 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBD-Merging: Bias-Aware Dynamic Model Merging with Evidence-Guided Contrastive Learning
Mar 04, 2026Model Merging (MM) has emerged as a scalable paradigm for multi-task learning (MTL), enabling multiple task-specific models to be integrated without revisiting the original training data. Despite recent progress, the reliability of MM under test-time distribution shift remains insufficiently understood. Most existing MM methods typically assume that test data are clean and distributionally aligned with both the training and auxiliary sources. However, this assumption rarely holds in practice, often resulting in biased predictions with degraded generalization. To address this issue, we present BD-Merging, a bias-aware unsupervised model merging framework that explicitly models uncertainty to achieve adaptive reliability under distribution shift. First, BD-Merging introduces a joint evidential head that learns uncertainty over a unified label space, capturing cross-task semantic dependencies in MM. Second, building upon this evidential foundation, we propose an Adjacency Discrepancy Score (ADS) that quantifies evidential alignment among neighboring samples. Third, guided by ADS, a discrepancy-aware contrastive learning mechanism refines the merged representation by aligning consistent samples and separating conflicting ones. Combined with general unsupervised learning, this process trains a debiased router that adaptively allocates task-specific or layer-specific weights on a per-sample basis, effectively mitigating the adverse effects of distribution shift. Extensive experiments across diverse tasks demonstrate that BD-Merging achieves superior effectiveness and robustness compared to state-of-the-art MM baselines.
HealSplit: Towards Self-Healing through Adversarial Distillation in Split Federated Learning
Nov 14, 2025Split Federated Learning (SFL) is an emerging paradigm for privacy-preserving distributed learning. However, it remains vulnerable to sophisticated data poisoning attacks targeting local features, labels, smashed data, and model weights. Existing defenses, primarily adapted from traditional Federated Learning (FL), are less effective under SFL due to limited access to complete model updates. This paper presents HealSplit, the first unified defense framework tailored for SFL, offering end-to-end detection and recovery against five sophisticated types of poisoning attacks. HealSplit comprises three key components: (1) a topology-aware detection module that constructs graphs over smashed data to identify poisoned samples via topological anomaly scoring (TAS); (2) a generative recovery pipeline that synthesizes semantically consistent substitutes for detected anomalies, validated by a consistency validation student; and (3) an adversarial multi-teacher distillation framework trains the student using semantic supervision from a Vanilla Teacher and anomaly-aware signals from an Anomaly-Influence Debiasing (AD) Teacher, guided by the alignment between topological and gradient-based interaction matrices. Extensive experiments on four benchmark datasets demonstrate that HealSplit consistently outperforms ten state-of-the-art defenses, achieving superior robustness and defense effectiveness across diverse attack scenarios.
AdaQual-Diff: Diffusion-Based Image Restoration via Adaptive Quality Prompting
Apr 17, 2025Restoring images afflicted by complex real-world degradations remains challenging, as conventional methods often fail to adapt to the unique mixture and severity of artifacts present. This stems from a reliance on indirect cues which poorly capture the true perceptual quality deficit. To address this fundamental limitation, we introduce AdaQual-Diff, a diffusion-based framework that integrates perceptual quality assessment directly into the generative restoration process. Our approach establishes a mathematical relationship between regional quality scores from DeQAScore and optimal guidance complexity, implemented through an Adaptive Quality Prompting mechanism. This mechanism systematically modulates prompt structure according to measured degradation severity: regions with lower perceptual quality receive computationally intensive, structurally complex prompts with precise restoration directives, while higher quality regions receive minimal prompts focused on preservation rather than intervention. The technical core of our method lies in the dynamic allocation of computational resources proportional to degradation severity, creating a spatially-varying guidance field that directs the diffusion process with mathematical precision. By combining this quality-guided approach with content-specific conditioning, our framework achieves fine-grained control over regional restoration intensity without requiring additional parameters or inference iterations. Experimental results demonstrate that AdaQual-Diff achieves visually superior restorations across diverse synthetic and real-world datasets.
SafeSpeech: A Comprehensive and Interactive Tool for Analysing Sexist and Abusive Language in Conversations
Mar 09, 2025Detecting toxic language including sexism, harassment and abusive behaviour, remains a critical challenge, particularly in its subtle and context-dependent forms. Existing approaches largely focus on isolated message-level classification, overlooking toxicity that emerges across conversational contexts. To promote and enable future research in this direction, we introduce SafeSpeech, a comprehensive platform for toxic content detection and analysis that bridges message-level and conversation-level insights. The platform integrates fine-tuned classifiers and large language models (LLMs) to enable multi-granularity detection, toxic-aware conversation summarization, and persona profiling. SafeSpeech also incorporates explainability mechanisms, such as perplexity gain analysis, to highlight the linguistic elements driving predictions. Evaluations on benchmark datasets, including EDOS, OffensEval, and HatEval, demonstrate the reproduction of state-of-the-art performance across multiple tasks, including fine-grained sexism detection.
SciGisPy: a Novel Metric for Biomedical Text Simplification via Gist Inference Score
Oct 12, 2024



