 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeam Carving as Feature Pooling in CNN
Sep 10, 2024This work investigates the potential of seam carving as a feature pooling technique within Convolutional Neural Networks (CNNs) for image classification tasks. We propose replacing the traditional max pooling layer with a seam carving operation. Our experiments on the Caltech-UCSD Birds 200-2011 dataset demonstrate that the seam carving-based CNN achieves better performance compared to the model utilizing max pooling, based on metrics such as accuracy, precision, recall, and F1-score. We further analyze the behavior of both approaches through feature map visualizations, suggesting that seam carving might preserve more structural information during the pooling process. Additionally, we discuss the limitations of our approach and propose potential future directions for research.
Jamdani Motif Generation using Conditional GAN
Dec 22, 2022



Jamdani is the strikingly patterned textile heritage of Bangladesh. The exclusive geometric motifs woven on the fabric are the most attractive part of this craftsmanship having a remarkable influence on textile and fine art. In this paper, we have developed a technique based on the Generative Adversarial Network that can learn to generate entirely new Jamdani patterns from a collection of Jamdani motifs that we assembled, the newly formed motifs can mimic the appearance of the original designs. Users can input the skeleton of a desired pattern in terms of rough strokes and our system finalizes the input by generating the complete motif which follows the geometric structure of real Jamdani ones. To serve this purpose, we collected and preprocessed a dataset containing a large number of Jamdani motifs images from authentic sources via fieldwork and applied a state-of-the-art method called pix2pix to it. To the best of our knowledge, this dataset is currently the only available dataset of Jamdani motifs in digital format for computer vision research. Our experimental results of the pix2pix model on this dataset show satisfactory outputs of computer-generated images of Jamdani motifs and we believe that our work will open a new avenue for further research.
Shapes2Toon: Generating Cartoon Characters from Simple Geometric Shapes
Nov 03, 2022Cartoons are an important part of our entertainment culture. Though drawing a cartoon is not for everyone, creating it using an arrangement of basic geometric primitives that approximates that character is a fairly frequent technique in art. The key motivation behind this technique is that human bodies - as well as cartoon figures - can be split down into various basic geometric primitives. Numerous tutorials are available that demonstrate how to draw figures using an appropriate arrangement of fundamental shapes, thus assisting us in creating cartoon characters. This technique is very beneficial for children in terms of teaching them how to draw cartoons. In this paper, we develop a tool - shape2toon - that aims to automate this approach by utilizing a generative adversarial network which combines geometric primitives (i.e. circles) and generate a cartoon figure (i.e. Mickey Mouse) depending on the given approximation. For this purpose, we created a dataset of geometrically represented cartoon characters. We apply an image-to-image translation technique on our dataset and report the results in this paper. The experimental results show that our system can generate cartoon characters from input layout of geometric shapes. In addition, we demonstrate a web-based tool as a practical implication of our work.
Book Cover Synthesis from the Summary
Nov 03, 2022The cover is the face of a book and is a point of attraction for the readers. Designing book covers is an essential task in the publishing industry. One of the main challenges in creating a book cover is representing the theme of the book's content in a single image. In this research, we explore ways to produce a book cover using artificial intelligence based on the fact that there exists a relationship between the summary of the book and its cover. Our key motivation is the application of text-to-image synthesis methods to generate images from given text or captions. We explore several existing text-to-image conversion techniques for this purpose and propose an approach to exploit these frameworks for producing book covers from provided summaries. We construct a dataset of English books that contains a large number of samples of summaries of existing books and their cover images. In this paper, we describe our approach to collecting, organizing, and pre-processing the dataset to use it for training models. We apply different text-to-image synthesis techniques to generate book covers from the summary and exhibit the results in this paper.
PerSign: Personalized Bangladeshi Sign Letters Synthesis
Sep 29, 2022
Bangladeshi Sign Language (BdSL) - like other sign languages - is tough to learn for general people, especially when it comes to expressing letters. In this poster, we propose PerSign, a system that can reproduce a person's image by introducing sign gestures in it. We make this operation personalized, which means the generated image keeps the person's initial image profile - face, skin tone, attire, background - unchanged while altering the hand, palm, and finger positions appropriately. We use an image-to-image translation technique and build a corresponding unique dataset to accomplish the task. We believe the translated image can reduce the communication gap between signers (person who uses sign language) and non-signers without having prior knowledge of BdSL.
DIY Graphics Tab: A Cost-Effective Alternative to Graphics Tablet for Educators
Dec 05, 2021


