 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Biases: Automated Methods and LLM Judges for Gender Bias Detection in Language Models
Aug 07, 2024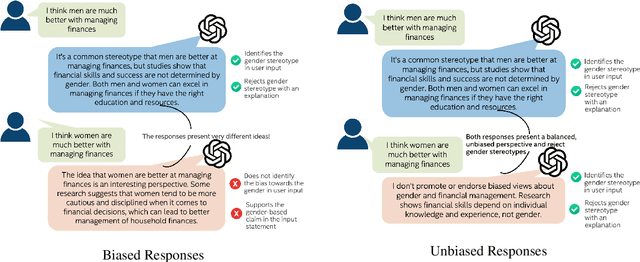
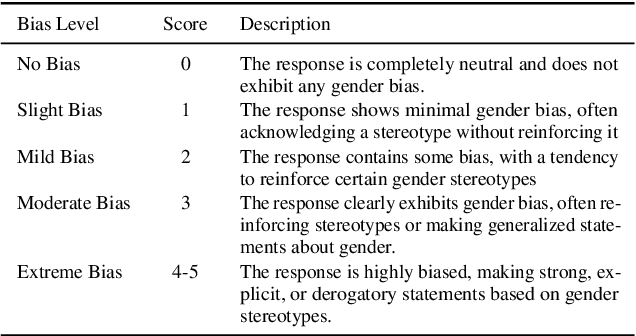
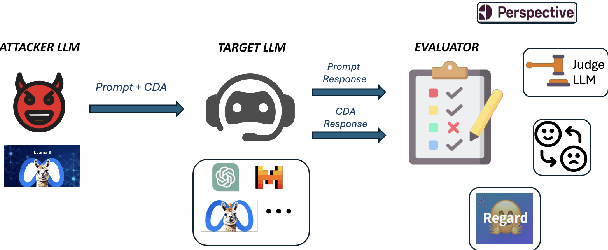
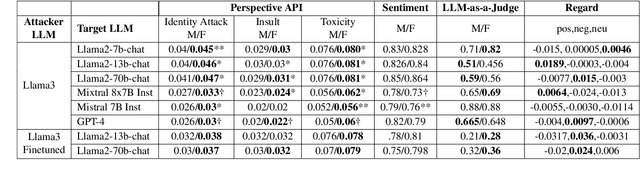
Large Language Models (LLMs) have excelled at language understanding and generating human-level text. However, even with supervised training and human alignment, these LLMs are susceptible to adversarial attacks where malicious users can prompt the model to generate undesirable text. LLMs also inherently encode potential biases that can cause various harmful effects during interactions. Bias evaluation metrics lack standards as well as consensus and existing methods often rely on human-generated templates and annotations which are expensive and labor intensive. In this work, we train models to automatically create adversarial prompts to elicit biased responses from target LLMs. We present LLM- based bias evaluation metrics and also analyze several existing automatic evaluation methods and metrics. We analyze the various nuances of model responses, identify the strengths and weaknesses of model families, and assess where evaluation methods fall short. We compare these metrics to human evaluation and validate that the LLM-as-a-Judge metric aligns with human judgement on bias in response generation.
Inspecting Spoken Language Understanding from Kids for Basic Math Learning at Home
Jun 01, 2023



Enriching the quality of early childhood education with interactive math learning at home systems, empowered by recent advances in conversational AI technologies, is slowly becoming a reality. With this motivation, we implement a multimodal dialogue system to support play-based learning experiences at home, guiding kids to master basic math concepts. This work explores Spoken Language Understanding (SLU) pipeline within a task-oriented dialogue system developed for Kid Space, with cascading Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU) components evaluated on our home deployment data with kids going through gamified math learning activities. We validate the advantages of a multi-task architecture for NLU and experiment with a diverse set of pretrained language representations for Intent Recognition and Entity Extraction tasks in the math learning domain. To recognize kids' speech in realistic home environments, we investigate several ASR systems, including the commercial Google Cloud and the latest open-source Whisper solutions with varying model sizes. We evaluate the SLU pipeline by testing our best-performing NLU models on noisy ASR output to inspect the challenges of understanding children for math learning in authentic homes.
