 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAVEN: Radar Adaptive Vision Encoders for Efficient Chirp-wise Object Detection and Segmentation
Apr 06, 2026This paper presents RAVEN, a computationally efficient deep learning architecture for FMCW radar perception. The method processes raw ADC data in a chirp-wise streaming manner, preserves MIMO structure through independent receiver state-space encoders, and uses a learnable cross-antenna mixing module to recover compact virtual-array features. It also introduces an early-exit mechanism so the model can make decisions using only a subset of chirps when the latent state has stabilized. Across automotive radar benchmarks, the approach reports strong object detection and BEV free-space segmentation performance while substantially reducing computation and end-to-end latency compared with conventional frame-based radar pipelines.
* CVPR submission / conference paper
SSMRadNet : A Sample-wise State-Space Framework for Efficient and Ultra-Light Radar Segmentation and Object Detection
Nov 11, 2025



We introduce SSMRadNet, the first multi-scale State Space Model (SSM) based detector for Frequency Modulated Continuous Wave (FMCW) radar that sequentially processes raw ADC samples through two SSMs. One SSM learns a chirp-wise feature by sequentially processing samples from all receiver channels within one chirp, and a second SSM learns a representation of a frame by sequentially processing chirp-wise features. The latent representations of a radar frame are decoded to perform segmentation and detection tasks. Comprehensive evaluations on the RADIal dataset show SSMRadNet has 10-33x fewer parameters and 60-88x less computation (GFLOPs) while being 3.7x faster than state-of-the-art transformer and convolution-based radar detectors at competitive performance for segmentation tasks.
BanglaNum -- A Public Dataset for Bengali Digit Recognition from Speech
Mar 20, 2024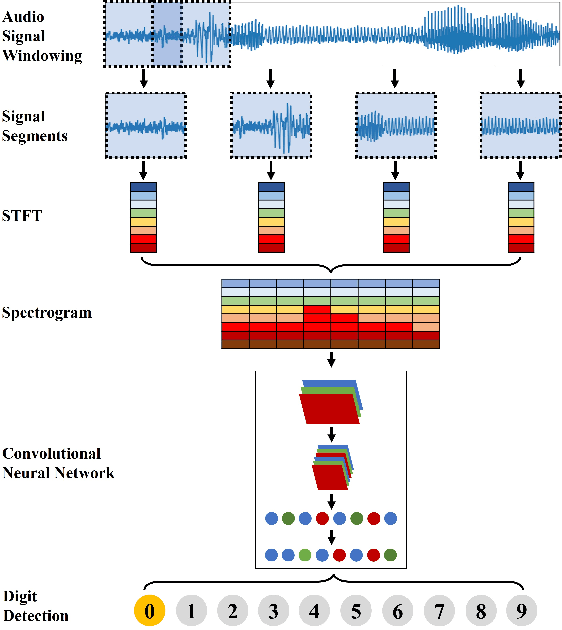
