 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIY Graphics Tab: A Cost-Effective Alternative to Graphics Tablet for Educators
Dec 05, 2021


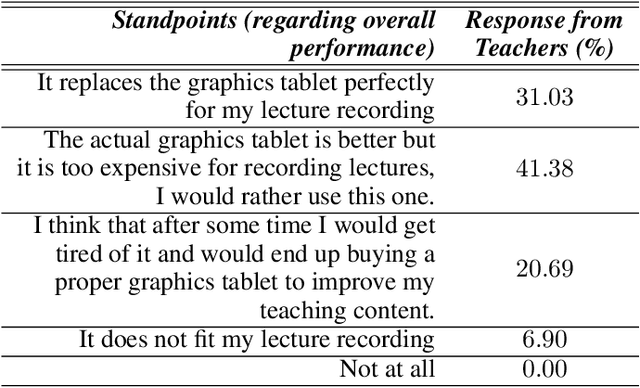
Everyday, more and more people are turning to online learning, which has altered our traditional classroom method. Recording lectures has always been a normal task for online educators, and it has lately become even more important during the epidemic because actual lessons are still being postponed in several countries. When recording lectures, a graphics tablet is a great substitute for a whiteboard because of its portability and ability to interface with computers. This graphic tablet, however, is too expensive for the majority of instructors. In this paper, we propose a computer vision-based alternative to the graphics tablet for instructors and educators, which functions largely in the same way as a graphic tablet but just requires a pen, paper, and a laptop's webcam. We call it "Do-It-Yourself Graphics Tab" or "DIY Graphics Tab". Our system receives a sequence of images of a person's writing on paper acquired by a camera as input and outputs the screen containing the contents of the writing from the paper. The task is not straightforward since there are many obstacles such as occlusion due to the person's hand, random movement of the paper, poor lighting condition, perspective distortion due to the angle of view, etc. A pipeline is used to route the input recording through our system, which conducts instance segmentation and preprocessing before generating the appropriate output. We also conducted user experience evaluations from the teachers and students, and their responses are examined in this paper.
Altering Facial Expression Based on Textual Emotion
Dec 02, 2021

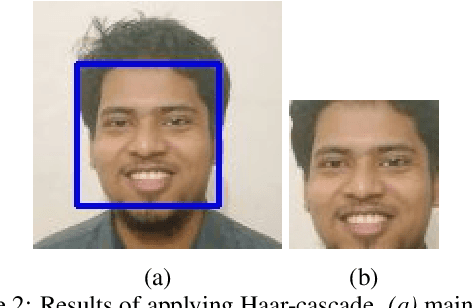

Faces and their expressions are one of the potent subjects for digital images. Detecting emotions from images is an ancient task in the field of computer vision; however, performing its reverse -- synthesizing facial expressions from images -- is quite new. Such operations of regenerating images with different facial expressions, or altering an existing expression in an image require the Generative Adversarial Network (GAN). In this paper, we aim to change the facial expression in an image using GAN, where the input image with an initial expression (i.e., happy) is altered to a different expression (i.e., disgusted) for the same person. We used StarGAN techniques on a modified version of the MUG dataset to accomplish this objective. Moreover, we extended our work further by remodeling facial expressions in an image indicated by the emotion from a given text. As a result, we applied a Long Short-Term Memory (LSTM) method to extract emotion from the text and forwarded it to our expression-altering module. As a demonstration of our working pipeline, we also create an application prototype of a blog that regenerates the profile picture with different expressions based on the user's textual emotion.