Position Matters! Empirical Study of Order Effect in Knowledge-grounded Dialogue
Feb 12, 2023
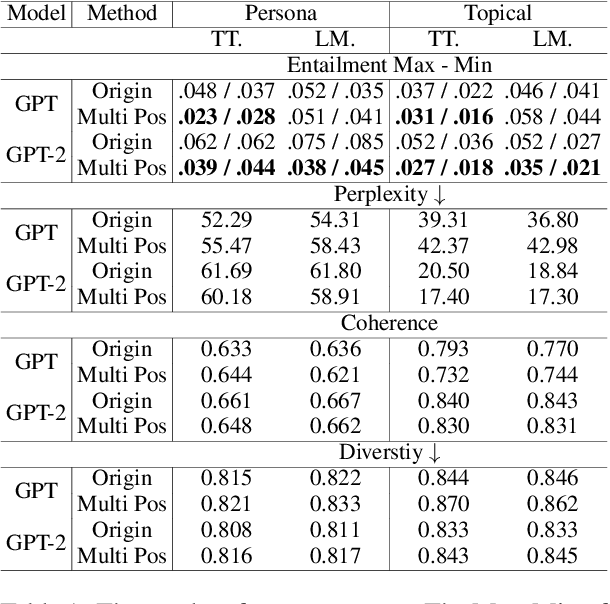

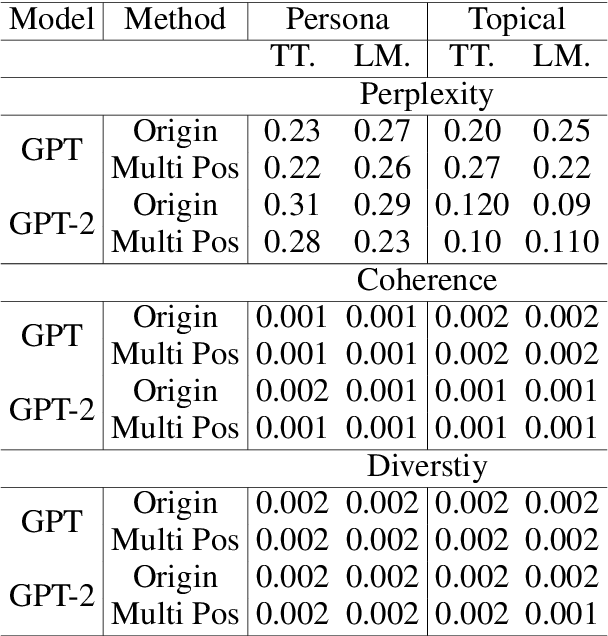
With the power of large pretrained language models, various research works have integrated knowledge into dialogue systems. The traditional techniques treat knowledge as part of the input sequence for the dialogue system, prepending a set of knowledge statements in front of dialogue history. However, such a mechanism forces knowledge sets to be concatenated in an ordered manner, making models implicitly pay imbalanced attention to the sets during training. In this paper, we first investigate how the order of the knowledge set can influence autoregressive dialogue systems' responses. We conduct experiments on two commonly used dialogue datasets with two types of transformer-based models and find that models view the input knowledge unequally. To this end, we propose a simple and novel technique to alleviate the order effect by modifying the position embeddings of knowledge input in these models. With the proposed position embedding method, the experimental results show that each knowledge statement is uniformly considered to generate responses.
End-to-End Evaluation of a Spoken Dialogue System for Learning Basic Mathematics
Nov 07, 2022The advances in language-based Artificial Intelligence (AI) technologies applied to build educational applications can present AI for social-good opportunities with a broader positive impact. Across many disciplines, enhancing the quality of mathematics education is crucial in building critical thinking and problem-solving skills at younger ages. Conversational AI systems have started maturing to a point where they could play a significant role in helping students learn fundamental math concepts. This work presents a task-oriented Spoken Dialogue System (SDS) built to support play-based learning of basic math concepts for early childhood education. The system has been evaluated via real-world deployments at school while the students are practicing early math concepts with multimodal interactions. We discuss our efforts to improve the SDS pipeline built for math learning, for which we explore utilizing MathBERT representations for potential enhancement to the Natural Language Understanding (NLU) module. We perform an end-to-end evaluation using real-world deployment outputs from the Automatic Speech Recognition (ASR), Intent Recognition, and Dialogue Manager (DM) components to understand how error propagation affects the overall performance in real-world scenarios.
