 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaDLAD: A Large Multi-Domain Bengali Document Layout Analysis Dataset
Mar 10, 2023
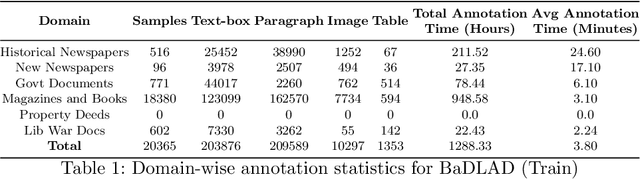
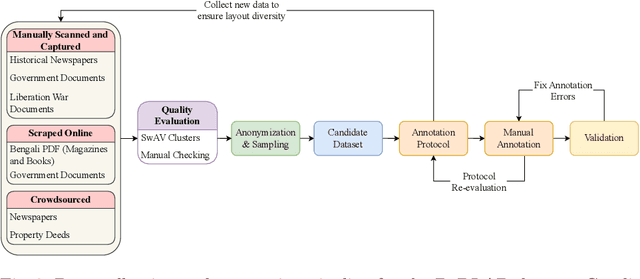
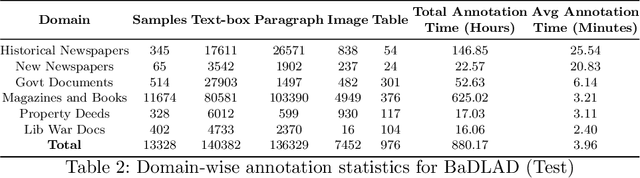
While strides have been made in deep learning based Bengali Optical Character Recognition (OCR) in the past decade, the absence of large Document Layout Analysis (DLA) datasets has hindered the application of OCR in document transcription, e.g., transcribing historical documents and newspapers. Moreover, rule-based DLA systems that are currently being employed in practice are not robust to domain variations and out-of-distribution layouts. To this end, we present the first multidomain large Bengali Document Layout Analysis Dataset: BaDLAD. This dataset contains 33,695 human annotated document samples from six domains - i) books and magazines, ii) public domain govt. documents, iii) liberation war documents, iv) newspapers, v) historical newspapers, and vi) property deeds, with 710K polygon annotations for four unit types: text-box, paragraph, image, and table. Through preliminary experiments benchmarking the performance of existing state-of-the-art deep learning architectures for English DLA, we demonstrate the efficacy of our dataset in training deep learning based Bengali document digitization models.
TEAM-Atreides at SemEval-2022 Task 11: On leveraging data augmentation and ensemble to recognize complex Named Entities in Bangla
Apr 21, 2022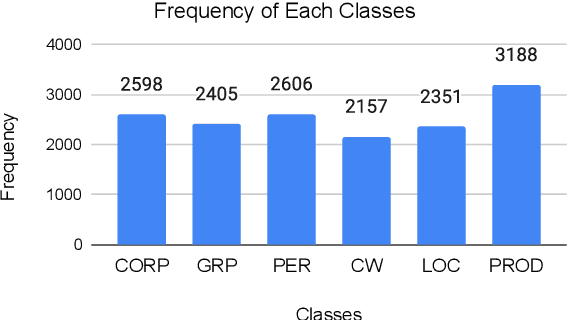

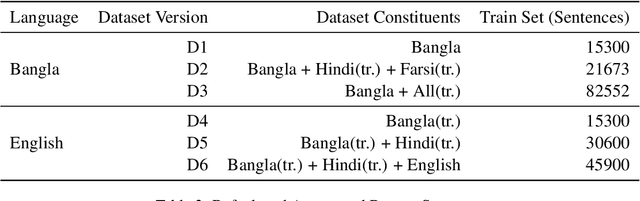
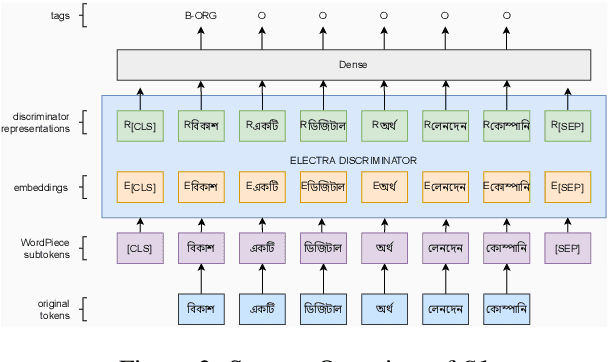
Many areas, such as the biological and healthcare domain, artistic works, and organization names, have nested, overlapping, discontinuous entity mentions that may even be syntactically or semantically ambiguous in practice. Traditional sequence tagging algorithms are unable to recognize these complex mentions because they may violate the assumptions upon which sequence tagging schemes are founded. In this paper, we describe our contribution to SemEval 2022 Task 11 on identifying such complex Named Entities. We have leveraged the ensemble of multiple ELECTRA-based models that were exclusively pretrained on the Bangla language with the performance of ELECTRA-based models pretrained on English to achieve competitive performance on the Track-11. Besides providing a system description, we will also present the outcomes of our experiments on architectural decisions, dataset augmentations, and post-competition findings.
