 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Mistakes: Combining Ontologies via Self-Training for Dialogue Generation
Paper and Code
Sep 30, 2020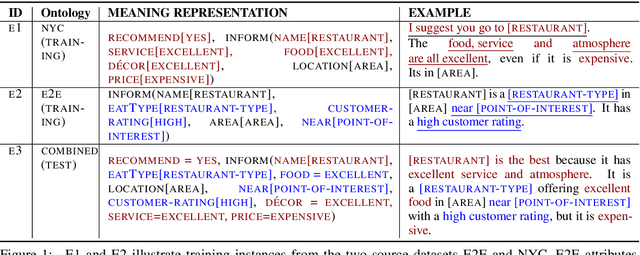
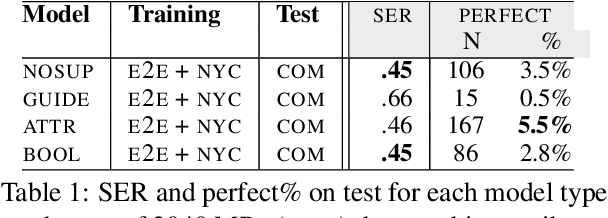
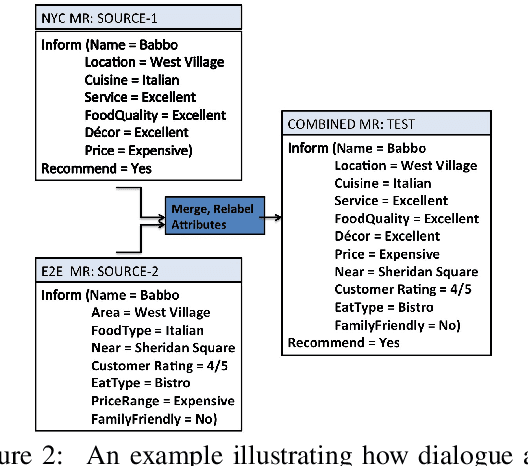
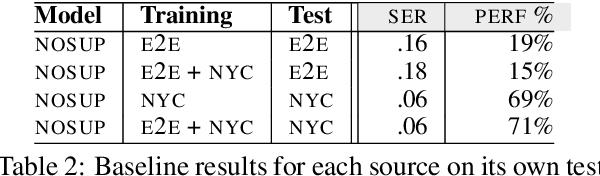
Natural language generators (NLGs) for task-oriented dialogue typically take a meaning representation (MR) as input. They are trained end-to-end with a corpus of MR/utterance pairs, where the MRs cover a specific set of dialogue acts and domain attributes. Creation of such datasets is labor-intensive and time-consuming. Therefore, dialogue systems for new domain ontologies would benefit from using data for pre-existing ontologies. Here we explore, for the first time, whether it is possible to train an NLG for a new larger ontology using existing training sets for the restaurant domain, where each set is based on a different ontology. We create a new, larger combined ontology, and then train an NLG to produce utterances covering it. For example, if one dataset has attributes for family-friendly and rating information, and the other has attributes for decor and service, our aim is an NLG for the combined ontology that can produce utterances that realize values for family-friendly, rating, decor and service. Initial experiments with a baseline neural sequence-to-sequence model show that this task is surprisingly challenging. We then develop a novel self-training method that identifies (errorful) model outputs, automatically constructs a corrected MR input to form a new (MR, utterance) training pair, and then repeatedly adds these new instances back into the training data. We then test the resulting model on a new test set. The result is a self-trained model whose performance is an absolute 75.4% improvement over the baseline model. We also report a human qualitative evaluation of the final model showing that it achieves high naturalness, semantic coherence and grammaticality