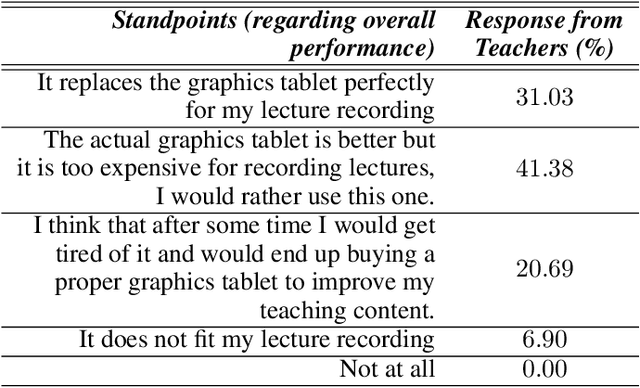
Everyday, more and more people are turning to online learning, which has altered our traditional classroom method. Recording lectures has always been a normal task for online educators, and it has lately become even more important during the epidemic because actual lessons are still being postponed in several countries. When recording lectures, a graphics tablet is a great substitute for a whiteboard because of its portability and ability to interface with computers. This graphic tablet, however, is too expensive for the majority of instructors. In this paper, we propose a computer vision-based alternative to the graphics tablet for instructors and educators, which functions largely in the same way as a graphic tablet but just requires a pen, paper, and a laptop's webcam. We call it "Do-It-Yourself Graphics Tab" or "DIY Graphics Tab". Our system receives a sequence of images of a person's writing on paper acquired by a camera as input and outputs the screen containing the contents of the writing from the paper. The task is not straightforward since there are many obstacles such as occlusion due to the person's hand, random movement of the paper, poor lighting condition, perspective distortion due to the angle of view, etc. A pipeline is used to route the input recording through our system, which conducts instance segmentation and preprocessing before generating the appropriate output. We also conducted user experience evaluations from the teachers and students, and their responses are examined in this paper.
Altering Facial Expression Based on Textual Emotion
Dec 02, 2021

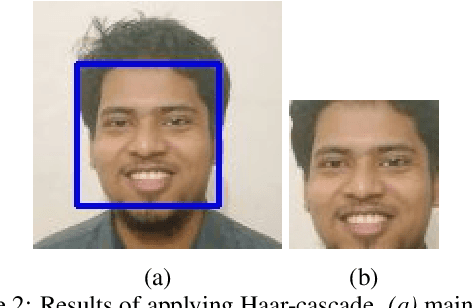

Faces and their expressions are one of the potent subjects for digital images. Detecting emotions from images is an ancient task in the field of computer vision; however, performing its reverse -- synthesizing facial expressions from images -- is quite new. Such operations of regenerating images with different facial expressions, or altering an existing expression in an image require the Generative Adversarial Network (GAN). In this paper, we aim to change the facial expression in an image using GAN, where the input image with an initial expression (i.e., happy) is altered to a different expression (i.e., disgusted) for the same person. We used StarGAN techniques on a modified version of the MUG dataset to accomplish this objective. Moreover, we extended our work further by remodeling facial expressions in an image indicated by the emotion from a given text. As a result, we applied a Long Short-Term Memory (LSTM) method to extract emotion from the text and forwarded it to our expression-altering module. As a demonstration of our working pipeline, we also create an application prototype of a blog that regenerates the profile picture with different expressions based on the user's textual emotion.
BdSL36: A Dataset for Bangladeshi Sign Letters Recognition
Oct 02, 2021
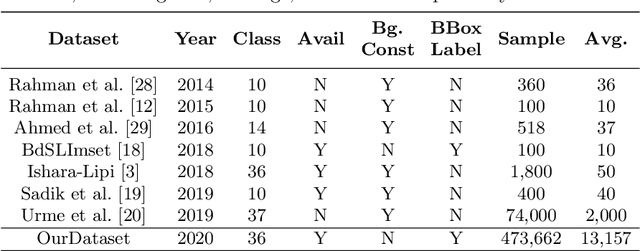

