 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation-Aware Unlearning via Activation Signatures: From Suppression to Knowledge-Signature Erasure
Jan 15, 2026Selective knowledge erasure from LLMs is critical for GDPR compliance and model safety, yet current unlearning methods conflate behavioral suppression with true knowledge removal, allowing latent capabilities to persist beneath surface-level refusals. In this work, we address this challenge by introducing Knowledge Immunization Framework (KIF), a representation-aware architecture that distinguishes genuine erasure from obfuscation by targeting internal activation signatures rather than surface outputs. Our approach combines dynamic suppression of subject-specific representations with parameter-efficient adaptation, enabling durable unlearning without full model retraining. KIF achieves near-oracle erasure (FQ approx 0.99 vs. 1.00) while preserving utility at oracle levels (MU = 0.62), effectively breaking the stability-erasure tradeoff that has constrained all prior work. We evaluate both standard foundation models (Llama and Mistral) and reasoning-prior models (Qwen and DeepSeek) across 3B to 14B parameters. Our observation shows that standard models exhibit scale-independent true erasure (<3% utility drift), while reasoning-prior models reveal fundamental architectural divergence. Our comprehensive dual-metric evaluation protocol, combining surface-level leakage with latent trace persistence, operationalizes the obfuscation - erasure distinction and enables the first systematic diagnosis of mechanism-level forgetting behavior across model families and scales.
Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks
May 29, 2025Object orientation understanding represents a fundamental challenge in visual perception critical for applications like robotic manipulation and augmented reality. Current vision-language benchmarks fail to isolate this capability, often conflating it with positional relationships and general scene understanding. We introduce DORI (Discriminative Orientation Reasoning Intelligence), a comprehensive benchmark establishing object orientation perception as a primary evaluation target. DORI assesses four dimensions of orientation comprehension: frontal alignment, rotational transformations, relative directional relationships, and canonical orientation understanding. Through carefully curated tasks from 11 datasets spanning 67 object categories across synthetic and real-world scenarios, DORI provides insights on how multi-modal systems understand object orientations. Our evaluation of 15 state-of-the-art vision-language models reveals critical limitations: even the best models achieve only 54.2% accuracy on coarse tasks and 33.0% on granular orientation judgments, with performance deteriorating for tasks requiring reference frame shifts or compound rotations. These findings demonstrate the need for dedicated orientation representation mechanisms, as models show systematic inability to perform precise angular estimations, track orientation changes across viewpoints, and understand compound rotations - suggesting limitations in their internal 3D spatial representations. As the first diagnostic framework specifically designed for orientation awareness in multimodal systems, DORI offers implications for improving robotic control, 3D scene reconstruction, and human-AI interaction in physical environments. DORI data: https://huggingface.co/datasets/appledora/DORI-Benchmark
RECAST: Reparameterized, Compact weight Adaptation for Sequential Tasks
Nov 25, 2024Incremental learning aims to adapt to new sets of categories over time with minimal computational overhead. Prior work often addresses this task by training efficient task-specific adaptors that modify frozen layer weights or features to capture relevant information without affecting predictions on previously learned categories. While these adaptors are generally more efficient than finetuning the entire network, they still require tens to hundreds of thousands of task-specific trainable parameters even for relatively small networks, making it challenging to operate on resource-constrained environments with high communication costs like edge devices or mobile phones. Thus, we propose Reparameterized, Compact weight Adaptation for Sequential Tasks (RECAST), a novel method that dramatically reduces task-specific trainable parameters to fewer than 50 - several orders of magnitude less than competing methods like LoRA. RECAST accomplishes this efficiency by learning to decompose layer weights into a soft parameter-sharing framework consisting of shared weight templates and very few module-specific scaling factors or coefficients. This soft parameter-sharing framework allows for effective task-wise reparameterization by tuning only these coefficients while keeping templates frozen.A key innovation of RECAST is the novel weight reconstruction pipeline called Neural Mimicry, which eliminates the need for pretraining from scratch. This allows for high-fidelity emulation of existing pretrained weights within our framework and provides quick adaptability to any model scale and architecture. Extensive experiments across six datasets demonstrate RECAST outperforms the state-of-the-art by up to 3% across various scales, architectures, and parameter spaces Moreover, we show that RECAST's architecture-agnostic nature allows for seamless integration with existing methods, further boosting performance.