Multi-label Classification of Common Bengali Handwritten Graphemes: Dataset and Challenge
Oct 29, 2020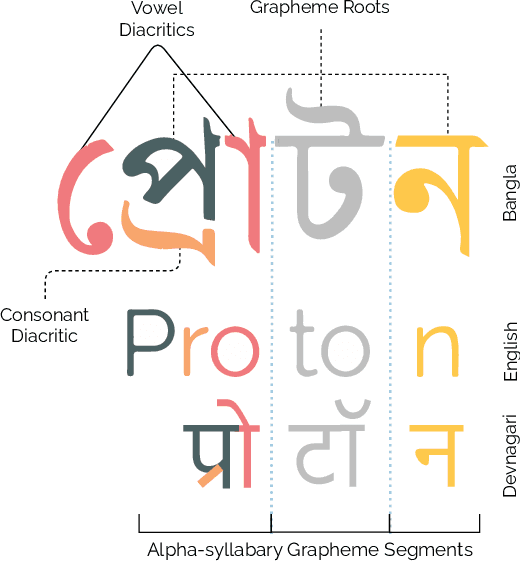



Latin has historically led the state-of-the-art in handwritten optical character recognition (OCR) research. Adapting existing systems from Latin to alpha-syllabary languages is particularly challenging due to a sharp contrast between their orthographies. The segmentation of graphical constituents corresponding to characters becomes significantly hard due to a cursive writing system and frequent use of diacritics in the alpha-syllabary family of languages. We propose a labeling scheme based on graphemes (linguistic segments of word formation) that makes segmentation inside alpha-syllabary words linear and present the first dataset of Bengali handwritten graphemes that are commonly used in an everyday context. The dataset is open-sourced as a part of the BengaliAI Handwritten Grapheme Classification Challenge on Kaggle to benchmark vision algorithms for multi-label grapheme classification. From competition proceedings, we see that deep learning methods can generalize to a large span of uncommon graphemes even when they are absent during training. Dataset and starter codes at www.kaggle.com/c/bengaliai-cv19.
SegCodeNet: Color-Coded Segmentation Masks for Activity Detection from Wearable Cameras
Aug 19, 2020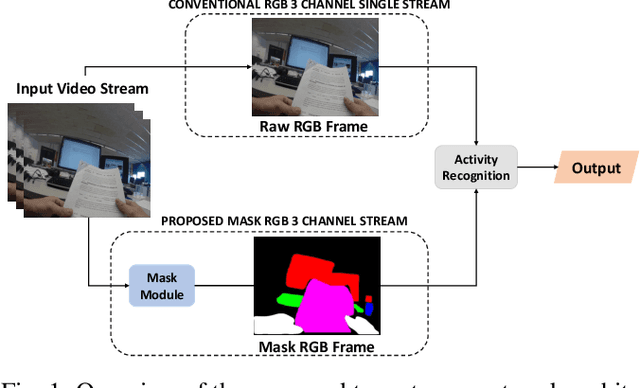

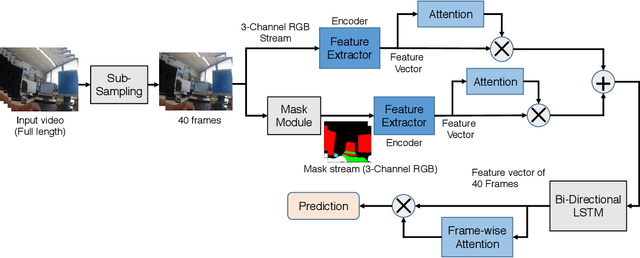
Activity detection from first-person videos (FPV) captured using a wearable camera is an active research field with potential applications in many sectors, including healthcare, law enforcement, and rehabilitation. State-of-the-art methods use optical flow-based hybrid techniques that rely on features derived from the motion of objects from consecutive frames. In this work, we developed a two-stream network, the \emph{SegCodeNet}, that uses a network branch containing video-streams with color-coded semantic segmentation masks of relevant objects in addition to the original RGB video-stream. We also include a stream-wise attention gating that prioritizes between the two streams and a frame-wise attention module that prioritizes the video frames that contain relevant features. Experiments are conducted on an FPV dataset containing $18$ activity classes in office environments. In comparison to a single-stream network, the proposed