 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEAM-Atreides at SemEval-2022 Task 11: On leveraging data augmentation and ensemble to recognize complex Named Entities in Bangla
Paper and Code
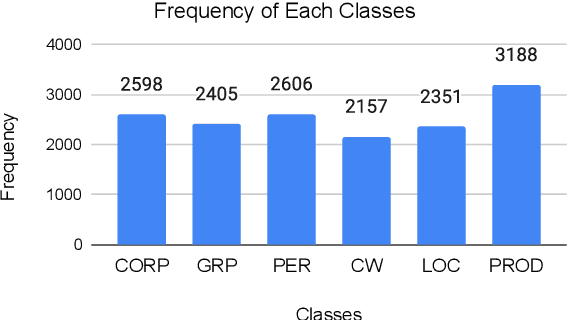

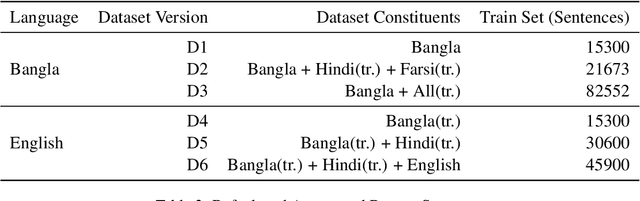
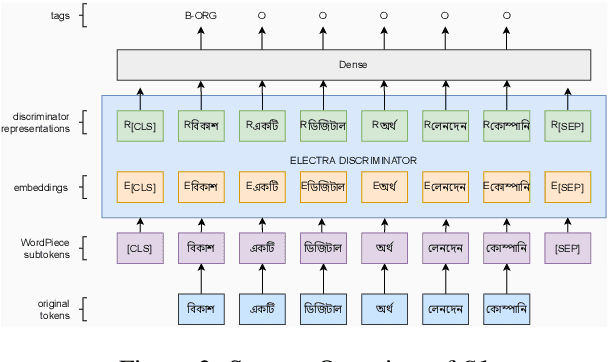
Many areas, such as the biological and healthcare domain, artistic works, and organization names, have nested, overlapping, discontinuous entity mentions that may even be syntactically or semantically ambiguous in practice. Traditional sequence tagging algorithms are unable to recognize these complex mentions because they may violate the assumptions upon which sequence tagging schemes are founded. In this paper, we describe our contribution to SemEval 2022 Task 11 on identifying such complex Named Entities. We have leveraged the ensemble of multiple ELECTRA-based models that were exclusively pretrained on the Bangla language with the performance of ELECTRA-based models pretrained on English to achieve competitive performance on the Track-11. Besides providing a system description, we will also present the outcomes of our experiments on architectural decisions, dataset augmentations, and post-competition findings.