Integrating A.I. in Higher Education: Protocol for a Pilot Study with 'SAMCares: An Adaptive Learning Hub'
May 01, 2024Learning never ends, and there is no age limit to grow yourself. However, the educational landscape may face challenges in effectively catering to students' inclusion and diverse learning needs. These students should have access to state-of-the-art methods for lecture delivery, online resources, and technology needs. However, with all the diverse learning sources, it becomes harder for students to comprehend a large amount of knowledge in a short period of time. Traditional assistive technologies and learning aids often lack the dynamic adaptability required for individualized education plans. Large Language Models (LLM) have been used in language translation, text summarization, and content generation applications. With rapid growth in AI over the past years, AI-powered chatbots and virtual assistants have been developed. This research aims to bridge this gap by introducing an innovative study buddy we will be calling the 'SAMCares'. The system leverages a Large Language Model (LLM) (in our case, LLaMa-2 70B as the base model) and Retriever-Augmented Generation (RAG) to offer real-time, context-aware, and adaptive educational support. The context of the model will be limited to the knowledge base of Sam Houston State University (SHSU) course notes. The LLM component enables a chat-like environment to interact with it to meet the unique learning requirements of each student. For this, we will build a custom web-based GUI. At the same time, RAG enhances real-time information retrieval and text generation, in turn providing more accurate and context-specific assistance. An option to upload additional study materials in the web GUI is added in case additional knowledge support is required. The system's efficacy will be evaluated through controlled trials and iterative feedback mechanisms.
Mapping Violence: Developing an Extensive Framework to Build a Bangla Sectarian Expression Dataset from Social Media Interactions
Apr 17, 2024Communal violence in online forums has become extremely prevalent in South Asia, where many communities of different cultures coexist and share resources. These societies exhibit a phenomenon characterized by strong bonds within their own groups and animosity towards others, leading to conflicts that frequently escalate into violent confrontations. To address this issue, we have developed the first comprehensive framework for the automatic detection of communal violence markers in online Bangla content accompanying the largest collection (13K raw sentences) of social media interactions that fall under the definition of four major violence class and their 16 coarse expressions. Our workflow introduces a 7-step expert annotation process incorporating insights from social scientists, linguists, and psychologists. By presenting data statistics and benchmarking performance using this dataset, we have determined that, aside from the category of Non-communal violence, Religio-communal violence is particularly pervasive in Bangla text. Moreover, we have substantiated the effectiveness of fine-tuning language models in identifying violent comments by conducting preliminary benchmarking on the state-of-the-art Bangla deep learning model.
Vision-LLMs Can Fool Themselves with Self-Generated Typographic Attacks
Feb 01, 2024


Recently, significant progress has been made on Large Vision-Language Models (LVLMs); a new class of VL models that make use of large pre-trained language models. Yet, their vulnerability to Typographic attacks, which involve superimposing misleading text onto an image remain unstudied. Furthermore, prior work typographic attacks rely on sampling a random misleading class from a predefined set of classes. However, the random chosen class might not be the most effective attack. To address these issues, we first introduce a novel benchmark uniquely designed to test LVLMs vulnerability to typographic attacks. Furthermore, we introduce a new and more effective typographic attack: Self-Generated typographic attacks. Indeed, our method, given an image, make use of the strong language capabilities of models like GPT-4V by simply prompting them to recommend a typographic attack. Using our novel benchmark, we uncover that typographic attacks represent a significant threat against LVLM(s). Furthermore, we uncover that typographic attacks recommended by GPT-4V using our new method are not only more effective against GPT-4V itself compared to prior work attacks, but also against a host of less capable yet popular open source models like LLaVA, InstructBLIP, and MiniGPT4.
OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution Benchmarking
May 15, 2023We present OOD-Speech, the first out-of-distribution (OOD) benchmarking dataset for Bengali automatic speech recognition (ASR). Being one of the most spoken languages globally, Bengali portrays large diversity in dialects and prosodic features, which demands ASR frameworks to be robust towards distribution shifts. For example, islamic religious sermons in Bengali are delivered with a tonality that is significantly different from regular speech. Our training dataset is collected via massively online crowdsourcing campaigns which resulted in 1177.94 hours collected and curated from $22,645$ native Bengali speakers from South Asia. Our test dataset comprises 23.03 hours of speech collected and manually annotated from 17 different sources, e.g., Bengali TV drama, Audiobook, Talk show, Online class, and Islamic sermons to name a few. OOD-Speech is jointly the largest publicly available speech dataset, as well as the first out-of-distribution ASR benchmarking dataset for Bengali.