two-stream method achieves an absolute improvement of $14.366\%$ and $10.324\%$ for averaged F1 score and accuracy, respectively, when average results are compared for three different frame sizes $224\times224$, $112\times112$, and $64\times64$. The proposed method provides significant performance gains for lower-resolution images with absolute improvements of $17\%$ and $26\%$ in F1 score for input dimensions of $112\times112$ and $64\times64$, respectively. The best performance is achieved for a frame size of $224\times224$ yielding an F1 score and accuracy of $90.176\%$ and $90.799\%$ which outperforms the state-of-the-art Inflated 3D ConvNet (I3D) \cite{carreira2017quo} method by an absolute margin of $4.529\%$ and $2.419\%$, respectively.
Privacy-Aware Activity Classification from First Person Office Videos
Jun 11, 2020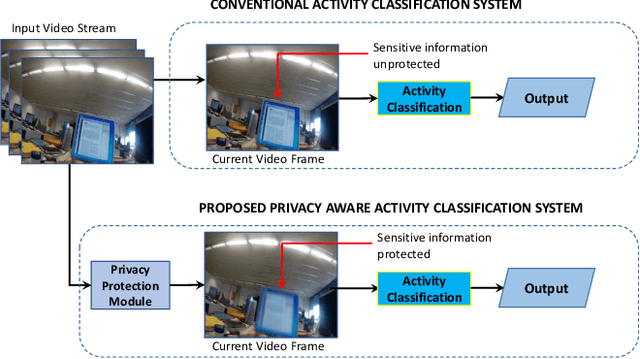

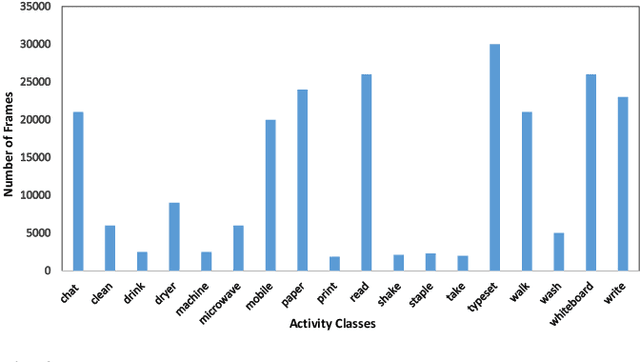

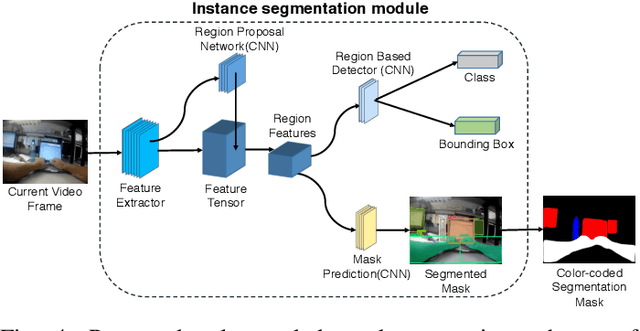
In the advent of wearable body-cameras, human activity classification from First-Person Videos (FPV) has become a topic of increasing importance for various applications, including in life-logging, law-enforcement, sports, workplace, and healthcare. One of the challenging aspects of FPV is its exposure to potentially sensitive objects within the user's field of view. In this work, we developed a privacy-aware activity classification system focusing on office videos. We utilized a Mask-RCNN with an Inception-ResNet hybrid as a feature extractor for detecting, and then blurring out sensitive objects (e.g., digital screens, human face, paper) from the videos. For activity classification, we incorporate an ensemble of Recurrent Neural Networks (RNNs) with ResNet, ResNext, and DenseNet based feature extractors. The proposed system was trained and evaluated on the FPV office video dataset that includes 18-classes made available through the IEEE Video and Image Processing (VIP) Cup 2019 competition. On the original unprotected FPVs, the proposed activity classifier ensemble reached an accuracy of 85.078% with precision, recall, and F1 scores of 0.88, 0.85 & 0.86, respectively. On privacy protected videos, the performances were slightly degraded, with accuracy, precision, recall, and F1 scores at 73.68%, 0.79, 0.75, and 0.74, respectively. The presented system won the 3rd prize in the IEEE VIP Cup 2019 competition.
