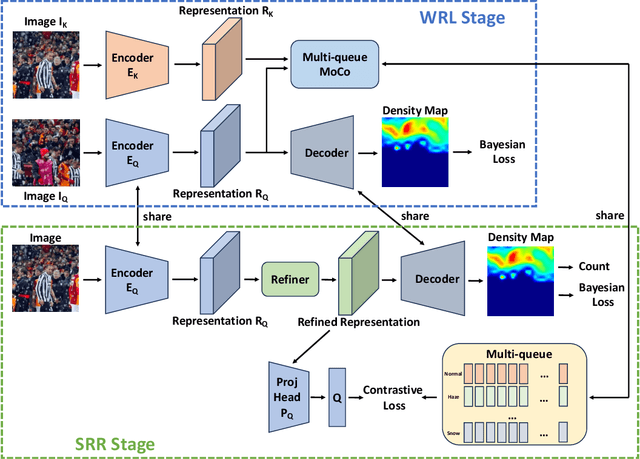
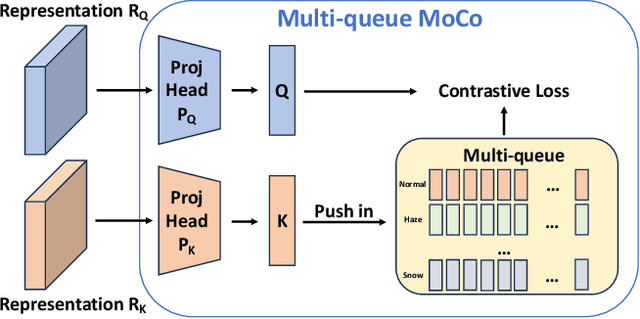

Currently, most crowd counting methods have outstanding performance under normal weather conditions. However, they often struggle to maintain their performance in extreme and adverse weather conditions due to significant differences in the domain and a lack of adverse weather images for training. To address this issue and enhance the model's robustness in adverse weather, we propose a two-stage crowd counting method. Specifically, in the first stage, we introduce a multi-queue MoCo contrastive learning strategy to tackle the problem of weather class imbalance. This strategy facilitates the learning of weather-aware representations by the model. In the second stage, we propose to refine the representations under the guidance of contrastive learning, enabling the conversion of the weather-aware representations to the normal weather domain. While significantly improving the robustness, our method only marginally increases the weight of the model. In addition, we also create a new synthetic adverse weather dataset. Extensive experimental results show that our method achieves competitive performance.
Polyp-DAM: Polyp segmentation via depth anything model
Feb 03, 2024



Recently, large models (Segment Anything model) came on the scene to provide a new baseline for polyp segmentation tasks. This demonstrates that large models with a sufficient image level prior can achieve promising performance on a given task. In this paper, we unfold a new perspective on polyp segmentation modeling by leveraging the Depth Anything Model (DAM) to provide depth prior to polyp segmentation models. Specifically, the input polyp image is first passed through a frozen DAM to generate a depth map. The depth map and the input polyp images are then concatenated and fed into a convolutional neural network with multiscale to generate segmented images. Extensive experimental results demonstrate the effectiveness of our method, and in addition, we observe that our method still performs well on images of polyps with noise. The URL of our code is \url{https://github.com/zzr-idam/Polyp-DAM}.
MixNet: Towards Effective and Efficient UHD Low-Light Image Enhancement
Jan 19, 2024



With the continuous advancement of imaging devices, the prevalence of Ultra-High-Definition (UHD) images is rising. Although many image restoration methods have achieved promising results, they are not directly applicable to UHD images on devices with limited computational resources due to the inherently high computational complexity of UHD images. In this paper, we focus on the task of low-light image enhancement (LLIE) and propose a novel LLIE method called MixNet, which is designed explicitly for UHD images. To capture the long-range dependency of features without introducing excessive computational complexity, we present the Global Feature Modulation Layer (GFML). GFML associates features from different views by permuting the feature maps, enabling efficient modeling of long-range dependency. In addition, we also design the Local Feature Modulation Layer (LFML) and Feed-forward Layer (FFL) to capture local features and transform features into a compact representation. This way, our MixNet achieves effective LLIE with few model parameters and low computational complexity. We conducted extensive experiments on both synthetic and real-world datasets, and the comprehensive results demonstrate that our proposed method surpasses the performance of current state-of-the-art methods. The code will be available at \url{https://github.com/zzr-idam/MixNet}.
