 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes the "most sinfully decadent cake ever" taste good? Answering Yes/No Questions from Figurative Contexts
Sep 24, 2023Figurative language is commonplace in natural language, and while making communication memorable and creative, can be difficult to understand. In this work, we investigate the robustness of Question Answering (QA) models on figurative text. Yes/no questions, in particular, are a useful probe of figurative language understanding capabilities of large language models. We propose FigurativeQA, a set of 1000 yes/no questions with figurative and non-figurative contexts, extracted from the domains of restaurant and product reviews. We show that state-of-the-art BERT-based QA models exhibit an average performance drop of up to 15\% points when answering questions from figurative contexts, as compared to non-figurative ones. While models like GPT-3 and ChatGPT are better at handling figurative texts, we show that further performance gains can be achieved by automatically simplifying the figurative contexts into their non-figurative (literal) counterparts. We find that the best overall model is ChatGPT with chain-of-thought prompting to generate non-figurative contexts. Our work provides a promising direction for building more robust QA models with figurative language understanding capabilities.
ASQ: Automatically Generating Question-Answer Pairs using AMRs
May 20, 2021
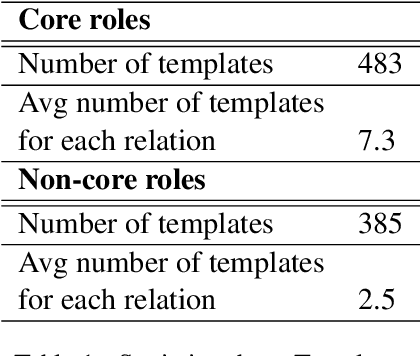
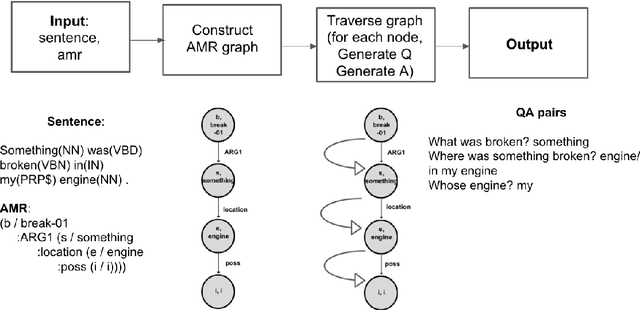
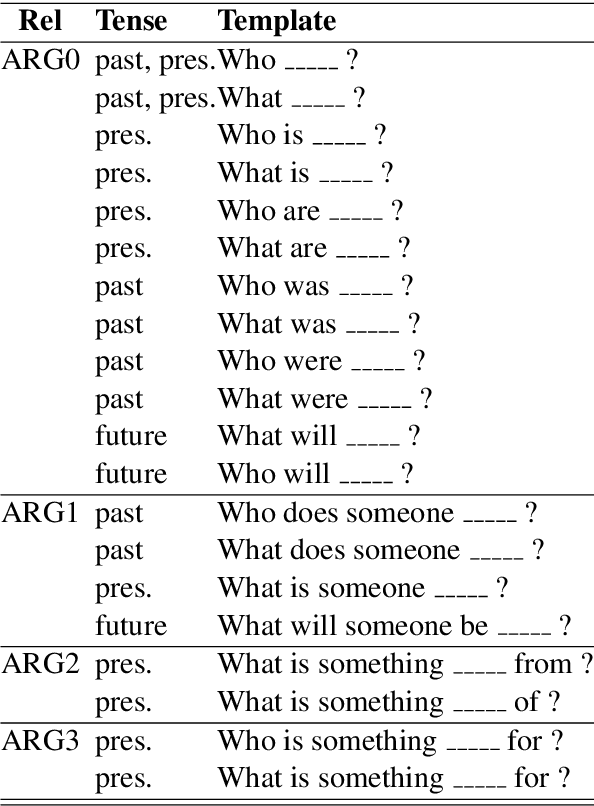
In this work, we introduce ASQ, a tool to automatically mine questions and answers from a sentence, using its Abstract Meaning Representation (AMR). Previous work has made a case for using question-answer pairs to specify predicate-argument structure of a sentence using natural language, which does not require linguistic expertise or training. This has resulted in the creation of datasets such as QA-SRL and QAMR, for both of which, the question-answer pair annotations were crowdsourced. Our approach has the same end-goal, but is automatic, making it faster and cost-effective, without compromising on the quality and validity of the question-answer pairs thus obtained. A qualitative evaluation of the output generated by ASQ from the AMR 2.0 data shows that the question-answer pairs are natural and valid, and demonstrate good coverage of the content. We run ASQ on the sentences from the QAMR dataset, to observe that the semantic roles in QAMR are also captured by ASQ.We intend to make this tool and the results publicly available for others to use and build upon.
