 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrepositional Attachment Disambiguation Using Bilingual Parsing and Alignments
Paper and Code
Mar 29, 2016
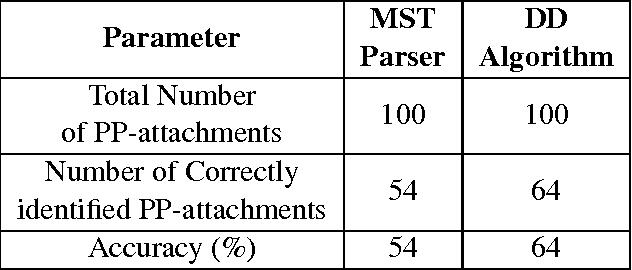

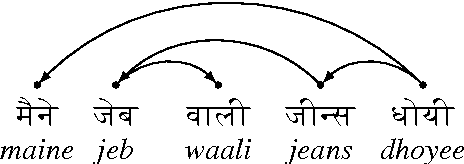
In this paper, we attempt to solve the problem of Prepositional Phrase (PP) attachments in English. The motivation for the work comes from NLP applications like Machine Translation, for which, getting the correct attachment of prepositions is very crucial. The idea is to correct the PP-attachments for a sentence with the help of alignments from parallel data in another language. The novelty of our work lies in the formulation of the problem into a dual decomposition based algorithm that enforces agreement between the parse trees from two languages as a constraint. Experiments were performed on the English-Hindi language pair and the performance improved by 10% over the baseline, where the baseline is the attachment predicted by the MSTParser model trained for English.