Joint Projection Learning and Tensor Decomposition Based Incomplete Multi-view Clustering
Oct 06, 2023



Incomplete multi-view clustering (IMVC) has received increasing attention since it is often that some views of samples are incomplete in reality. Most existing methods learn similarity subgraphs from original incomplete multi-view data and seek complete graphs by exploring the incomplete subgraphs of each view for spectral clustering. However, the graphs constructed on the original high-dimensional data may be suboptimal due to feature redundancy and noise. Besides, previous methods generally ignored the graph noise caused by the inter-class and intra-class structure variation during the transformation of incomplete graphs and complete graphs. To address these problems, we propose a novel Joint Projection Learning and Tensor Decomposition Based method (JPLTD) for IMVC. Specifically, to alleviate the influence of redundant features and noise in high-dimensional data, JPLTD introduces an orthogonal projection matrix to project the high-dimensional features into a lower-dimensional space for compact feature learning.Meanwhile, based on the lower-dimensional space, the similarity graphs corresponding to instances of different views are learned, and JPLTD stacks these graphs into a third-order low-rank tensor to explore the high-order correlations across different views. We further consider the graph noise of projected data caused by missing samples and use a tensor-decomposition based graph filter for robust clustering.JPLTD decomposes the original tensor into an intrinsic tensor and a sparse tensor. The intrinsic tensor models the true data similarities. An effective optimization algorithm is adopted to solve the JPLTD model. Comprehensive experiments on several benchmark datasets demonstrate that JPLTD outperforms the state-of-the-art methods. The code of JPLTD is available at https://github.com/weilvNJU/JPLTD.
Complex Mixer for MedMNIST Classification Decathlon
Apr 20, 2023With the development of the medical image field, researchers seek to develop a class of datasets to block the need for medical knowledge, such as \text{MedMNIST} (v2). MedMNIST (v2) includes a large number of small-sized (28 $\times$ 28 or 28 $\times$ 28 $\times$ 28) medical samples and the corresponding expert annotations (class label). The existing baseline model (Google AutoML Vision, ResNet-50+3D) can reach an average accuracy of over 70\% on MedMNIST (v2) datasets, which is comparable to the performance of expert decision-making. Nevertheless, we note that there are two insurmountable obstacles to modeling on MedMNIST (v2): 1) the raw images are cropped to low scales may cause effective recognition information to be dropped and the classifier to have difficulty in tracing accurate decision boundaries; 2) the labelers' subjective insight may cause many uncertainties in the label space. To address these issues, we develop a Complex Mixer (C-Mixer) with a pre-training framework to alleviate the problem of insufficient information and uncertainty in the label space by introducing an incentive imaginary matrix and a self-supervised scheme with random masking. Our method (incentive learning and self-supervised learning with masking) shows surprising potential on both the standard MedMNIST (v2) dataset, the customized weakly supervised datasets, and other image enhancement tasks.
4K-HAZE: A Dehazing Benchmark with 4K Resolution Hazy and Haze-Free Images
Mar 28, 2023Currently, mobile and IoT devices are in dire need of a series of methods to enhance 4K images with limited resource expenditure. The absence of large-scale 4K benchmark datasets hampers progress in this area, especially for dehazing. The challenges in building ultra-high-definition (UHD) dehazing datasets are the absence of estimation methods for UHD depth maps, high-quality 4K depth estimation datasets, and migration strategies for UHD haze images from synthetic to real domains. To address these problems, we develop a novel synthetic method to simulate 4K hazy images (including nighttime and daytime scenes) from clear images, which first estimates the scene depth, simulates the light rays and object reflectance, then migrates the synthetic images to real domains by using a GAN, and finally yields the hazy effects on 4K resolution images. We wrap these synthesized images into a benchmark called the 4K-HAZE dataset. Specifically, we design the CS-Mixer (an MLP-based model that integrates \textbf{C}hannel domain and \textbf{S}patial domain) to estimate the depth map of 4K clear images, the GU-Net to migrate a 4K synthetic image to the real hazy domain. The most appealing aspect of our approach (depth estimation and domain migration) is the capability to run a 4K image on a single GPU with 24G RAM in real-time (33fps). Additionally, this work presents an objective assessment of several state-of-the-art single-image dehazing methods that are evaluated using the 4K-HAZE dataset. At the end of the paper, we discuss the limitations of the 4K-HAZE dataset and its social implications.