VISTA: Vision Transformer enhanced by U-Net and Image Colorfulness Frame Filtration for Automatic Retail Checkout
Apr 23, 2022


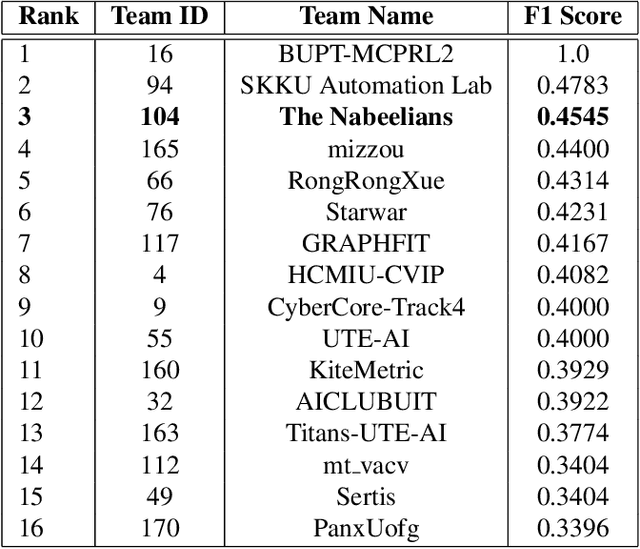
Multi-class product counting and recognition identifies product items from images or videos for automated retail checkout. The task is challenging due to the real-world scenario of occlusions where product items overlap, fast movement in the conveyor belt, large similarity in overall appearance of the items being scanned, novel products, and the negative impact of misidentifying items. Further, there is a domain bias between training and test sets, specifically, the provided training dataset consists of synthetic images and the test set videos consist of foreign objects such as hands and tray. To address these aforementioned issues, we propose to segment and classify individual frames from a video sequence. The segmentation method consists of a unified single product item- and hand-segmentation followed by entropy masking to address the domain bias problem. The multi-class classification method is based on Vision Transformers (ViT). To identify the frames with target objects, we utilize several image processing methods and propose a custom metric to discard frames not having any product items. Combining all these mechanisms, our best system achieves 3rd place in the AI City Challenge 2022 Track 4 with an F1 score of 0.4545. Code will be available at
TEAM-Atreides at SemEval-2022 Task 11: On leveraging data augmentation and ensemble to recognize complex Named Entities in Bangla
Apr 21, 2022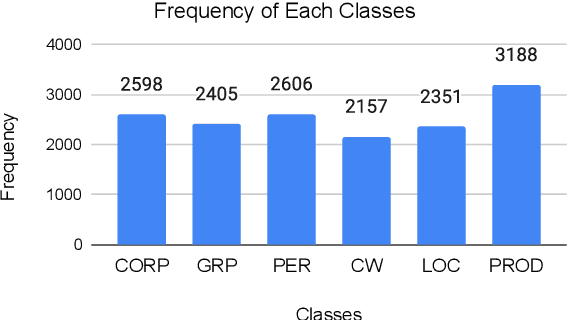

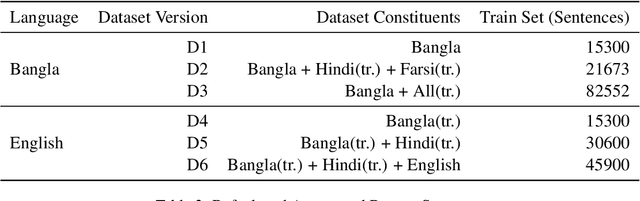
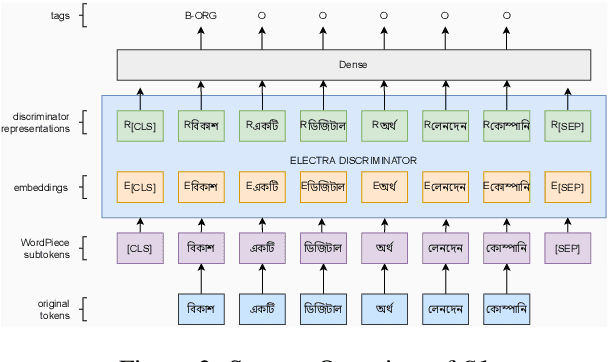
Many areas, such as the biological and healthcare domain, artistic works, and organization names, have nested, overlapping, discontinuous entity mentions that may even be syntactically or semantically ambiguous in practice. Traditional sequence tagging algorithms are unable to recognize these complex mentions because they may violate the assumptions upon which sequence tagging schemes are founded. In this paper, we describe our contribution to SemEval 2022 Task 11 on identifying such complex Named Entities. We have leveraged the ensemble of multiple ELECTRA-based models that were exclusively pretrained on the Bangla language with the performance of ELECTRA-based models pretrained on English to achieve competitive performance on the Track-11. Besides providing a system description, we will also present the outcomes of our experiments on architectural decisions, dataset augmentations, and post-competition findings.