 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomic Hybrid Sparse/Diffuse Channel Estimation and Cramér-Rao Bounds Analysis
May 03, 2026In this paper, an atomic hybrid sparse/diffuse (aHSD) channel model in the frequency domain is proposed. Based on a structural analysis of the resolvable paths and diffuse scattering statistics, the Hybrid Atomic-Least-Squares (HALS) algorithm is designed to estimate sparse/diffuse components with a combined atomic and $\ell_2$ regularization. A theoretical analysis of the Lagrange dual problem is conducted, and the conditions required for primal and dual solutions are provided, supporting an off-the-grid delay-time estimator. The Cramér--Rao Bound (CRB) analysis in this paper focuses on the estimation of the channel parameters, resulting in a bound on the aggregate channel. Lower and upper bounds for the CRB on parameters are derived as functions of the minimum separations between frequency parameters. Numerical results via simulations on synthetic and real data validate the efficacy of the HALS estimation strategy and show the improved predictive ability of the CRB analysis for the performance of HALS versus previously considered bounds.
Understanding the Role of Pathways in a Deep Neural Network
Feb 28, 2024



Deep neural networks have demonstrated superior performance in artificial intelligence applications, but the opaqueness of their inner working mechanism is one major drawback in their application. The prevailing unit-based interpretation is a statistical observation of stimulus-response data, which fails to show a detailed internal process of inherent mechanisms of neural networks. In this work, we analyze a convolutional neural network (CNN) trained in the classification task and present an algorithm to extract the diffusion pathways of individual pixels to identify the locations of pixels in an input image associated with object classes. The pathways allow us to test the causal components which are important for classification and the pathway-based representations are clearly distinguishable between categories. We find that the few largest pathways of an individual pixel from an image tend to cross the feature maps in each layer that is important for classification. And the large pathways of images of the same category are more consistent in their trends than those of different categories. We also apply the pathways to understanding adversarial attacks, object completion, and movement perception. Further, the total number of pathways on feature maps in all layers can clearly discriminate the original, deformed, and target samples.
Contrastive Multi-Level Graph Neural Networks for Session-based Recommendation
Nov 06, 2023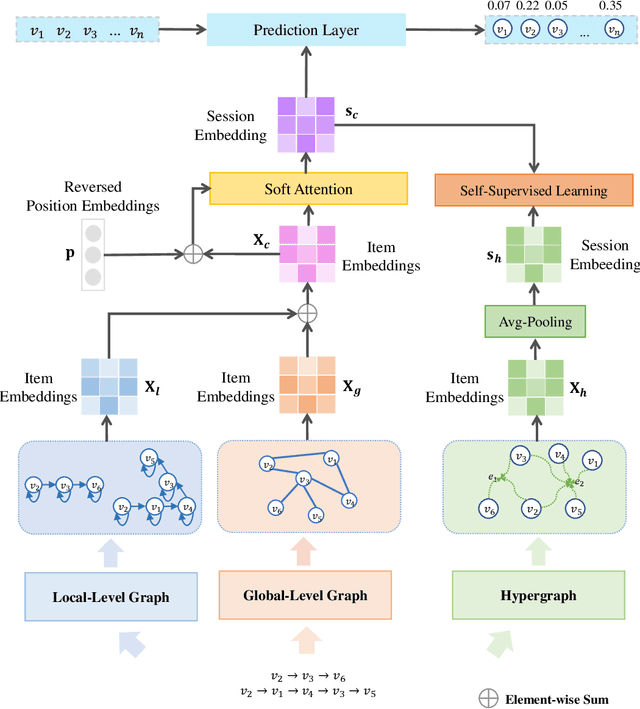
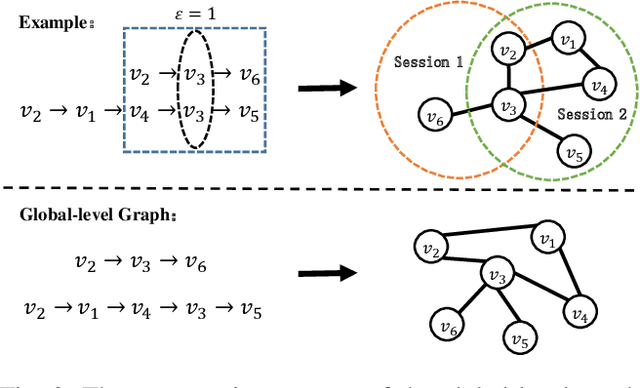
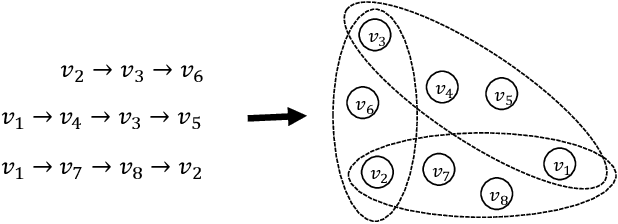