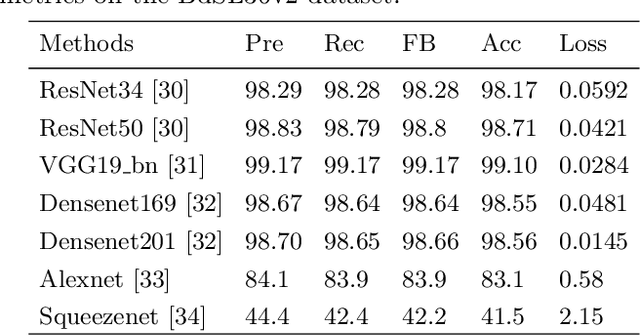
Bangladeshi Sign Language (BdSL) is a commonly used medium of communication for the hearing-impaired people in Bangladesh. A real-time BdSL interpreter with no controlled lab environment has a broad social impact and an interesting avenue of research as well. Also, it is a challenging task due to the variation in different subjects (age, gender, color, etc.), complex features, and similarities of signs and clustered backgrounds. However, the existing dataset for BdSL classification task is mainly built in a lab friendly setup which limits the application of powerful deep learning technology. In this paper, we introduce a dataset named BdSL36 which incorporates background augmentation to make the dataset versatile and contains over four million images belonging to 36 categories. Besides, we annotate about 40,000 images with bounding boxes to utilize the potentiality of object detection algorithms. Furthermore, several intensive experiments are performed to establish the baseline performance of our BdSL36. Moreover, we employ beta testing of our classifiers at the user level to justify the possibilities of real-world application with this dataset. We believe our BdSL36 will expedite future research on practical sign letter classification. We make the datasets and all the pre-trained models available for further researcher.
toon2real: Translating Cartoon Images to Realistic Images
Feb 01, 2021
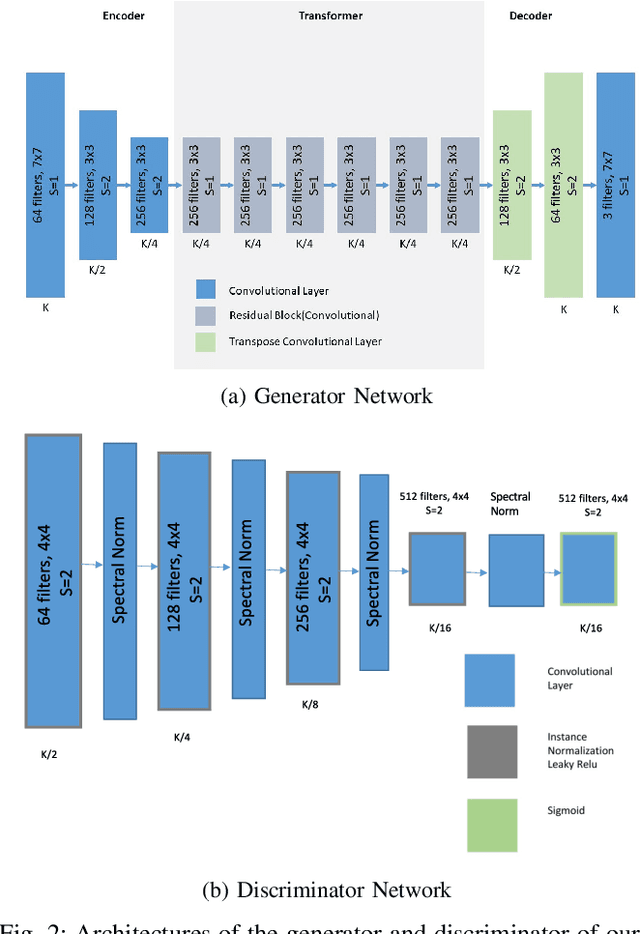

