 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization for Improved Human Activity Recognition in Office Space Videos Using Adaptive Pre-processing
Mar 16, 2025
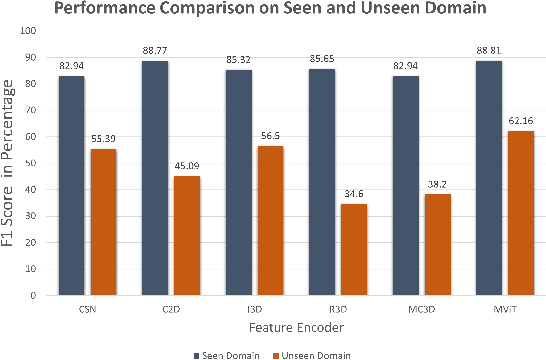
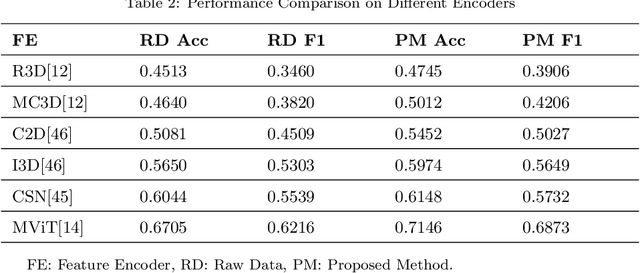
Automatic video activity recognition is crucial across numerous domains like surveillance, healthcare, and robotics. However, recognizing human activities from video data becomes challenging when training and test data stem from diverse domains. Domain generalization, adapting to unforeseen domains, is thus essential. This paper focuses on office activity recognition amidst environmental variability. We propose three pre-processing techniques applicable to any video encoder, enhancing robustness against environmental variations. Our study showcases the efficacy of MViT, a leading state-of-the-art video classification model, and other video encoders combined with our techniques, outperforming state-of-the-art domain adaptation methods. Our approach significantly boosts accuracy, precision, recall and F1 score on unseen domains, emphasizing its adaptability in real-world scenarios with diverse video data sources. This method lays a foundation for more reliable video activity recognition systems across heterogeneous data domains.
ResDTA: Predicting Drug-Target Binding Affinity Using Residual Skip Connections
Mar 20, 2023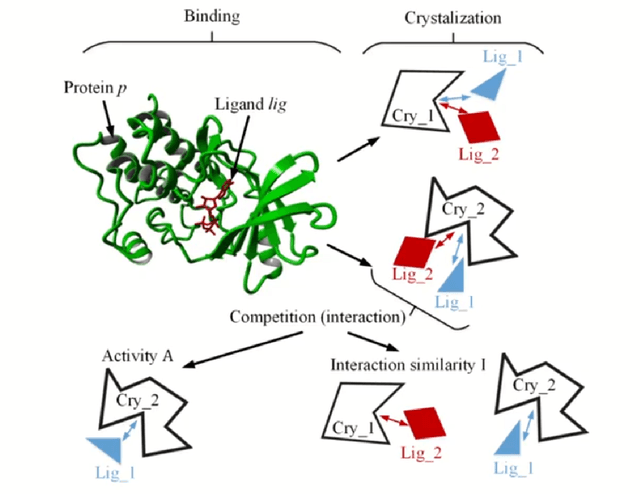
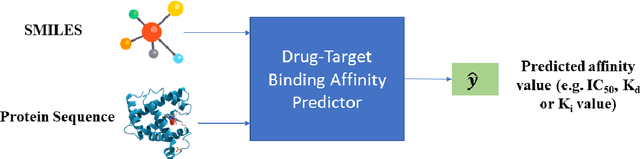
The discovery of novel drug target (DT) interactions is an important step in the drug development process. The majority of computer techniques for predicting DT interactions have focused on binary classification, with the goal of determining whether or not a DT pair interacts. Protein ligand interactions, on the other hand, assume a continuous range of binding strength values, also known as binding affinity, and forecasting this value remains a difficulty. As the amount of affinity data in DT knowledge-bases grows, advanced learning techniques such as deep learning architectures can be used to predict binding affinities. In this paper, we present a deep-learning-based methodology for predicting DT binding affinities using just sequencing information from both targets and drugs. The results show that the proposed deep learning-based model that uses the 1D representations of targets and drugs is an effective approach for drug target binding affinity prediction and it does not require additional chemical domain knowledge to work with. The model in which high-level representations of a drug and a target are constructed via CNNs that uses residual skip connections and also with an additional stream to create a high-level combined representation of the drug-target pair achieved the best Concordance Index (CI) performance in one of the largest benchmark datasets, outperforming the recent state-of-the-art method AttentionDTA and many other machine-learning and deep-learning based baseline methods for DT binding affinity prediction that uses the 1D representations of targets and drugs.