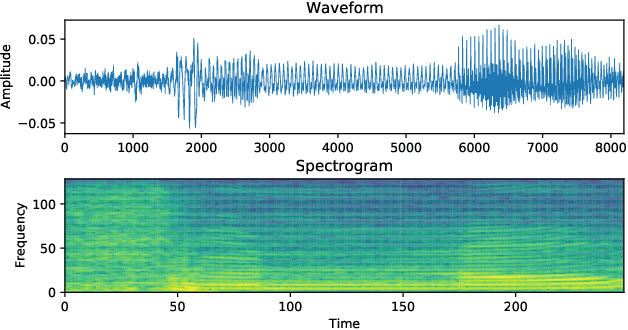
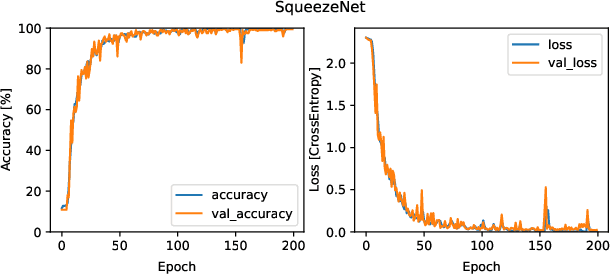
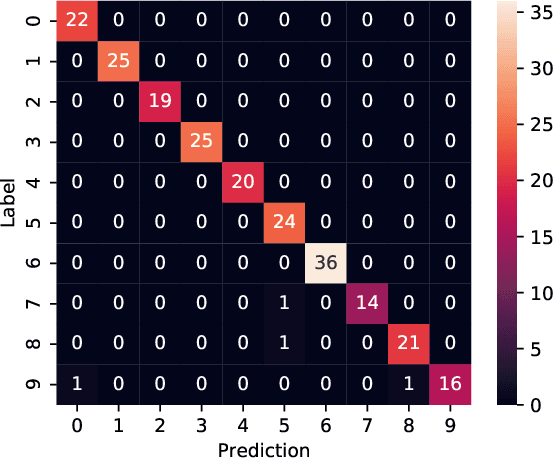
Automatic speech recognition (ASR) converts the human voice into readily understandable and categorized text or words. Although Bengali is one of the most widely spoken languages in the world, there have been very few studies on Bengali ASR, particularly on Bangladeshi-accented Bengali. In this study, audio recordings of spoken digits (0-9) from university students were used to create a Bengali speech digits dataset that may be employed to train artificial neural networks for voice-based digital input systems. This paper also compares the Bengali digit recognition accuracy of several Convolutional Neural Networks (CNNs) using spectrograms and shows that a test accuracy of 98.23% is achievable using parameter-efficient models such as SqueezeNet on our dataset.
A Sequence Agnostic Multimodal Preprocessing for Clogged Blood Vessel Detection in Alzheimer's Diagnosis
Nov 06, 2022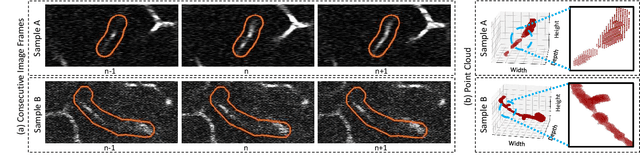
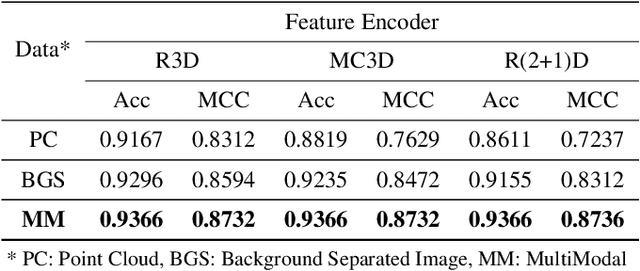

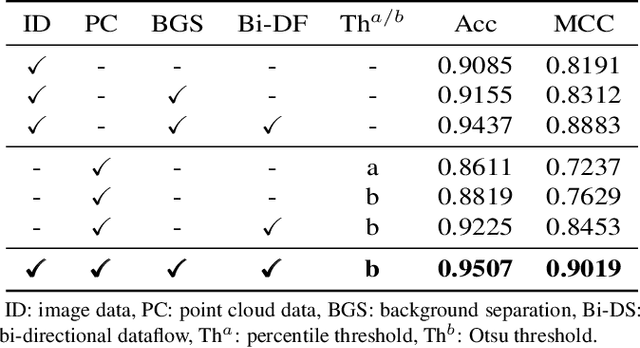
Successful identification of blood vessel blockage is a crucial step for Alzheimer's disease diagnosis. These blocks can be identified from the spatial and time-depth variable Two-Photon Excitation Microscopy (TPEF) images of the brain blood vessels using machine learning methods. In this study, we propose several preprocessing schemes to improve the performance of these methods. Our method includes 3D-point cloud data extraction from image modality and their feature-space fusion to leverage complementary information inherent in different modalities. We also enforce the learned representation to be sequence-order invariant by utilizing bi-direction dataflow. Experimental results on The Clog Loss dataset show that our proposed method consistently outperforms the state-of-the-art preprocessing methods in stalled and non-stalled vessel classification.