X-Ray Image Compression Using Convolutional Recurrent Neural Networks
May 09, 2019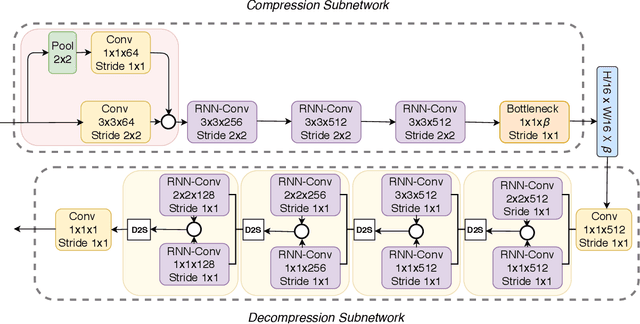
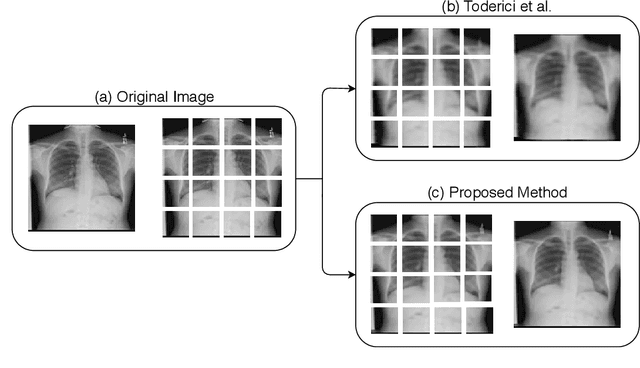
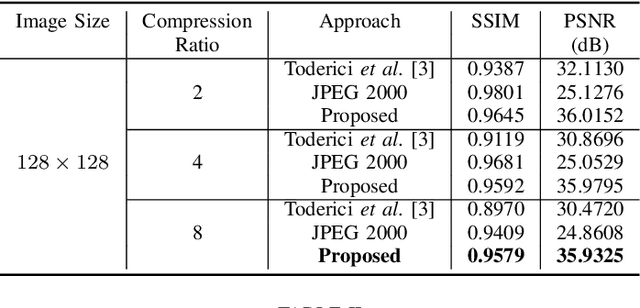
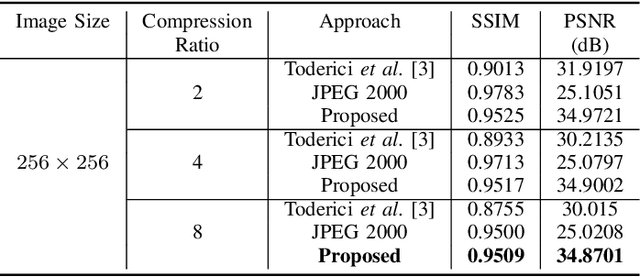
In the advent of a digital health revolution, vast amounts of clinical data are being generated, stored and processed on a daily basis. This has made the storage and retrieval of large volumes of health-care data, especially, high-resolution medical images, particularly challenging. Effective image compression for medical images thus plays a vital role in today's healthcare information system, particularly in teleradiology. In this work, an X-ray image compression method based on a Convolutional Recurrent Neural Networks RNN-Conv is presented. The proposed architecture can provide variable compression rates during deployment while it requires each network to be trained only once for a specific dimension of X-ray images. The model uses a multi-level pooling scheme that learns contextualized features for effective compression. We perform our image compression experiments on the National Institute of Health (NIH) ChestX-ray8 dataset and compare the performance of the proposed architecture with a state-of-the-art RNN based technique and JPEG 2000. The experimental results depict improved compression performance achieved by the proposed method in terms of Structural Similarity Index (SSIM) and Peak Signal-to-Noise Ratio (PSNR) metrics. To the best of our knowledge, this is the first reported evaluation on using a deep convolutional RNN for medical image compression.