A Sequence Agnostic Multimodal Preprocessing for Clogged Blood Vessel Detection in Alzheimer's Diagnosis
Nov 06, 2022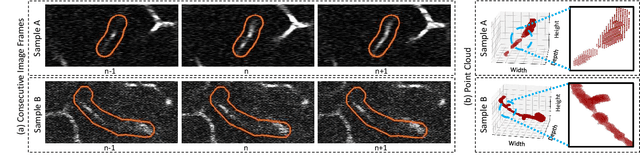
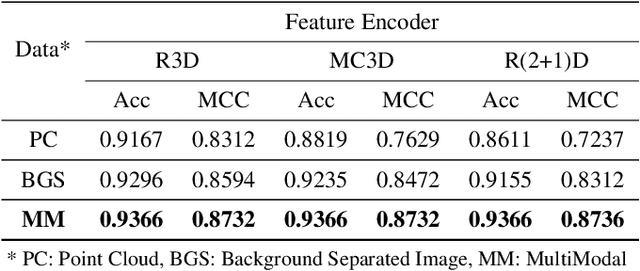

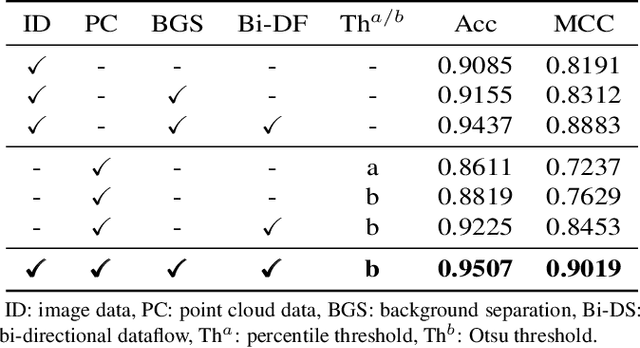
Successful identification of blood vessel blockage is a crucial step for Alzheimer's disease diagnosis. These blocks can be identified from the spatial and time-depth variable Two-Photon Excitation Microscopy (TPEF) images of the brain blood vessels using machine learning methods. In this study, we propose several preprocessing schemes to improve the performance of these methods. Our method includes 3D-point cloud data extraction from image modality and their feature-space fusion to leverage complementary information inherent in different modalities. We also enforce the learned representation to be sequence-order invariant by utilizing bi-direction dataflow. Experimental results on The Clog Loss dataset show that our proposed method consistently outperforms the state-of-the-art preprocessing methods in stalled and non-stalled vessel classification.
SegCodeNet: Color-Coded Segmentation Masks for Activity Detection from Wearable Cameras
Aug 19, 2020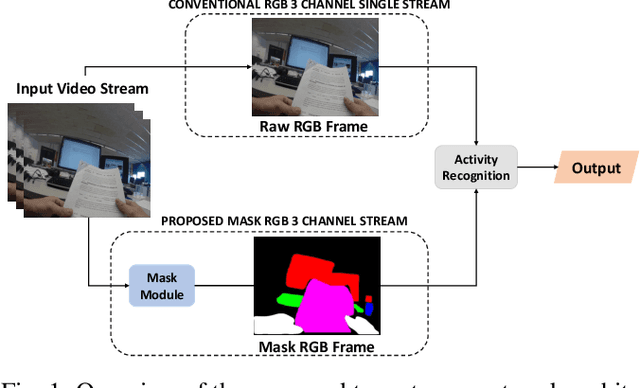

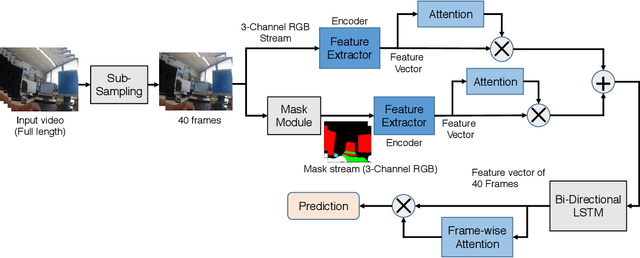
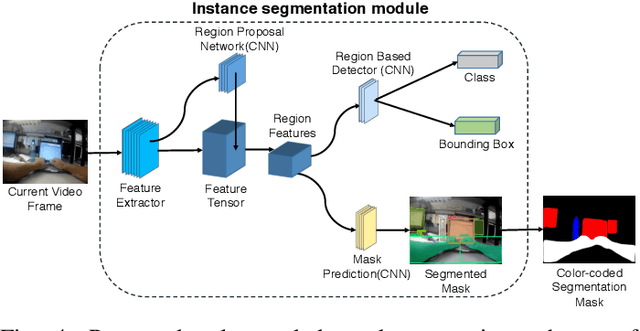
Activity detection from first-person videos (FPV) captured using a wearable camera is an active research field with potential applications in many sectors, including healthcare, law enforcement, and rehabilitation. State-of-the-art methods use optical flow-based hybrid techniques that rely on features derived from the motion of objects from consecutive frames. In this work, we developed a two-stream network, the \emph{SegCodeNet}, that uses a network branch containing video-streams with color-coded semantic segmentation masks of relevant objects in addition to the original RGB video-stream. We also include a stream-wise attention gating that prioritizes between the two streams and a frame-wise attention module that prioritizes the video frames that contain relevant features. Experiments are conducted on an FPV dataset containing $18$ activity classes in office environments. In comparison to a single-stream network, the proposed two-stream method achieves an absolute