 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Travel in LLMs: Tracing Data Contamination in Large Language Models
Paper and Code
Aug 16, 2023


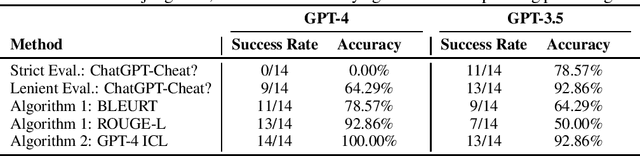
Data contamination, i.e., the presence of test data from downstream tasks in the training data of large language models (LLMs), is a potential major issue in understanding LLMs' effectiveness on other tasks. We propose a straightforward yet effective method for identifying data contamination within LLMs. At its core, our approach starts by identifying potential contamination in individual instances that are drawn from a small random sample; using this information, our approach then assesses if an entire dataset partition is contaminated. To estimate contamination of individual instances, we employ "guided instruction:" a prompt consisting of the dataset name, partition type, and the initial segment of a reference instance, asking the LLM to complete it. An instance is flagged as contaminated if the LLM's output either exactly or closely matches the latter segment of the reference. To understand if an entire partition is contaminated, we propose two ideas. The first idea marks a dataset partition as contaminated if the average overlap score with the reference instances (as measured by ROUGE or BLEURT) is statistically significantly better with the guided instruction vs. a general instruction that does not include the dataset and partition name. The second idea marks a dataset as contaminated if a classifier based on GPT-4 with in-context learning prompting marks multiple instances as contaminated. Our best method achieves an accuracy between 92% and 100% in detecting if an LLM is contaminated with seven datasets, containing train and test/validation partitions, when contrasted with manual evaluation by human expert. Further, our findings indicate that GPT-4 is contaminated with AG News, WNLI, and XSum datasets.