Session-based recommendation (SBR) aims to predict the next item at a certain time point based on anonymous user behavior sequences. Existing methods typically model session representation based on simple item transition information. However, since session-based data consists of limited users' short-term interactions, modeling session representation by capturing fixed item transition information from a single dimension suffers from data sparsity. In this paper, we propose a novel contrastive multi-level graph neural networks (CM-GNN) to better exploit complex and high-order item transition information. Specifically, CM-GNN applies local-level graph convolutional network (L-GCN) and global-level network (G-GCN) on the current session and all the sessions respectively, to effectively capture pairwise relations over all the sessions by aggregation strategy. Meanwhile, CM-GNN applies hyper-level graph convolutional network (H-GCN) to capture high-order information among all the item transitions. CM-GNN further introduces an attention-based fusion module to learn pairwise relation-based session representation by fusing the item representations generated by L-GCN and G-GCN. CM-GNN averages the item representations obtained by H-GCN to obtain high-order relation-based session representation. Moreover, to convert the high-order item transition information into the pairwise relation-based session representation, CM-GNN maximizes the mutual information between the representations derived from the fusion module and the average pool layer by contrastive learning paradigm. We conduct extensive experiments on multiple widely used benchmark datasets to validate the efficacy of the proposed method. The encouraging results demonstrate that our proposed method outperforms the state-of-the-art SBR techniques.
Skeleton-based Action Recognition through Contrasting Two-Stream Spatial-Temporal Networks
Jan 27, 2023



For pursuing accurate skeleton-based action recognition, most prior methods use the strategy of combining Graph Convolution Networks (GCNs) with attention-based methods in a serial way. However, they regard the human skeleton as a complete graph, resulting in less variations between different actions (e.g., the connection between the elbow and head in action ``clapping hands''). For this, we propose a novel Contrastive GCN-Transformer Network (ConGT) which fuses the spatial and temporal modules in a parallel way. The ConGT involves two parallel streams: Spatial-Temporal Graph Convolution stream (STG) and Spatial-Temporal Transformer stream (STT). The STG is designed to obtain action representations maintaining the natural topology structure of the human skeleton. The STT is devised to acquire action representations containing the global relationships among joints. Since the action representations produced from these two streams contain different characteristics, and each of them knows little information of the other, we introduce the contrastive learning paradigm to guide their output representations of the same sample to be as close as possible in a self-supervised manner. Through the contrastive learning, they can learn information from each other to enrich the action features by maximizing the mutual information between the two types of action representations. To further improve action recognition accuracy, we introduce the Cyclical Focal Loss (CFL) which can focus on confident training samples in early training epochs, with an increasing focus on hard samples during the middle epochs. We conduct experiments on three benchmark datasets, which demonstrate that our model achieves state-of-the-art performance in action recognition.
TreeBERT: A Tree-Based Pre-Trained Model for Programming Language
May 26, 2021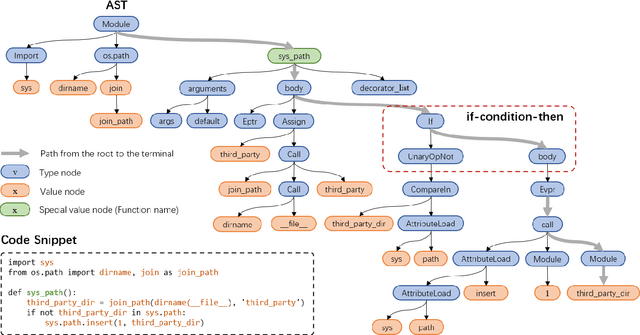
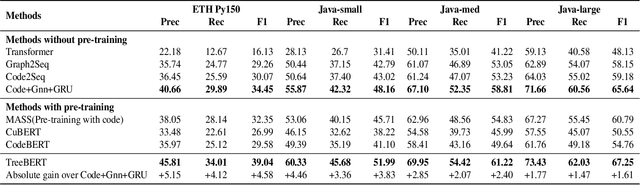
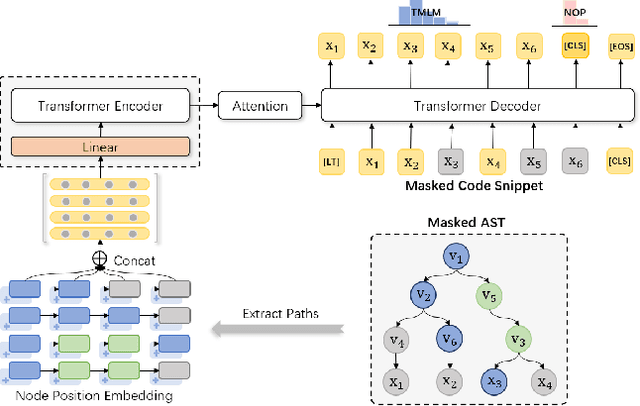

Source code can be parsed into the abstract syntax tree (AST) based on defined syntax rules. However, in pre-training, little work has considered the incorporation of tree structure into the learning process. In this paper, we present TreeBERT, a tree-based pre-trained model for improving programming language-oriented generation tasks. To utilize tree structure, TreeBERT represents the AST corresponding to the code as a set of composition paths and introduces node position embedding. The model is trained by tree masked language modeling (TMLM) and node order prediction (NOP) with a hybrid objective. TMLM uses a novel masking strategy designed according to the tree's characteristics to help the model understand the AST and infer the missing semantics of the AST. With NOP, TreeBERT extracts the syntactical structure by learning the order constraints of nodes in AST. We pre-trained TreeBERT on datasets covering multiple programming languages. On code summarization and code documentation tasks, TreeBERT outperforms other pre-trained models and state-of-the-art models designed for these tasks. Furthermore, TreeBERT performs well when transferred to the pre-trained unseen programming language.