 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosis Prevalence vs. Efficacy in Machine-learning Based Diagnostic Decision Support
Jun 24, 2020

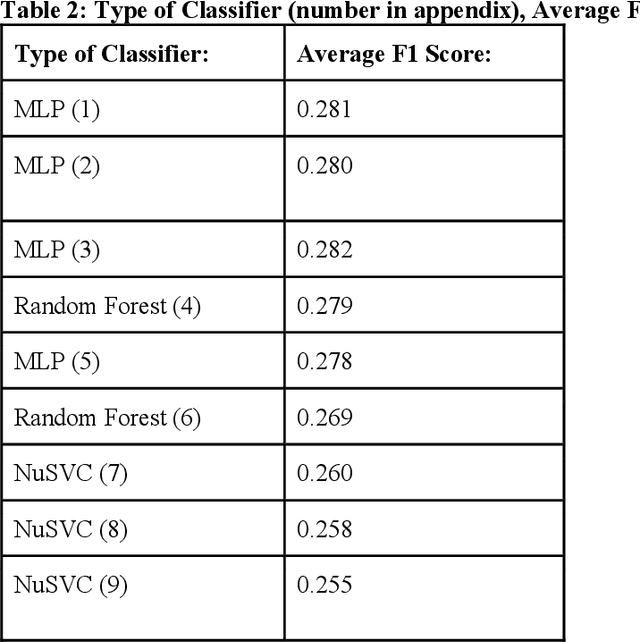
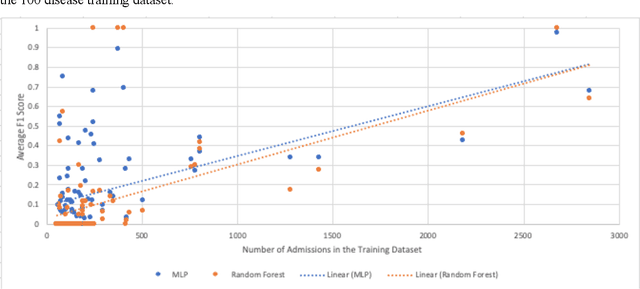
Many recent studies use machine learning to predict a small number of ICD-9-CM codes. In practice, on the other hand, physicians have to consider a broader range of diagnoses. This study aims to put these previously incongruent evaluation settings on a more equal footing by predicting ICD-9-CM codes based on electronic health record properties and demonstrating the relationship between diagnosis prevalence and system performance. We extracted patient features from the MIMIC-III dataset for each admission. We trained and evaluated 43 different machine learning classifiers. Among this pool, the most successful classifier was a Multi-Layer Perceptron. In accordance with general machine learning expectation, we observed all classifiers' F1 scores to drop as disease prevalence decreased. Scores fell from 0.28 for the 50 most prevalent ICD-9-CM codes to 0.03 for the 1000 most prevalent ICD-9-CM codes. Statistical analyses showed a moderate positive correlation between disease prevalence and efficacy (0.5866).