Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Retrieval May Not Lead to Better Question Answering
Paper and Code
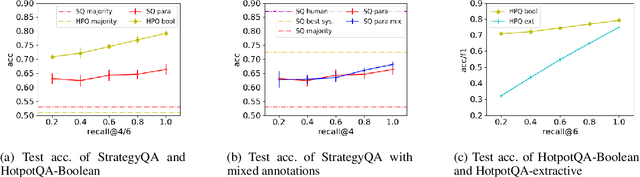



Considerable progress has been made recently in open-domain question answering (QA) problems, which require Information Retrieval (IR) and Reading Comprehension (RC). A popular approach to improve the system's performance is to improve the quality of the retrieved context from the IR stage. In this work we show that for StrategyQA, a challenging open-domain QA dataset that requires multi-hop reasoning, this common approach is surprisingly ineffective -- improving the quality of the retrieved context hardly improves the system's performance. We further analyze the system's behavior to identify potential reasons.
* 10 pages
View paper on