 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label Classification of Common Bengali Handwritten Graphemes: Dataset and Challenge
Paper and Code
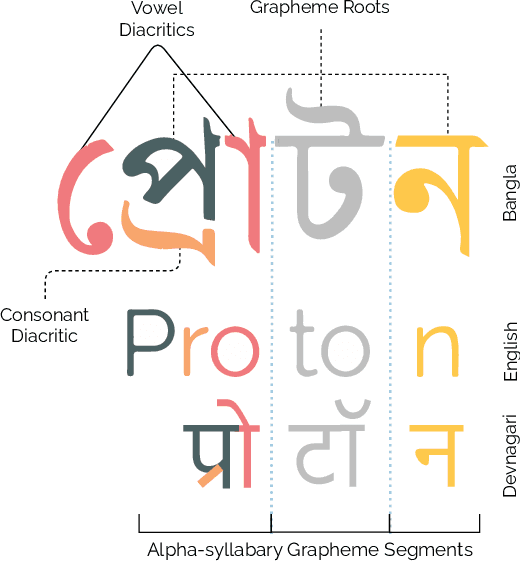



Latin has historically led the state-of-the-art in handwritten optical character recognition (OCR) research. Adapting existing systems from Latin to alpha-syllabary languages is particularly challenging due to a sharp contrast between their orthographies. The segmentation of graphical constituents corresponding to characters becomes significantly hard due to a cursive writing system and frequent use of diacritics in the alpha-syllabary family of languages. We propose a labeling scheme based on graphemes (linguistic segments of word formation) that makes segmentation inside alpha-syllabary words linear and present the first dataset of Bengali handwritten graphemes that are commonly used in an everyday context. The dataset is open-sourced as a part of the BengaliAI Handwritten Grapheme Classification Challenge on Kaggle to benchmark vision algorithms for multi-label grapheme classification. From competition proceedings, we see that deep learning methods can generalize to a large span of uncommon graphemes even when they are absent during training. Dataset and starter codes at www.kaggle.com/c/bengaliai-cv19.