 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2TS: Multi-Scale Multi-Modal Approach Based on Transformer for Source Code Summarization
Mar 27, 2022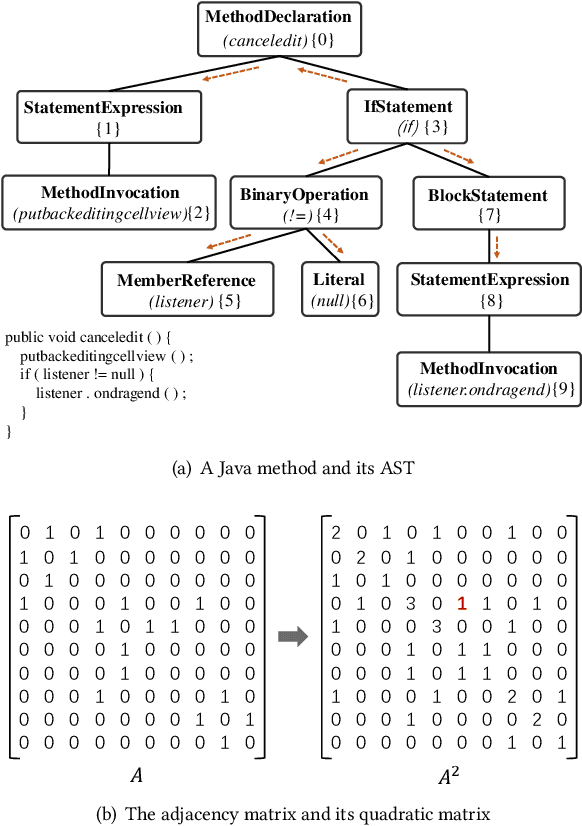

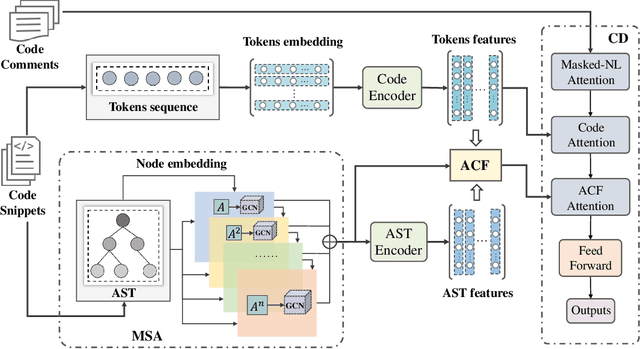

Source code summarization aims to generate natural language descriptions of code snippets. Many existing studies learn the syntactic and semantic knowledge of code snippets from their token sequences and Abstract Syntax Trees (ASTs). They use the learned code representations as input to code summarization models, which can accordingly generate summaries describing source code. Traditional models traverse ASTs as sequences or split ASTs into paths as input. However, the former loses the structural properties of ASTs, and the latter destroys the overall structure of ASTs. Therefore, comprehensively capturing the structural features of ASTs in learning code representations for source code summarization remains a challenging problem to be solved. In this paper, we propose M2TS, a Multi-scale Multi-modal approach based on Transformer for source code Summarization. M2TS uses a multi-scale AST feature extraction method, which can extract the structures of ASTs more completely and accurately at multiple local and global levels. To complement missing semantic information in ASTs, we also obtain code token features, and further combine them with the extracted AST features using a cross modality fusion method that not only fuses the syntactic and contextual semantic information of source code, but also highlights the key features of each modality. We conduct experiments on two Java and one Python datasets, and the experimental results demonstrate that M2TS outperforms current state-of-the-art methods. We release our code at https://github.com/TranSMS/M2TS.