 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegCodeNet: Color-Coded Segmentation Masks for Activity Detection from Wearable Cameras
Paper and Code
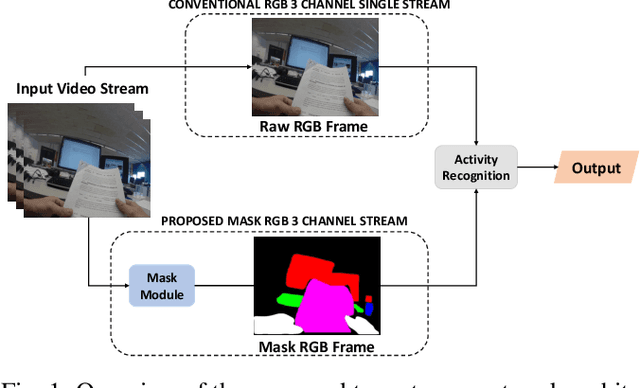

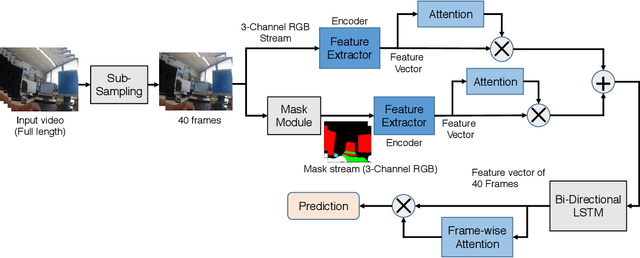
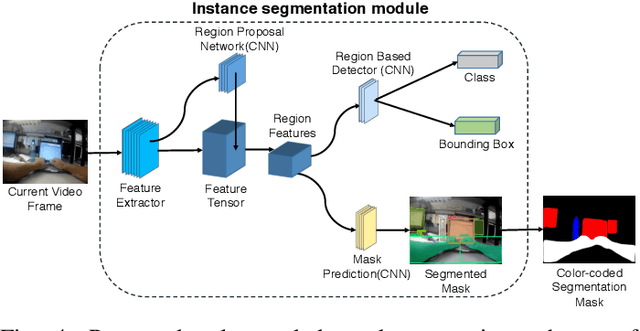
Activity detection from first-person videos (FPV) captured using a wearable camera is an active research field with potential applications in many sectors, including healthcare, law enforcement, and rehabilitation. State-of-the-art methods use optical flow-based hybrid techniques that rely on features derived from the motion of objects from consecutive frames. In this work, we developed a two-stream network, the \emph{SegCodeNet}, that uses a network branch containing video-streams with color-coded semantic segmentation masks of relevant objects in addition to the original RGB video-stream. We also include a stream-wise attention gating that prioritizes between the two streams and a frame-wise attention module that prioritizes the video frames that contain relevant features. Experiments are conducted on an FPV dataset containing $18$ activity classes in office environments. In comparison to a single-stream network, the proposed two-stream method achieves an absolute improvement of $14.366\%$ and $10.324\%$ for averaged F1 score and accuracy, respectively, when average results are compared for three different frame sizes $224\times224$, $112\times112$, and $64\times64$. The proposed method provides significant performance gains for lower-resolution images with absolute improvements of $17\%$ and $26\%$ in F1 score for input dimensions of $112\times112$ and $64\times64$, respectively. The best performance is achieved for a frame size of $224\times224$ yielding an F1 score and accuracy of $90.176\%$ and $90.799\%$ which outperforms the state-of-the-art Inflated 3D ConvNet (I3D) \cite{carreira2017quo} method by an absolute margin of $4.529\%$ and $2.419\%$, respectively.