 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Point Cloud Registration via Geometric Overlapping Guided Rotation Search
Aug 24, 2025Point cloud registration based on correspondences computes the rigid transformation that maximizes the number of inliers constrained within the noise threshold. Current state-of-the-art (SOTA) methods employing spatial compatibility graphs or branch-and-bound (BnB) search mainly focus on registration under high outlier ratios. However, graph-based methods require at least quadratic space and time complexity for graph construction, while multi-stage BnB search methods often suffer from inaccuracy due to local optima between decomposed stages. This paper proposes a geometric maximum overlapping registration framework via rotation-only BnB search. The rigid transformation is decomposed using Chasles' theorem into a translation along rotation axis and a 2D rigid transformation. The optimal rotation axis and angle are searched via BnB, with residual parameters formulated as range maximum query (RMQ) problems. Firstly, the top-k candidate rotation axes are searched within a hemisphere parameterized by cube mapping, and the translation along each axis is estimated through interval stabbing of the correspondences projected onto that axis. Secondly, the 2D registration is relaxed to 1D rotation angle search with 2D RMQ of geometric overlapping for axis-aligned rectangles, which is solved deterministically in polynomial time using sweep line algorithm with segment tree. Experimental results on 3DMatch, 3DLoMatch, and KITTI datasets demonstrate superior accuracy and efficiency over SOTA methods, while the time complexity is polynomial and the space complexity increases linearly with the number of points, even in the worst case.
