 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrading Massive Open Online Courses Using Large Language Models
Jun 16, 2024
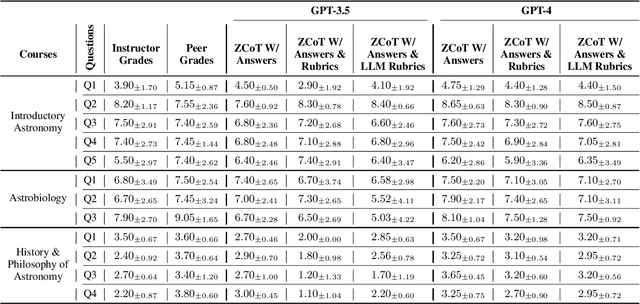

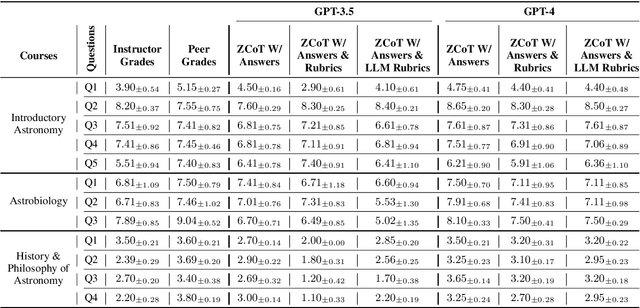
Massive open online courses (MOOCs) offer free education globally to anyone with a computer and internet access. Despite this democratization of learning, the massive enrollment in these courses makes it impractical for one instructor to assess every student's writing assignment. As a result, peer grading, often guided by a straightforward rubric, is the method of choice. While convenient, peer grading often falls short in terms of reliability and validity. In this study, we explore the feasibility of using large language models (LLMs) to replace peer grading in MOOCs. Specifically, we use two LLMs, GPT-4 and GPT-3.5, across three MOOCs: Introductory Astronomy, Astrobiology, and the History and Philosophy of Astronomy. To instruct LLMs, we use three different prompts based on the zero-shot chain-of-thought (ZCoT) prompting technique: (1) ZCoT with instructor-provided correct answers, (2) ZCoT with both instructor-provided correct answers and rubrics, and (3) ZCoT with instructor-provided correct answers and LLM-generated rubrics. Tested on 18 settings, our results show that ZCoT, when augmented with instructor-provided correct answers and rubrics, produces grades that are more aligned with those assigned by instructors compared to peer grading. Finally, our findings indicate a promising potential for automated grading systems in MOOCs, especially in subjects with well-defined rubrics, to improve the learning experience for millions of online learners worldwide.
Large Language Models As MOOCs Graders
Feb 10, 2024Massive open online courses (MOOCs) unlock the doors to free education for anyone around the globe with access to a computer and the internet. Despite this democratization of learning, the massive enrollment in these courses means it is almost impossible for one instructor to assess every student's writing assignment. As a result, peer grading, often guided by a straightforward rubric, is the method of choice. While convenient, peer grading often falls short in terms of reliability and validity. In this study, using 18 distinct settings, we explore the feasibility of leveraging large language models (LLMs) to replace peer grading in MOOCs. Specifically, we focus on two state-of-the-art LLMs: GPT-4 and GPT-3.5, across three distinct courses: Introductory Astronomy, Astrobiology, and the History and Philosophy of Astronomy. To instruct LLMs, we use three different prompts based on a variant of the zero-shot chain-of-thought (Zero-shot-CoT) prompting technique: Zero-shot-CoT combined with instructor-provided correct answers; Zero-shot-CoT in conjunction with both instructor-formulated answers and rubrics; and Zero-shot-CoT with instructor-offered correct answers and LLM-generated rubrics. Our results show that Zero-shot-CoT, when integrated with instructor-provided answers and rubrics, produces grades that are more aligned with those assigned by instructors compared to peer grading. However, the History and Philosophy of Astronomy course proves to be more challenging in terms of grading as opposed to other courses. Finally, our study reveals a promising direction for automating grading systems for MOOCs, especially in subjects with well-defined rubrics.