 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Corpus-Based Approach for Building Semantic Lexicons
Paper and Code
Jun 10, 1997
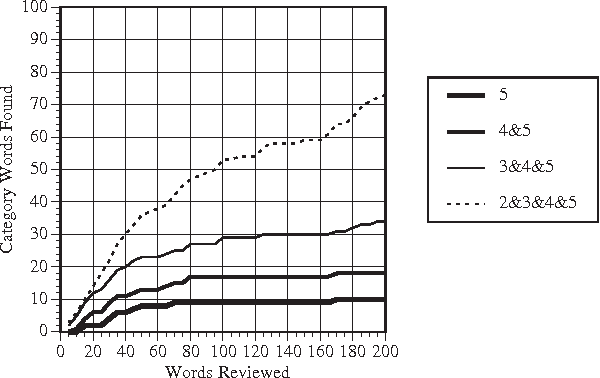
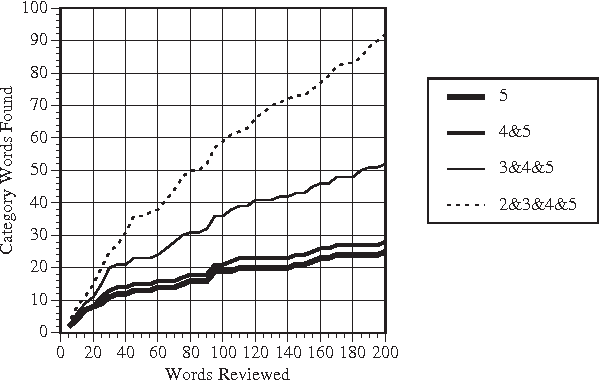
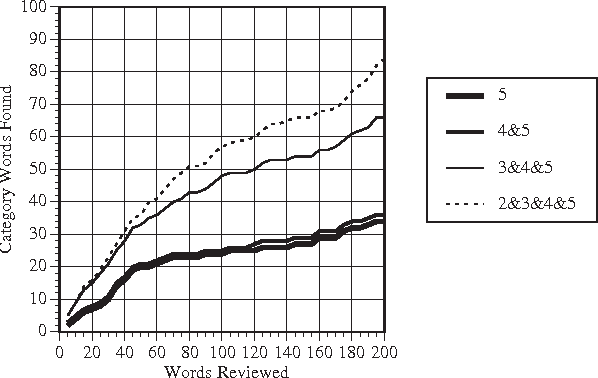
Semantic knowledge can be a great asset to natural language processing systems, but it is usually hand-coded for each application. Although some semantic information is available in general-purpose knowledge bases such as WordNet and Cyc, many applications require domain-specific lexicons that represent words and categories for a particular topic. In this paper, we present a corpus-based method that can be used to build semantic lexicons for specific categories. The input to the system is a small set of seed words for a category and a representative text corpus. The output is a ranked list of words that are associated with the category. A user then reviews the top-ranked words and decides which ones should be entered in the semantic lexicon. In experiments with five categories, users typically found about 60 words per category in 10-15 minutes to build a core semantic lexicon.