 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Contamination Quiz: A Tool to Detect and Estimate Contamination in Large Language Models
Paper and Code

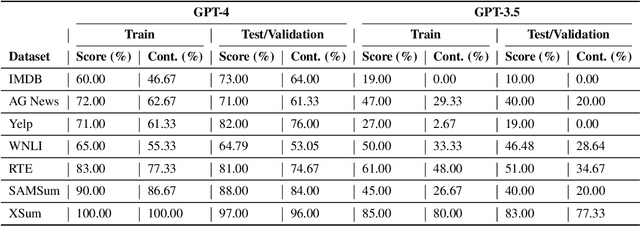

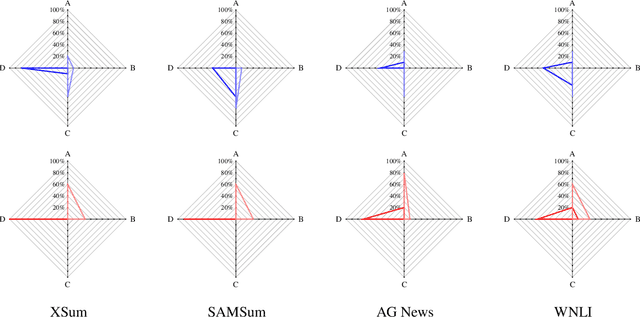
We propose the Data Contamination Quiz, a simple and effective approach to detect data contamination in large language models (LLMs) and estimate the amount of it. Specifically, we frame data contamination detection as a series of multiple-choice questions. We devise a quiz format wherein three perturbed versions of each dataset instance are created. These changes only include word-level perturbations, replacing words with their contextual synonyms, ensuring both the semantic and sentence structure remain exactly the same as the original instance. Together with the original instance, these perturbed versions constitute the choices in the quiz. Given that the only distinguishing signal among these choices is the exact wording, an LLM, when tasked with identifying the original instance from the choices, opts for the original if it has memorized it in its pre-training phase--a trait intrinsic to LLMs. A dataset partition is then marked as contaminated if the LLM's performance on the quiz surpasses what random chance suggests. Our evaluation spans seven datasets and their respective splits (train and test/validation) on two state-of-the-art LLMs: GPT-4 and GPT-3.5. While lacking access to the pre-training data, our results suggest that our approach not only enhances the detection of data contamination but also provides an accurate estimation of its extent, even when the contamination signal is weak.