End-to-end Sleep Staging with Raw Single Channel EEG using Deep Residual ConvNets
Apr 23, 2019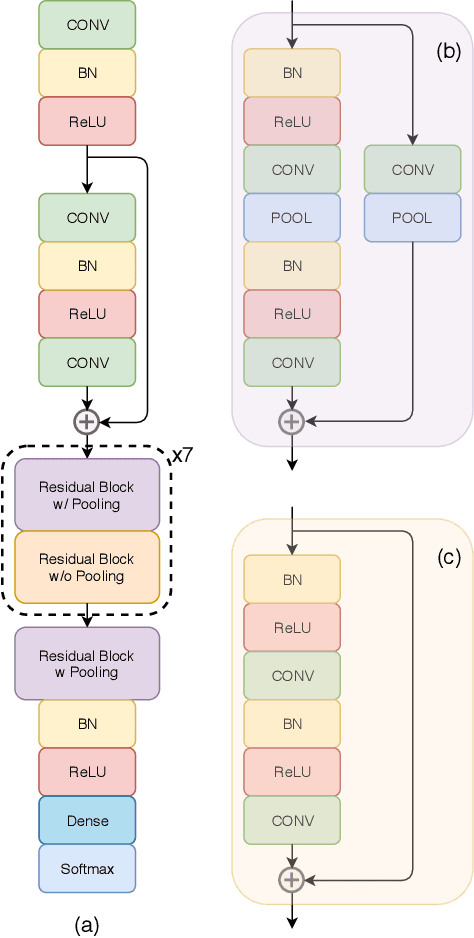
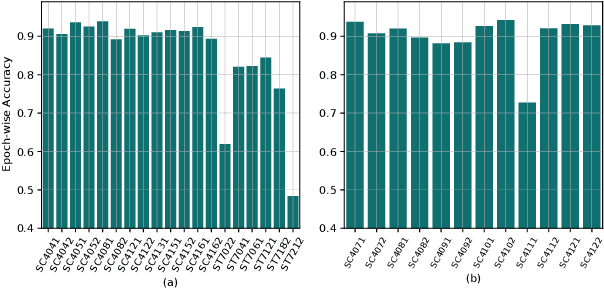
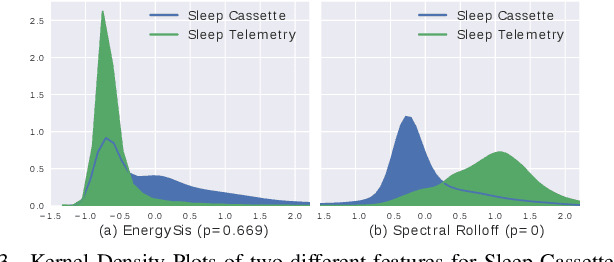
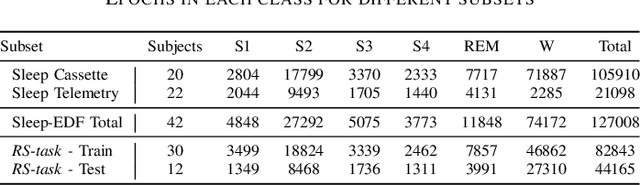
Humans approximately spend a third of their life sleeping, which makes monitoring sleep an integral part of well-being. In this paper, a 34-layer deep residual ConvNet architecture for end-to-end sleep staging is proposed. The network takes raw single channel electroencephalogram (Fpz-Cz) signal as input and yields hypnogram annotations for each 30s segments as output. Experiments are carried out for two different scoring standards (5 and 6 stage classification) on the expanded PhysioNet Sleep-EDF dataset, which contains multi-source data from hospital and household polysomnography setups. The performance of the proposed network is compared with that of the state-of-the-art algorithms in patient independent validation tasks. The experimental results demonstrate the superiority of the proposed network compared to the best existing method, providing a relative improvement in epoch-wise average accuracy of 6.8% and 6.3% on the household data and multi-source data, respectively. Codes are made publicly available on Github.