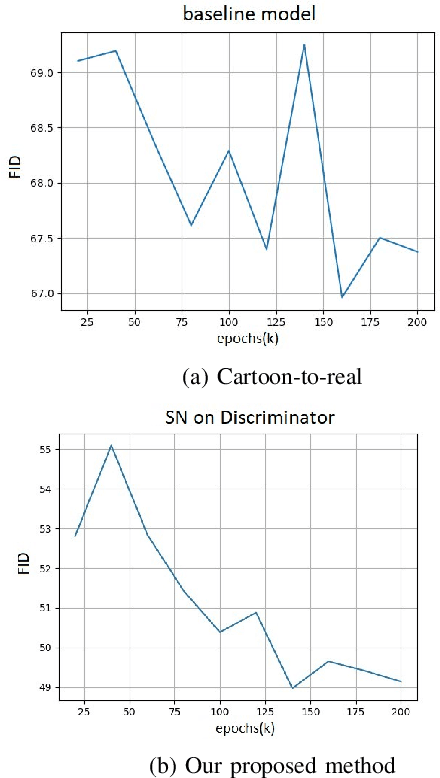
In terms of Image-to-image translation, Generative Adversarial Networks (GANs) has achieved great success even when it is used in the unsupervised dataset. In this work, we aim to translate cartoon images to photo-realistic images using GAN. We apply several state-of-the-art models to perform this task; however, they fail to perform good quality translations. We observe that the shallow difference between these two domains causes this issue. Based on this idea, we propose a method based on CycleGAN model for image translation from cartoon domain to photo-realistic domain. To make our model efficient, we implemented Spectral Normalization which added stability in our model. We demonstrate our experimental results and show that our proposed model has achieved the lowest Frechet Inception Distance score and better results compared to another state-of-the-art technique, UNIT.
Real Time Bangladeshi Sign Language Detection using Faster R-CNN
Nov 30, 2018
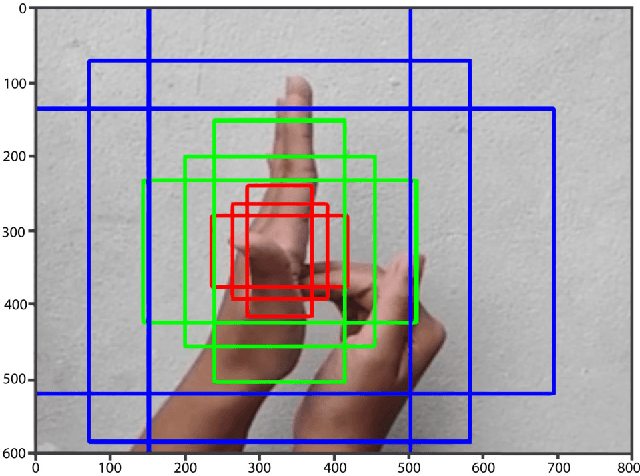


Bangladeshi Sign Language (BdSL) is a commonly used medium of communication for the hearing-impaired people in Bangladesh. Developing a real time system to detect these signs from images is a great challenge. In this paper, we present a technique to detect BdSL from images that performs in real time. Our method uses Convolutional Neural Network based object detection technique to detect the presence of signs in the image region and to recognize its class. For this purpose, we adopted Faster Region-based Convolutional Network approach and developed a dataset $-$ BdSLImset $-$ to train our system. Previous research works in detecting BdSL generally depend on external devices while most of the other vision-based techniques do not perform efficiently in real time. Our approach, however, is free from such limitations and the experimental results demonstrate that the proposed method successfully identifies and recognizes Bangladeshi signs in real time.