 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Context, Attention and Audio Features for Audio Visual Scene-Aware Dialog
Paper and Code
Dec 20, 2019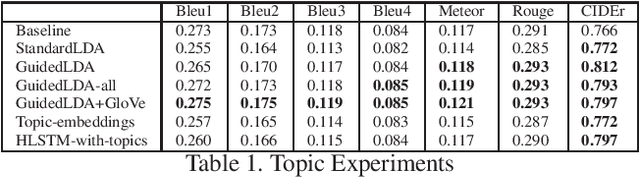
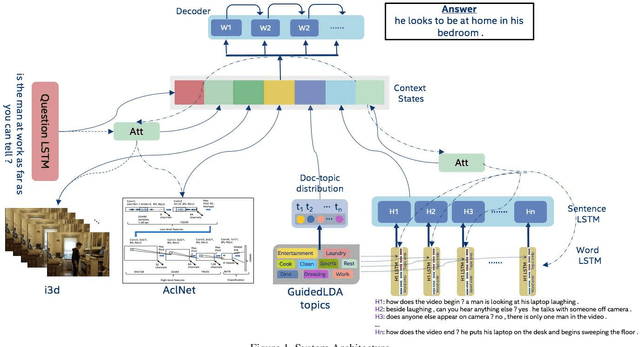
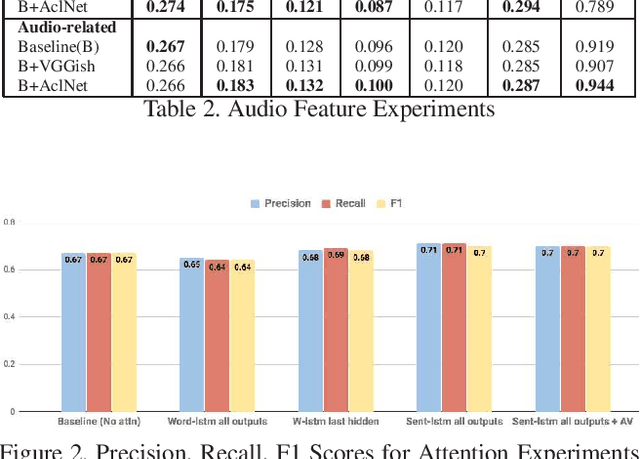
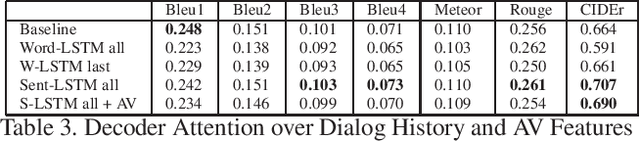
We are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances and have conversations with users about the objects, activities and events surrounding them. Recent progress in visual grounding techniques and Audio Understanding are enabling machines to understand shared semantic concepts and listen to the various sensory events in the environment. With audio and visual grounding methods, end-to-end multimodal SDS are trained to meaningfully communicate with us in natural language about the real dynamic audio-visual sensory world around us. In this work, we explore the role of `topics' as the context of the conversation along with multimodal attention into such an end-to-end audio-visual scene-aware dialog system architecture. We also incorporate an end-to-end audio classification ConvNet, AclNet, into our models. We develop and test our approaches on the Audio Visual Scene-Aware Dialog (AVSD) dataset released as a part of the DSTC7. We present the analysis of our experiments and show that some of our model variations outperform the baseline system released for AVSD.