Biomedical literature is often written in highly specialized language, posing significant comprehension challenges for non-experts. Automatic text simplification (ATS) offers a solution by making such texts more accessible while preserving critical information. However, evaluating ATS for biomedical texts is still challenging due to the limitations of existing evaluation metrics. General-domain metrics like SARI, BLEU, and ROUGE focus on surface-level text features, and readability metrics like FKGL and ARI fail to account for domain-specific terminology or assess how well the simplified text conveys core meanings (gist). To address this, we introduce SciGisPy, a novel evaluation metric inspired by Gist Inference Score (GIS) from Fuzzy-Trace Theory (FTT). SciGisPy measures how well a simplified text facilitates the formation of abstract inferences (gist) necessary for comprehension, especially in the biomedical domain. We revise GIS for this purpose by introducing domain-specific enhancements, including semantic chunking, Information Content (IC) theory, and specialized embeddings, while removing unsuitable indexes. Our experimental evaluation on the Cochrane biomedical text simplification dataset demonstrates that SciGisPy outperforms the original GIS formulation, with a significant increase in correctly identified simplified texts (84% versus 44.8%). The results and a thorough ablation study confirm that SciGisPy better captures the essential meaning of biomedical content, outperforming existing approaches.
Society of Medical Simplifiers
Oct 12, 2024



Medical text simplification is crucial for making complex biomedical literature more accessible to non-experts. Traditional methods struggle with the specialized terms and jargon of medical texts, lacking the flexibility to adapt the simplification process dynamically. In contrast, recent advancements in large language models (LLMs) present unique opportunities by offering enhanced control over text simplification through iterative refinement and collaboration between specialized agents. In this work, we introduce the Society of Medical Simplifiers, a novel LLM-based framework inspired by the "Society of Mind" (SOM) philosophy. Our approach leverages the strengths of LLMs by assigning five distinct roles, i.e., Layperson, Simplifier, Medical Expert, Language Clarifier, and Redundancy Checker, organized into interaction loops. This structure allows the agents to progressively improve text simplification while maintaining the complexity and accuracy of the original content. Evaluations on the Cochrane text simplification dataset demonstrate that our framework is on par with or outperforms state-of-the-art methods, achieving superior readability and content preservation through controlled simplification processes.
TACO: Topics in Algorithmic COde generation dataset
Dec 27, 2023
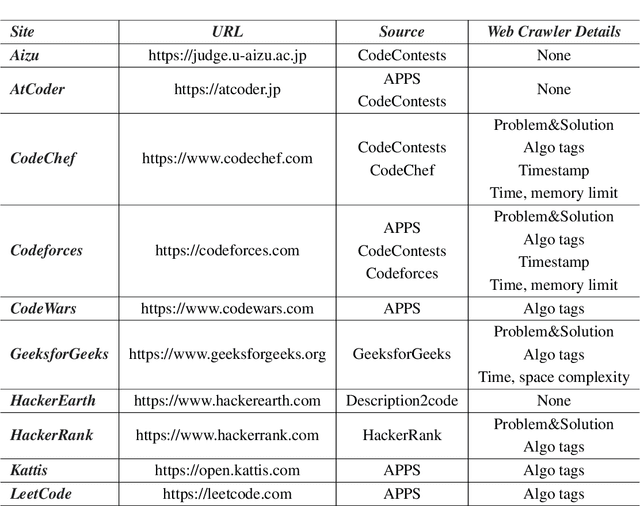