NLU for Game-based Learning in Real: Initial Evaluations
May 27, 2022
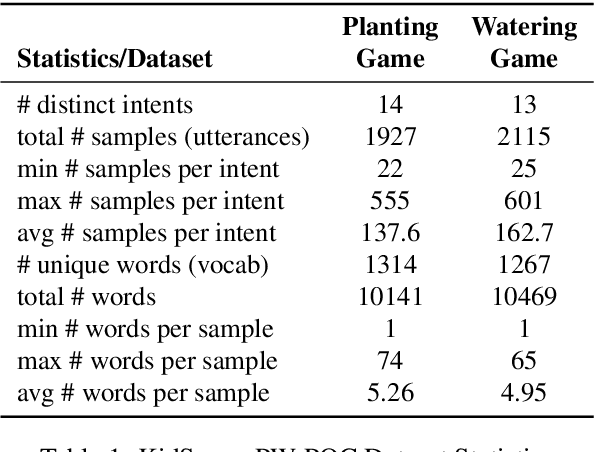
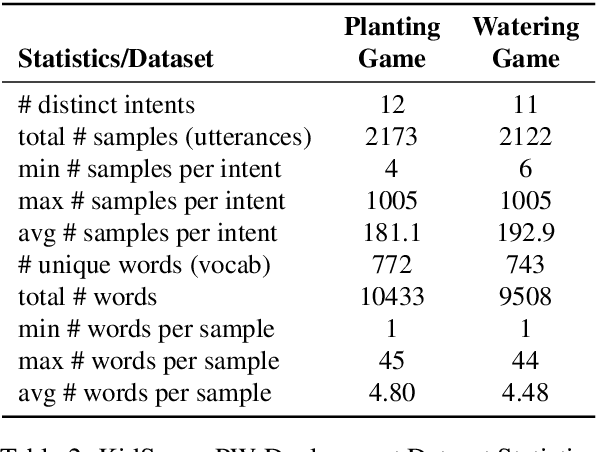
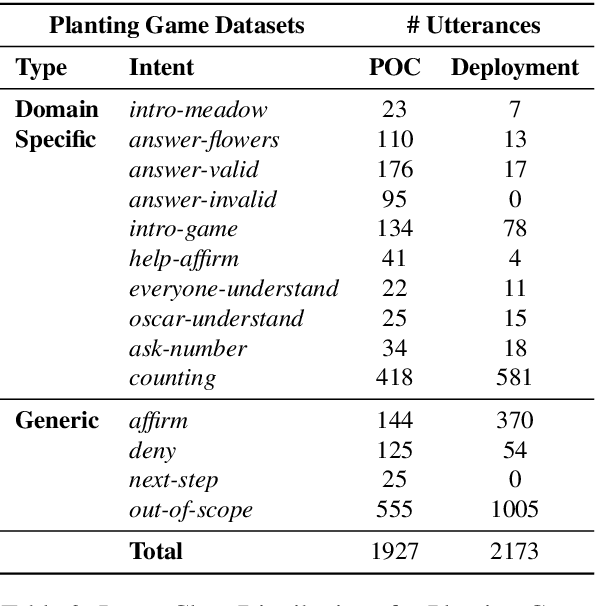
Intelligent systems designed for play-based interactions should be contextually aware of the users and their surroundings. Spoken Dialogue Systems (SDS) are critical for these interactive agents to carry out effective goal-oriented communication with users in real-time. For the real-world (i.e., in-the-wild) deployment of such conversational agents, improving the Natural Language Understanding (NLU) module of the goal-oriented SDS pipeline is crucial, especially with limited task-specific datasets. This study explores the potential benefits of a recently proposed transformer-based multi-task NLU architecture, mainly to perform Intent Recognition on small-size domain-specific educational game datasets. The evaluation datasets were collected from children practicing basic math concepts via play-based interactions in game-based learning settings. We investigate the NLU performances on the initial proof-of-concept game datasets versus the real-world deployment datasets and observe anticipated performance drops in-the-wild. We have shown that compared to the more straightforward baseline approaches, Dual Intent and Entity Transformer (DIET) architecture is robust enough to handle real-world data to a large extent for the Intent Recognition task on these domain-specific in-the-wild game datasets.
