 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Macro and Micro Effects of Random Seeds on Fine-Tuning Large Language Models
Mar 10, 2025
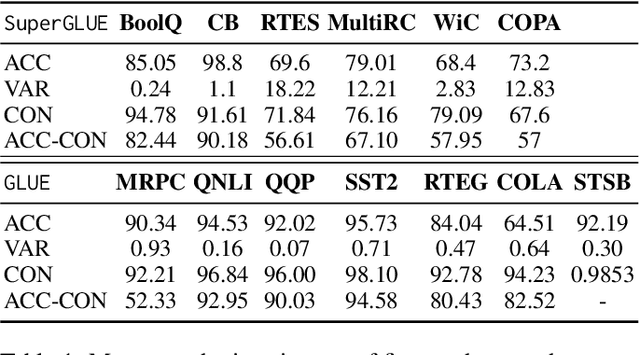


The impact of random seeds in fine-tuning large language models (LLMs) has been largely overlooked despite its potential influence on model performance.In this study, we systematically evaluate the effects of random seeds on LLMs using the GLUE and SuperGLUE benchmarks. We analyze the macro-level impact through traditional metrics like accuracy and F1, calculating their mean and variance to quantify performance fluctuations. To capture the micro-level effects, we introduce a novel metric, consistency, measuring the stability of individual predictions across runs. Our experiments reveal significant variance at both macro and micro levels, underscoring the need for careful consideration of random seeds in fine-tuning and evaluation.
WorldMedQA-V: a multilingual, multimodal medical examination dataset for multimodal language models evaluation
Oct 16, 2024Multimodal/vision language models (VLMs) are increasingly being deployed in healthcare settings worldwide, necessitating robust benchmarks to ensure their safety, efficacy, and fairness. Multiple-choice question and answer (QA) datasets derived from national medical examinations have long served as valuable evaluation tools, but existing datasets are largely text-only and available in a limited subset of languages and countries. To address these challenges, we present WorldMedQA-V, an updated multilingual, multimodal benchmarking dataset designed to evaluate VLMs in healthcare. WorldMedQA-V includes 568 labeled multiple-choice QAs paired with 568 medical images from four countries (Brazil, Israel, Japan, and Spain), covering original languages and validated English translations by native clinicians, respectively. Baseline performance for common open- and closed-source models are provided in the local language and English translations, and with and without images provided to the model. The WorldMedQA-V benchmark aims to better match AI systems to the diverse healthcare environments in which they are deployed, fostering more equitable, effective, and representative applications.
Identifying Task Groupings for Multi-Task Learning Using Pointwise V-Usable Information
Oct 16, 2024The success of multi-task learning can depend heavily on which tasks are grouped together. Naively grouping all tasks or a random set of tasks can result in negative transfer, with the multi-task models performing worse than single-task models. Though many efforts have been made to identify task groupings and to measure the relatedness among different tasks, it remains a challenging research topic to define a metric to identify the best task grouping out of a pool of many potential task combinations. We propose a metric of task relatedness based on task difficulty measured by pointwise V-usable information (PVI). PVI is a recently proposed metric to estimate how much usable information a dataset contains given a model. We hypothesize that tasks with not statistically different PVI estimates are similar enough to benefit from the joint learning process. We conduct comprehensive experiments to evaluate the feasibility of this metric for task grouping on 15 NLP datasets in the general, biomedical, and clinical domains. We compare the results of the joint learners against single learners, existing baseline methods, and recent large language models, including Llama 2 and GPT-4. The results show that by grouping tasks with similar PVI estimates, the joint learners yielded competitive results with fewer total parameters, with consistent performance across domains.
Measuring Pointwise $\mathcal{V}$-Usable Information In-Context-ly
Oct 18, 2023



In-context learning (ICL) is a new learning paradigm that has gained popularity along with the development of large language models. In this work, we adapt a recently proposed hardness metric, pointwise $\mathcal{V}$-usable information (PVI), to an in-context version (in-context PVI). Compared to the original PVI, in-context PVI is more efficient in that it requires only a few exemplars and does not require fine-tuning. We conducted a comprehensive empirical analysis to evaluate the reliability of in-context PVI. Our findings indicate that in-context PVI estimates exhibit similar characteristics to the original PVI. Specific to the in-context setting, we show that in-context PVI estimates remain consistent across different exemplar selections and numbers of shots. The variance of in-context PVI estimates across different exemplar selections is insignificant, which suggests that in-context PVI are stable. Furthermore, we demonstrate how in-context PVI can be employed to identify challenging instances. Our work highlights the potential of in-context PVI and provides new insights into the capabilities of ICL.
Diagnosis Prevalence vs. Efficacy in Machine-learning Based Diagnostic Decision Support
Jun 24, 2020

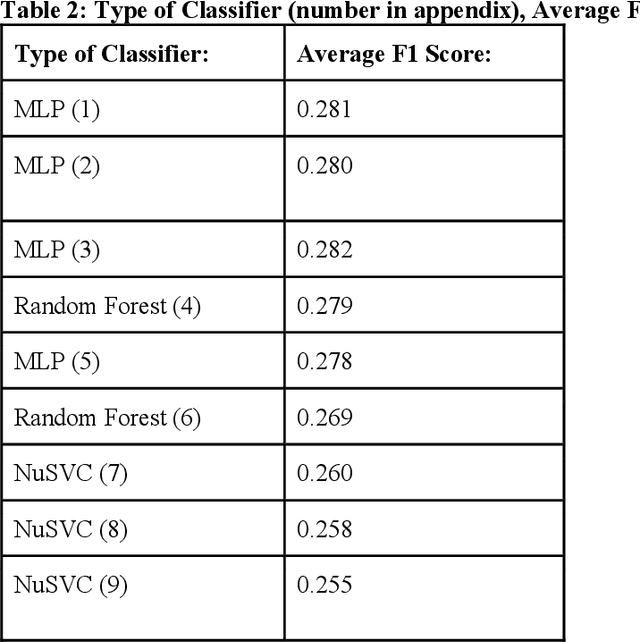
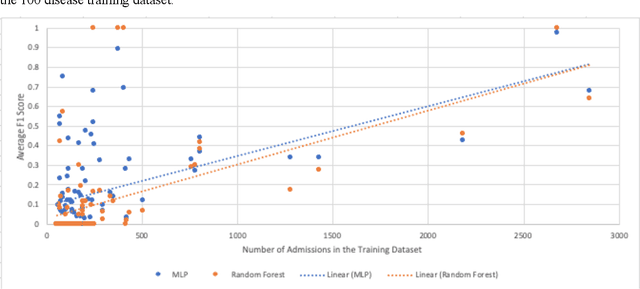
Many recent studies use machine learning to predict a small number of ICD-9-CM codes. In practice, on the other hand, physicians have to consider a broader range of diagnoses. This study aims to put these previously incongruent evaluation settings on a more equal footing by predicting ICD-9-CM codes based on electronic health record properties and demonstrating the relationship between diagnosis prevalence and system performance. We extracted patient features from the MIMIC-III dataset for each admission. We trained and evaluated 43 different machine learning classifiers. Among this pool, the most successful classifier was a Multi-Layer Perceptron. In accordance with general machine learning expectation, we observed all classifiers' F1 scores to drop as disease prevalence decreased. Scores fell from 0.28 for the 50 most prevalent ICD-9-CM codes to 0.03 for the 1000 most prevalent ICD-9-CM codes. Statistical analyses showed a moderate positive correlation between disease prevalence and efficacy (0.5866).