 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Vision Transformer enhanced by U-Net and Image Colorfulness Frame Filtration for Automatic Retail Checkout
Apr 23, 2022


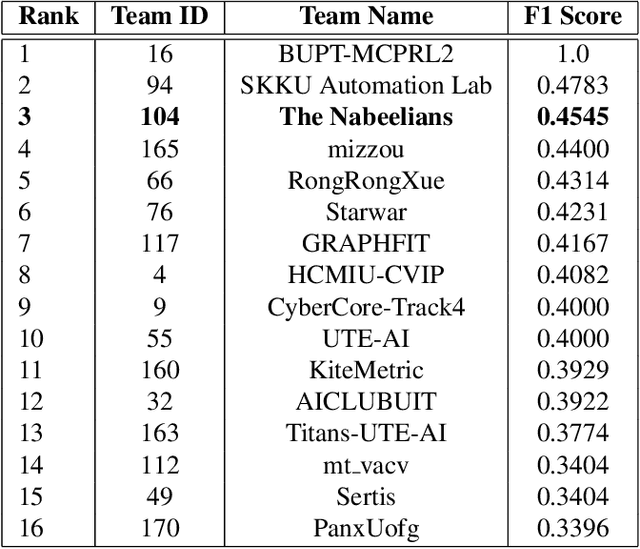
Multi-class product counting and recognition identifies product items from images or videos for automated retail checkout. The task is challenging due to the real-world scenario of occlusions where product items overlap, fast movement in the conveyor belt, large similarity in overall appearance of the items being scanned, novel products, and the negative impact of misidentifying items. Further, there is a domain bias between training and test sets, specifically, the provided training dataset consists of synthetic images and the test set videos consist of foreign objects such as hands and tray. To address these aforementioned issues, we propose to segment and classify individual frames from a video sequence. The segmentation method consists of a unified single product item- and hand-segmentation followed by entropy masking to address the domain bias problem. The multi-class classification method is based on Vision Transformers (ViT). To identify the frames with target objects, we utilize several image processing methods and propose a custom metric to discard frames not having any product items. Combining all these mechanisms, our best system achieves 3rd place in the AI City Challenge 2022 Track 4 with an F1 score of 0.4545. Code will be available at
Cartoon-to-real: An Approach to Translate Cartoon to Realistic Images using GAN
Nov 28, 2018

We propose a method to translate cartoon images to real world images using Generative Aderserial Network (GAN). Existing GAN-based image-to-image translation methods which are trained on paired datasets are impractical as the data is difficult to accumulate. Therefore, in this paper we exploit the Cycle-Consistent Adversarial Networks (CycleGAN) method for images translation which needs an unpaired dataset. By applying CycleGAN we show that our model is able to generate meaningful real world images from cartoon images. However, we implement another state of the art technique $-$ Deep Analogy $-$ to compare the performance of our approach.