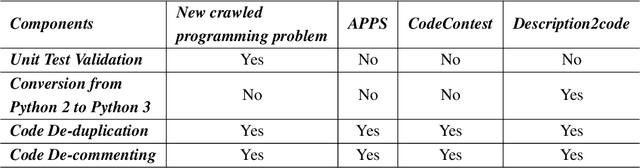
We introduce TACO, an open-source, large-scale code generation dataset, with a focus on the optics of algorithms, designed to provide a more challenging training dataset and evaluation benchmark in the field of code generation models. TACO includes competition-level programming questions that are more challenging, to enhance or evaluate problem understanding and reasoning abilities in real-world programming scenarios. There are 25433 and 1000 coding problems in training and test set, as well as up to 1.55 million diverse solution answers. Moreover, each TACO problem includes several fine-grained labels such as task topics, algorithms, programming skills, and difficulty levels, providing a more precise reference for the training and evaluation of code generation models. The dataset and evaluation scripts are available on Hugging Face Hub (https://huggingface.co/datasets/BAAI/TACO) and Github (https://github.com/FlagOpen/TACO).
DPFNet: A Dual-branch Dilated Network with Phase-aware Fourier Convolution for Low-light Image Enhancement
Sep 16, 2022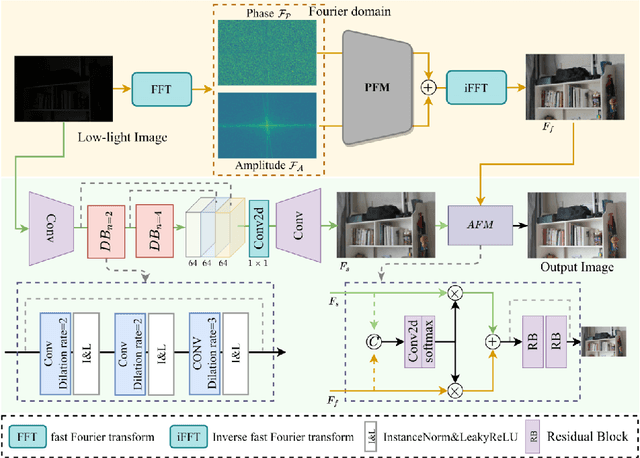


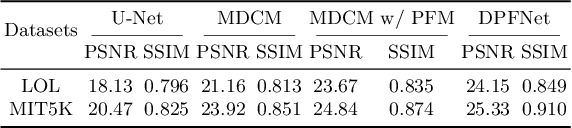
Low-light image enhancement is a classical computer vision problem aiming to recover normal-exposure images from low-light images. However, convolutional neural networks commonly used in this field are good at sampling low-frequency local structural features in the spatial domain, which leads to unclear texture details of the reconstructed images. To alleviate this problem, we propose a novel module using the Fourier coefficients, which can recover high-quality texture details under the constraint of semantics in the frequency phase and supplement the spatial domain. In addition, we design a simple and efficient module for the image spatial domain using dilated convolutions with different receptive fields to alleviate the loss of detail caused by frequent downsampling. We integrate the above parts into an end-to-end dual branch network and design a novel loss committee and an adaptive fusion module to guide the network to flexibly combine spatial and frequency domain features to generate more pleasing visual effects. Finally, we evaluate the proposed network on public benchmarks. Extensive experimental results show that our method outperforms many existing state-of-the-art ones, showing outstanding performance and potential.
M2TS: Multi-Scale Multi-Modal Approach Based on Transformer for Source Code Summarization
Mar 27, 2022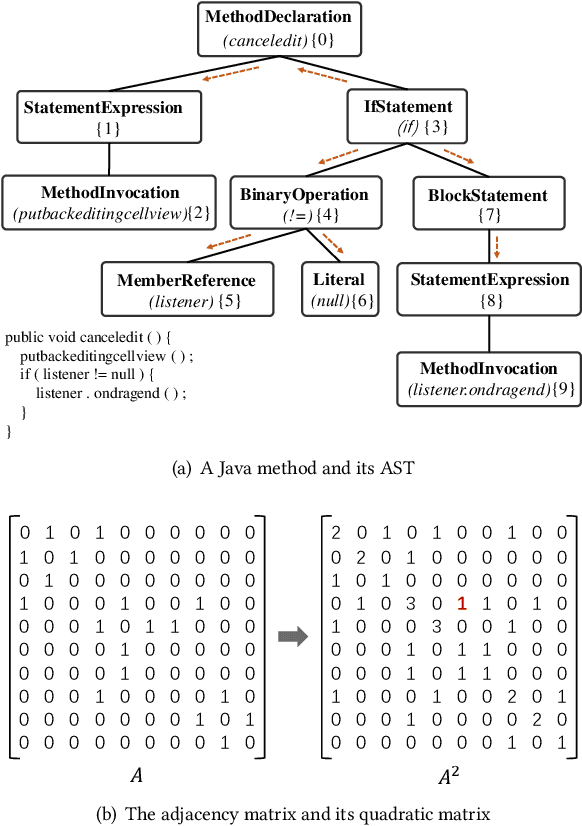