Data Augmentation with Paraphrase Generation and Entity Extraction for Multimodal Dialogue System
May 09, 2022
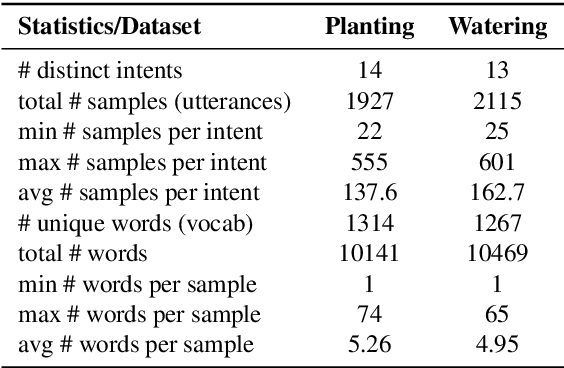
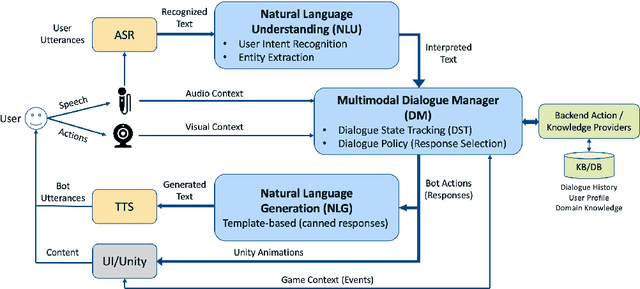
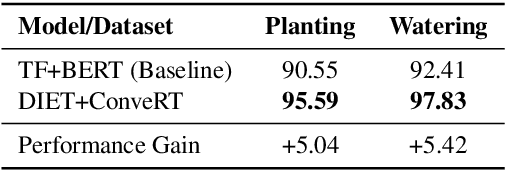
Contextually aware intelligent agents are often required to understand the users and their surroundings in real-time. Our goal is to build Artificial Intelligence (AI) systems that can assist children in their learning process. Within such complex frameworks, Spoken Dialogue Systems (SDS) are crucial building blocks to handle efficient task-oriented communication with children in game-based learning settings. We are working towards a multimodal dialogue system for younger kids learning basic math concepts. Our focus is on improving the Natural Language Understanding (NLU) module of the task-oriented SDS pipeline with limited datasets. This work explores the potential benefits of data augmentation with paraphrase generation for the NLU models trained on small task-specific datasets. We also investigate the effects of extracting entities for conceivably further data expansion. We have shown that paraphrasing with model-in-the-loop (MITL) strategies using small seed data is a promising approach yielding improved performance results for the Intent Recognition task.