CruzAffect at AffCon 2019 Shared Task: A feature-rich approach to characterize happiness
Feb 16, 2019
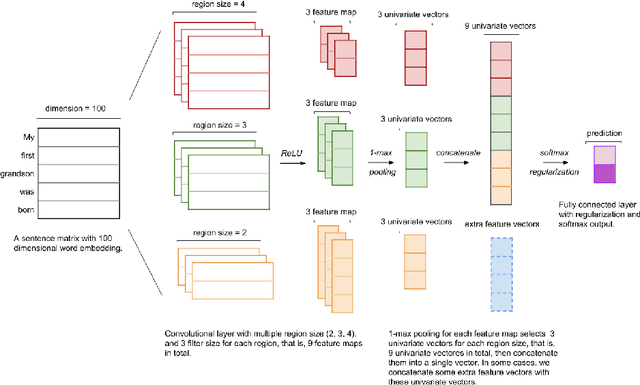
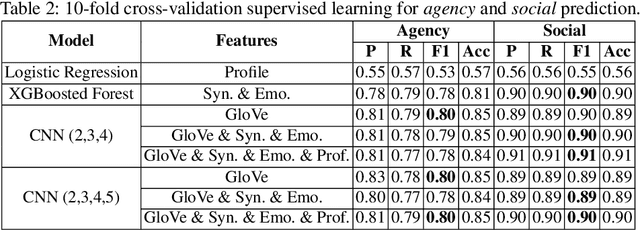
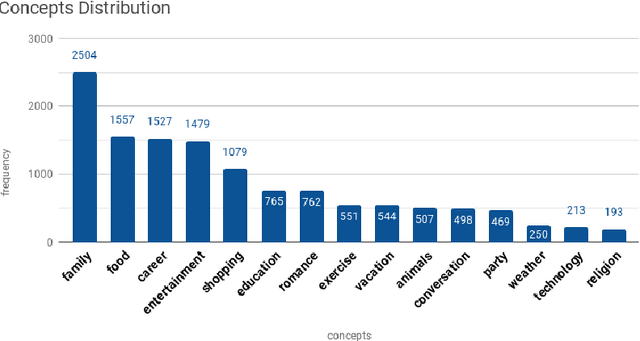
We present our system, CruzAffect, for the CL-Aff Shared Task 2019. CruzAffect consists of several types of robust and efficient models for affective classification tasks. We utilize both traditional classifiers, such as XGBoosted Forest, as well as a deep learning Convolutional Neural Networks (CNN) classifier. We explore rich feature sets such as syntactic features, emotional features, and profile features, and utilize several sentiment lexicons, to discover essential indicators of social involvement and control that a subject might exercise in their happy moments, as described in textual snippets from the HappyDB database. The data comes with a labeled set (10K), and a larger unlabeled set (70K). We therefore use supervised methods on the 10K dataset, and a bootstrapped semi-supervised approach for the 70K. We evaluate these models for binary classification of agency and social labels (Task 1), as well as multi-class prediction for concepts labels (Task 2). We obtain promising results on the held-out data, suggesting that the proposed feature sets effectively represent the data for affective classification tasks. We also build concepts models that discover general themes recurring in happy moments. Our results indicate that generic characteristics are shared between the classes of agency, social and concepts, suggesting it should be possible to build general models for affective classification tasks.
Debbie, the Debate Bot of the Future
Sep 10, 2017
Chatbots are a rapidly expanding application of dialogue systems with companies switching to bot services for customer support, and new applications for users interested in casual conversation. One style of casual conversation is argument, many people love nothing more than a good argument. Moreover, there are a number of existing corpora of argumentative dialogues, annotated for agreement and disagreement, stance, sarcasm and argument quality. This paper introduces Debbie, a novel arguing bot, that selects arguments from conversational corpora, and aims to use them appropriately in context. We present an initial working prototype of Debbie, with some preliminary evaluation and describe future work.
Prepositional Attachment Disambiguation Using Bilingual Parsing and Alignments
Mar 29, 2016
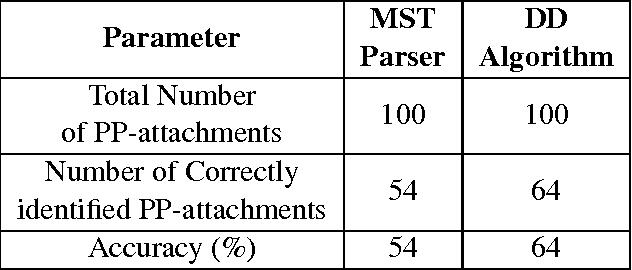

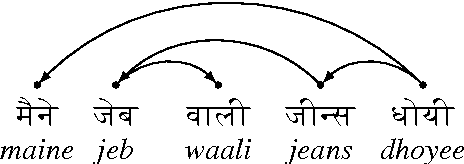
In this paper, we attempt to solve the problem of Prepositional Phrase (PP) attachments in English. The motivation for the work comes from NLP applications like Machine Translation, for which, getting the correct attachment of prepositions is very crucial. The idea is to correct the PP-attachments for a sentence with the help of alignments from parallel data in another language. The novelty of our work lies in the formulation of the problem into a dual decomposition based algorithm that enforces agreement between the parse trees from two languages as a constraint. Experiments were performed on the English-Hindi language pair and the performance improved by 10% over the baseline, where the baseline is the attachment predicted by the MSTParser model trained for English.