 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace-to-Face Contrastive Learning for Social Intelligence Question-Answering
Aug 15, 2022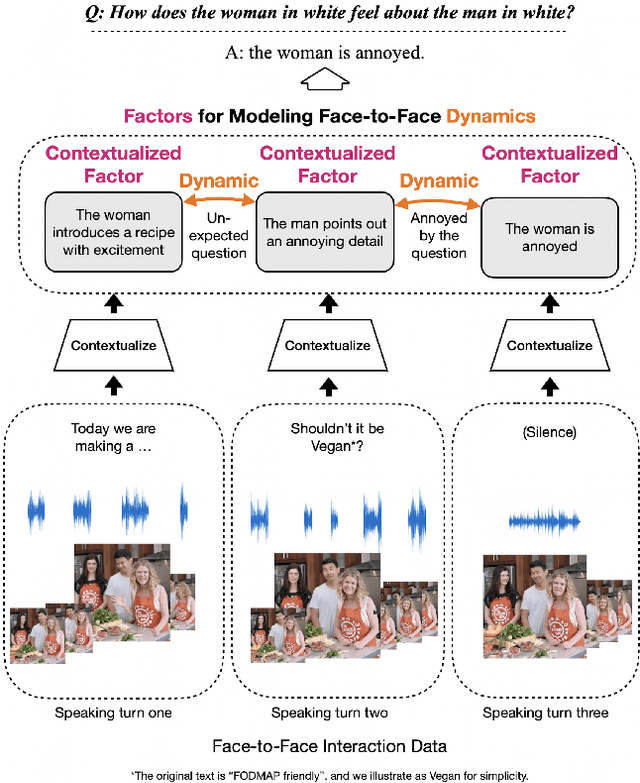
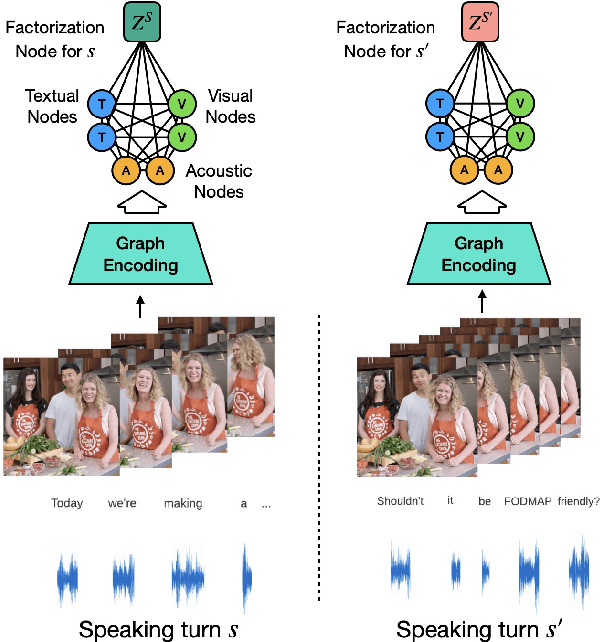
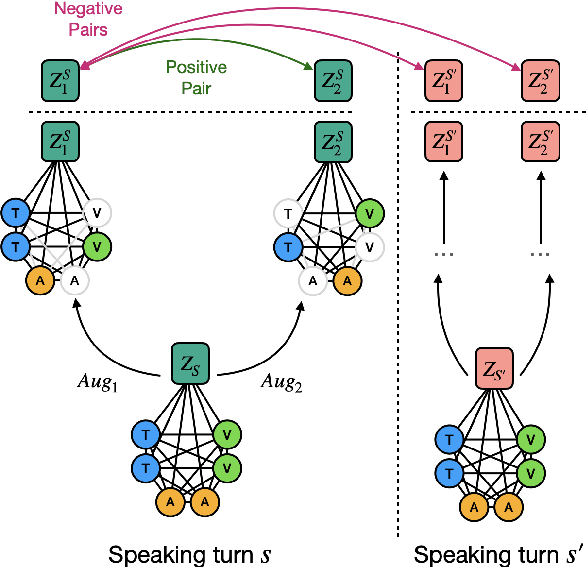
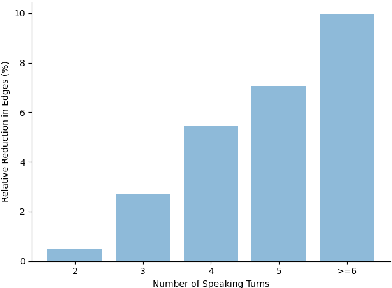
Creating artificial social intelligence - algorithms that can understand the nuances of multi-person interactions - is an exciting and emerging challenge in processing facial expressions and gestures from multimodal videos. Recent multimodal methods have set the state of the art on many tasks, but have difficulty modeling the complex face-to-face conversational dynamics across speaking turns in social interaction, particularly in a self-supervised setup. In this paper, we propose Face-to-Face Contrastive Learning (F2F-CL), a graph neural network designed to model social interactions using factorization nodes to contextualize the multimodal face-to-face interaction along the boundaries of the speaking turn. With the F2F-CL model, we propose to perform contrastive learning between the factorization nodes of different speaking turns within the same video. We experimentally evaluated the challenging Social-IQ dataset and show state-of-the-art results.