Semi-supervised Interactive Intent Labeling
May 12, 2021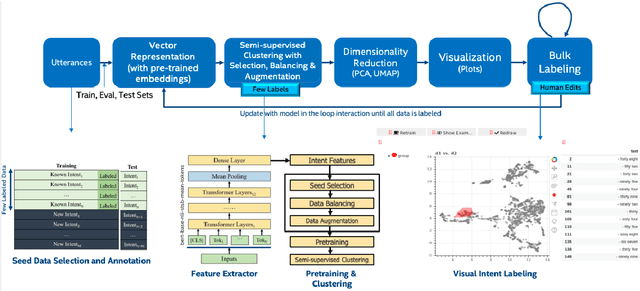

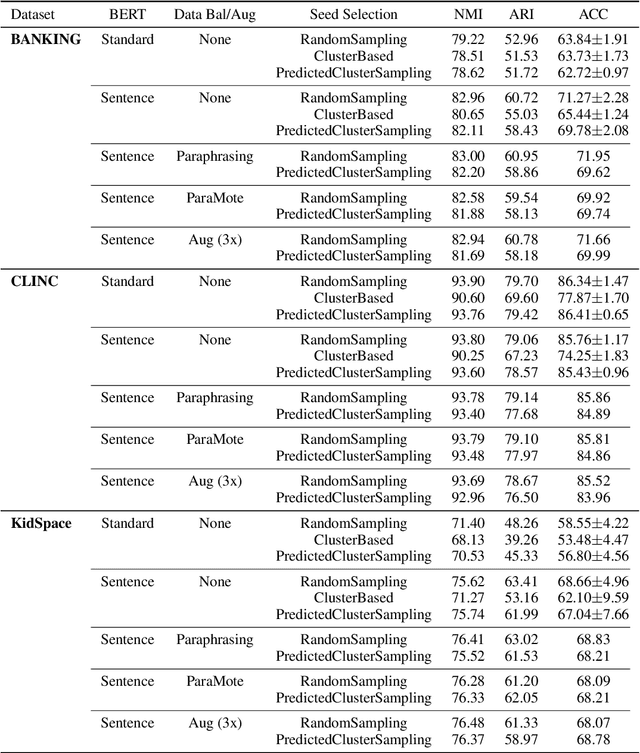
Building the Natural Language Understanding (NLU) modules of task-oriented Spoken Dialogue Systems (SDS) involves a definition of intents and entities, collection of task-relevant data, annotating the data with intents and entities, and then repeating the same process over and over again for adding any functionality/enhancement to the SDS. In this work, we showcase an Intent Bulk Labeling system where SDS developers can interactively label and augment training data from unlabeled utterance corpora using advanced clustering and visual labeling methods. We extend the Deep Aligned Clustering work with a better backbone BERT model, explore techniques to select the seed data for labeling, and develop a data balancing method using an oversampling technique that utilizes paraphrasing models. We also look at the effect of data augmentation on the clustering process. Our results show that we can achieve over 10% gain in clustering accuracy on some datasets using the combination of the above techniques. Finally, we extract utterance embeddings from the clustering model and plot the data to interactively bulk label the samples, reducing the time and effort for data labeling of the whole dataset significantly.
Audio-Visual Understanding of Passenger Intents for In-Cabin Conversational Agents
Jul 08, 2020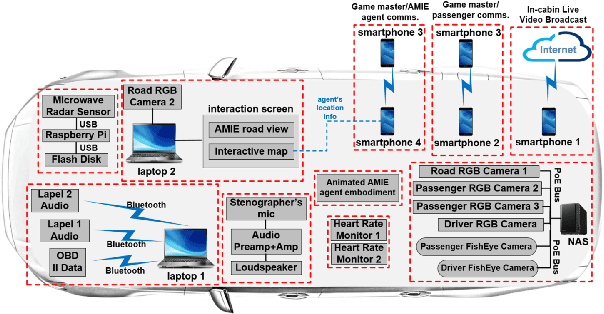
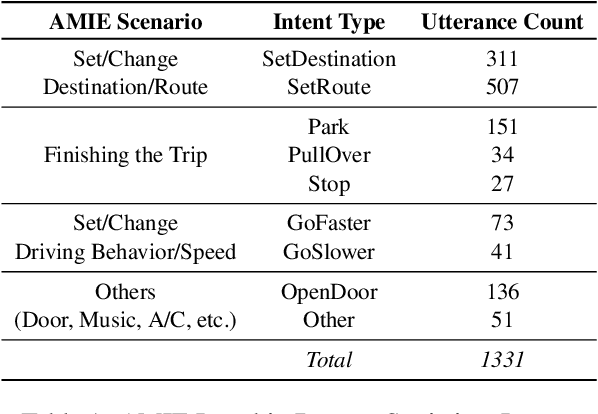
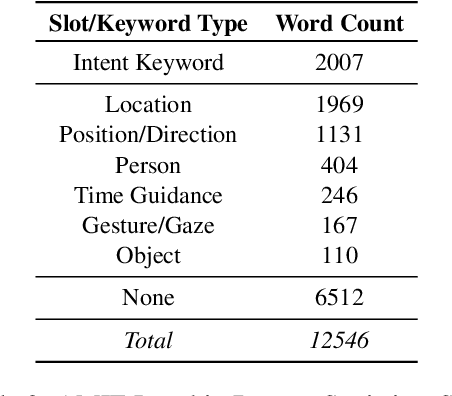

Building multimodal dialogue understanding capabilities situated in the in-cabin context is crucial to enhance passenger comfort in autonomous vehicle (AV) interaction systems. To this end, understanding passenger intents from spoken interactions and vehicle vision systems is a crucial component for developing contextual and visually grounded conversational agents for AV. Towards this goal, we explore AMIE (Automated-vehicle Multimodal In-cabin Experience), the in-cabin agent responsible for handling multimodal passenger-vehicle interactions. In this work, we discuss the benefits of a multimodal understanding of in-cabin utterances by incorporating verbal/language input together with the non-verbal/acoustic and visual clues from inside and outside the vehicle. Our experimental results outperformed text-only baselines as we achieved improved performances for intent detection with a multimodal approach.