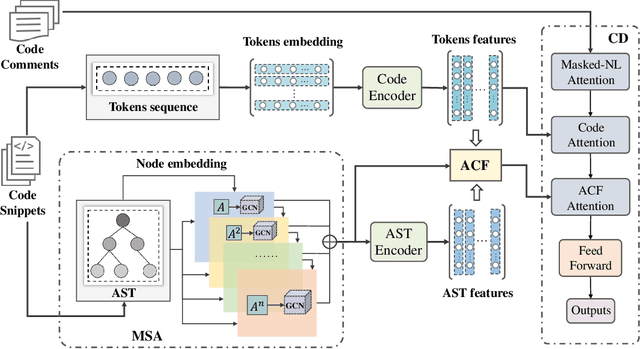

Source code summarization aims to generate natural language descriptions of code snippets. Many existing studies learn the syntactic and semantic knowledge of code snippets from their token sequences and Abstract Syntax Trees (ASTs). They use the learned code representations as input to code summarization models, which can accordingly generate summaries describing source code. Traditional models traverse ASTs as sequences or split ASTs into paths as input. However, the former loses the structural properties of ASTs, and the latter destroys the overall structure of ASTs. Therefore, comprehensively capturing the structural features of ASTs in learning code representations for source code summarization remains a challenging problem to be solved. In this paper, we propose M2TS, a Multi-scale Multi-modal approach based on Transformer for source code Summarization. M2TS uses a multi-scale AST feature extraction method, which can extract the structures of ASTs more completely and accurately at multiple local and global levels. To complement missing semantic information in ASTs, we also obtain code token features, and further combine them with the extracted AST features using a cross modality fusion method that not only fuses the syntactic and contextual semantic information of source code, but also highlights the key features of each modality. We conduct experiments on two Java and one Python datasets, and the experimental results demonstrate that M2TS outperforms current state-of-the-art methods. We release our code at https://github.com/TranSMS/M2TS.
TreeBERT: A Tree-Based Pre-Trained Model for Programming Language
May 26, 2021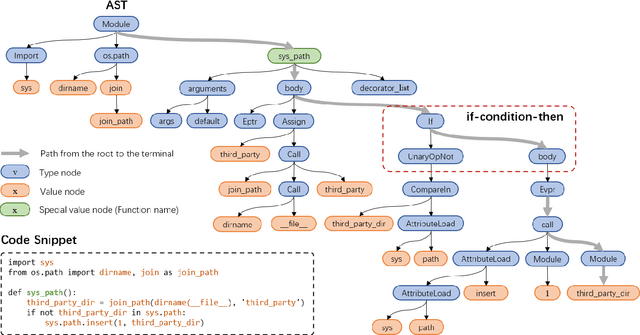
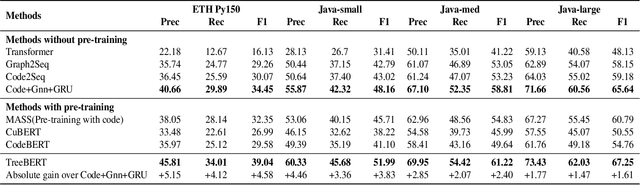
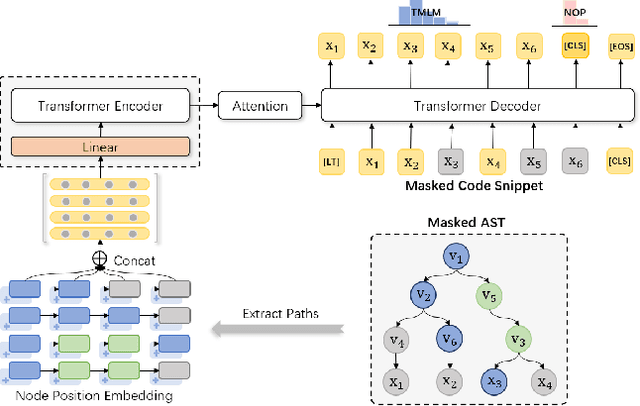

Source code can be parsed into the abstract syntax tree (AST) based on defined syntax rules. However, in pre-training, little work has considered the incorporation of tree structure into the learning process. In this paper, we present TreeBERT, a tree-based pre-trained model for improving programming language-oriented generation tasks. To utilize tree structure, TreeBERT represents the AST corresponding to the code as a set of composition paths and introduces node position embedding. The model is trained by tree masked language modeling (TMLM) and node order prediction (NOP) with a hybrid objective. TMLM uses a novel masking strategy designed according to the tree's characteristics to help the model understand the AST and infer the missing semantics of the AST. With NOP, TreeBERT extracts the syntactical structure by learning the order constraints of nodes in AST. We pre-trained TreeBERT on datasets covering multiple programming languages. On code summarization and code documentation tasks, TreeBERT outperforms other pre-trained models and state-of-the-art models designed for these tasks. Furthermore, TreeBERT performs well when transferred to the pre-trained unseen programming language.