TabMixer: Excavating Label Distribution Learning with Small-scale Features
Oct 25, 2022Label distribution learning (LDL) differs from multi-label learning which aims at representing the polysemy of instances by transforming single-label values into descriptive degrees. Unfortunately, the feature space of the label distribution dataset is affected by human factors and the inductive bias of the feature extractor causing uncertainty in the feature space. Especially, for datasets with small-scale feature spaces (the feature space dimension $\approx$ the label space), the existing LDL algorithms do not perform well. To address this issue, we seek to model the uncertainty augmentation of the feature space to alleviate the problem in LDL tasks. Specifically, we start with augmenting each feature value in the feature vector of a sample into a vector (sampling on a Gaussian distribution function). Which, the variance parameter of the Gaussian distribution function is learned by using a sub-network, and the mean parameter is filled by this feature value. Then, each feature vector is augmented to a matrix which is fed into a mixer with local attention (\textit{TabMixer}) to extract the latent feature. Finally, the latent feature is squeezed to yield an accurate label distribution via a squeezed network. Extensive experiments verify that our proposed algorithm can be competitive compared to other LDL algorithms on several benchmarks.
Label distribution learning via label correlation grid
Oct 15, 2022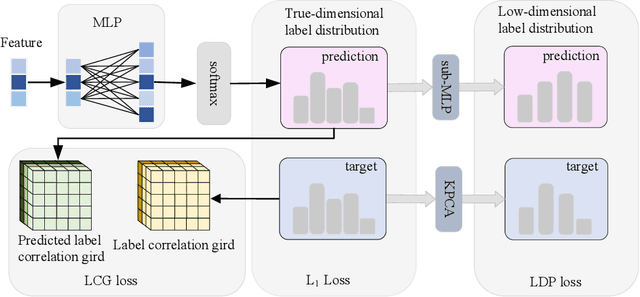
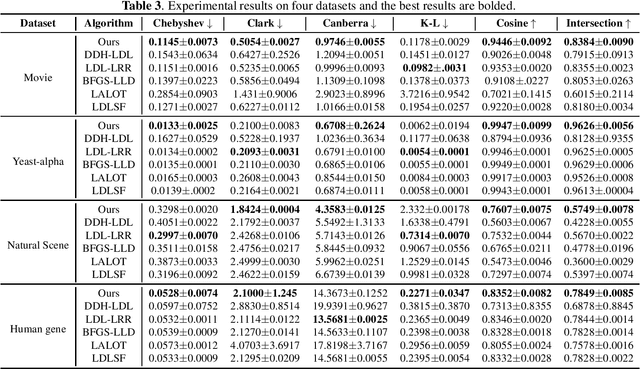
Label distribution learning can characterize the polysemy of an instance through label distributions. However, some noise and uncertainty may be introduced into the label space when processing label distribution data due to artificial or environmental factors. To alleviate this problem, we propose a \textbf{L}abel \textbf{C}orrelation \textbf{G}rid (LCG) to model the uncertainty of label relationships. Specifically, we compute a covariance matrix for the label space in the training set to represent the relationships between labels, then model the information distribution (Gaussian distribution function) for each element in the covariance matrix to obtain an LCG. Finally, our network learns the LCG to accurately estimate the label distribution for each instance. In addition, we propose a label distribution projection algorithm as a regularization term in the model training process. Extensive experiments verify the effectiveness of our method on several real benchmarks.