improvement of $14.366\%$ and $10.324\%$ for averaged F1 score and accuracy, respectively, when average results are compared for three different frame sizes $224\times224$, $112\times112$, and $64\times64$. The proposed method provides significant performance gains for lower-resolution images with absolute improvements of $17\%$ and $26\%$ in F1 score for input dimensions of $112\times112$ and $64\times64$, respectively. The best performance is achieved for a frame size of $224\times224$ yielding an F1 score and accuracy of $90.176\%$ and $90.799\%$ which outperforms the state-of-the-art Inflated 3D ConvNet (I3D) \cite{carreira2017quo} method by an absolute margin of $4.529\%$ and $2.419\%$, respectively.
Privacy-Aware Activity Classification from First Person Office Videos
Jun 11, 2020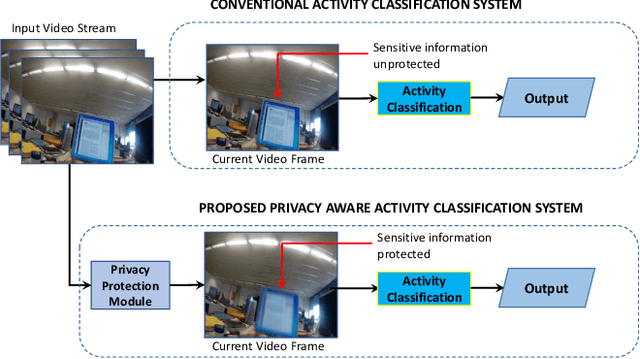

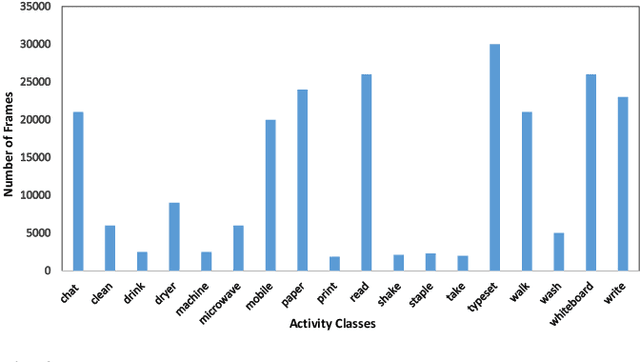

In the advent of wearable body-cameras, human activity classification from First-Person Videos (FPV) has become a topic of increasing importance for various applications, including in life-logging, law-enforcement, sports, workplace, and healthcare. One of the challenging aspects of FPV is its exposure to potentially sensitive objects within the user's field of view. In this work, we developed a privacy-aware activity classification system focusing on office videos. We utilized a Mask-RCNN with an Inception-ResNet hybrid as a feature extractor for detecting, and then blurring out sensitive objects (e.g., digital screens, human face, paper) from the videos. For activity classification, we incorporate an ensemble of Recurrent Neural Networks (RNNs) with ResNet, ResNext, and DenseNet based feature extractors. The proposed system was trained and evaluated on the FPV office video dataset that includes 18-classes made available through the IEEE Video and Image Processing (VIP) Cup 2019 competition. On the original unprotected FPVs, the proposed activity classifier ensemble reached an accuracy of 85.078% with precision, recall, and F1 scores of 0.88, 0.85 & 0.86, respectively. On privacy protected videos, the performances were slightly degraded, with accuracy, precision, recall, and F1 scores at 73.68%, 0.79, 0.75, and 0.74, respectively. The presented system won the 3rd prize in the IEEE VIP Cup 2019 competition.