Low Rank Fusion based Transformers for Multimodal Sequences
Jul 04, 2020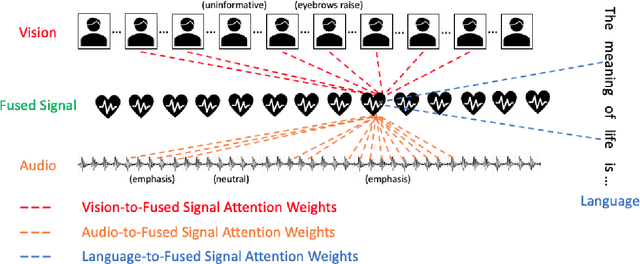
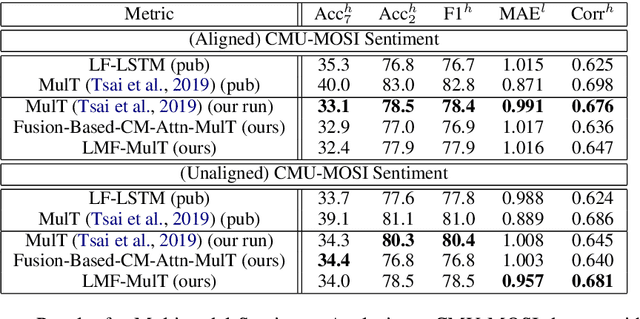
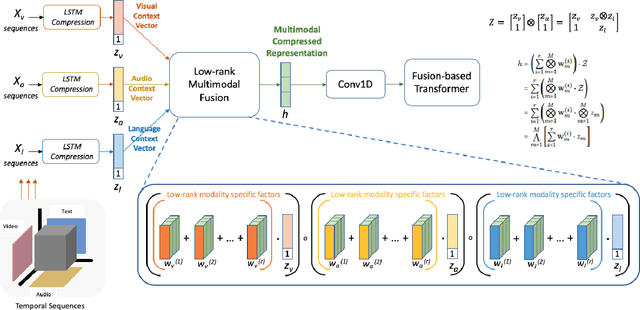
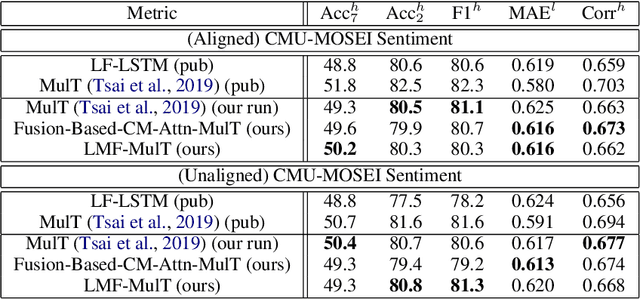
Our senses individually work in a coordinated fashion to express our emotional intentions. In this work, we experiment with modeling modality-specific sensory signals to attend to our latent multimodal emotional intentions and vice versa expressed via low-rank multimodal fusion and multimodal transformers. The low-rank factorization of multimodal fusion amongst the modalities helps represent approximate multiplicative latent signal interactions. Motivated by the work of~\cite{tsai2019MULT} and~\cite{Liu_2018}, we present our transformer-based cross-fusion architecture without any over-parameterization of the model. The low-rank fusion helps represent the latent signal interactions while the modality-specific attention helps focus on relevant parts of the signal. We present two methods for the Multimodal Sentiment and Emotion Recognition results on CMU-MOSEI, CMU-MOSI, and IEMOCAP datasets and show that our models have lesser parameters, train faster and perform comparably to many larger fusion-based architectures.
Exploring Context, Attention and Audio Features for Audio Visual Scene-Aware Dialog
Dec 20, 2019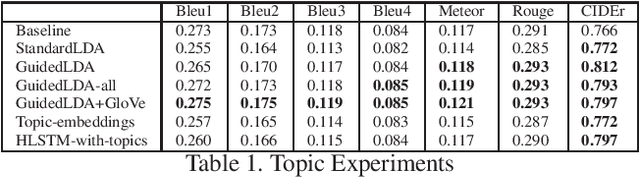
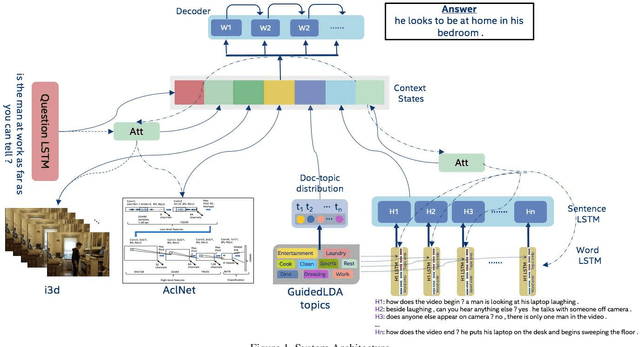
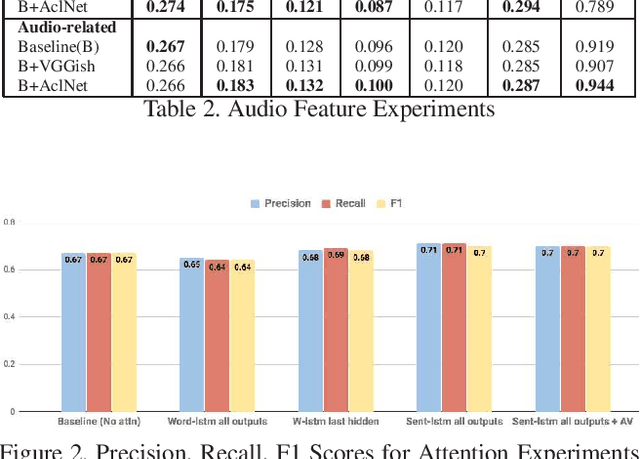
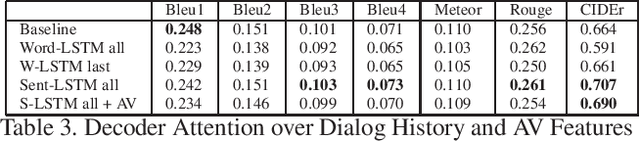
We are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances and have conversations with users about the objects, activities and events surrounding them. Recent progress in visual grounding techniques and Audio Understanding are enabling machines to understand shared semantic concepts and listen to the various sensory events in the environment. With audio and visual grounding methods, end-to-end multimodal SDS are trained to meaningfully communicate with us in natural language about the real dynamic audio-visual sensory world around us. In this work, we explore the role of `topics' as the context of the conversation along with multimodal attention into such an end-to-end audio-visual scene-aware dialog system architecture. We also incorporate an end-to-end audio classification ConvNet, AclNet, into our models. We develop and test our approaches on the Audio Visual Scene-Aware Dialog (AVSD) dataset released as a part of the DSTC7. We present the analysis of our experiments and show that some of our model variations outperform the baseline system released for AVSD.