A Framework for Fast Polarity Labelling of Massive Data Streams
Mar 23, 2022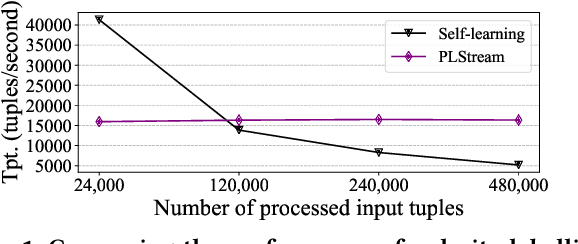
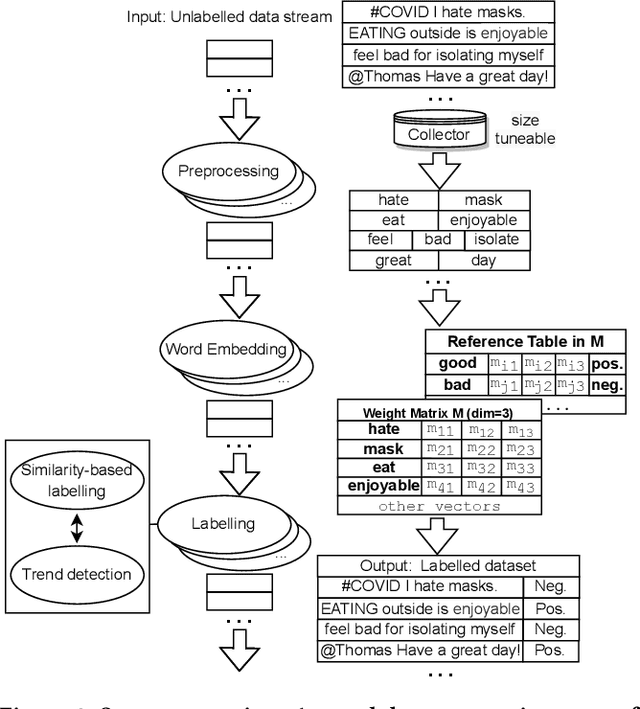
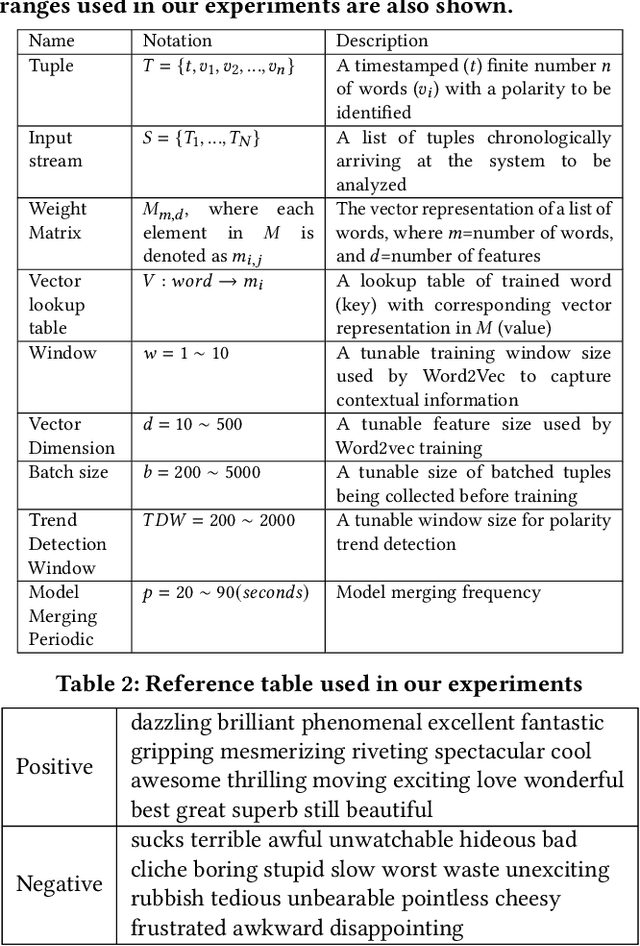
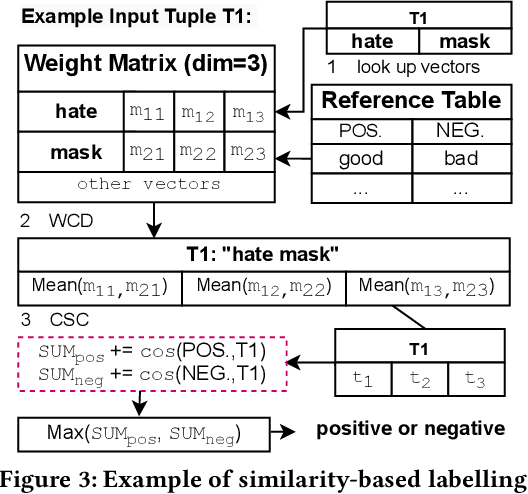
Many of the existing sentiment analysis techniques are based on supervised learning, and they demand the availability of valuable training datasets to train their models. When dataset freshness is critical, the annotating of high speed unlabelled data streams becomes critical but remains an open problem. In this paper, we propose PLStream, a novel Apache Flink-based framework for fast polarity labelling of massive data streams, like Twitter tweets or online product reviews. We address the associated implementation challenges and propose a list of techniques including both algorithmic improvements and system optimizations. A thorough empirical validation with two real-world workloads demonstrates that PLStream is able to generate high quality labels (almost 80% accuracy) in the presence of high-speed continuous unlabelled data streams (almost 16,000 tuples/sec) without any manual efforts.
Feature-Based Matrix Factorization
Dec 29, 2011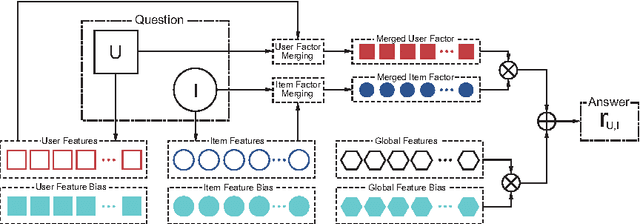

Recommender system has been more and more popular and widely used in many applications recently. The increasing information available, not only in quantities but also in types, leads to a big challenge for recommender system that how to leverage these rich information to get a better performance. Most traditional approaches try to design a specific model for each scenario, which demands great efforts in developing and modifying models. In this technical report, we describe our implementation of feature-based matrix factorization. This model is an abstract of many variants of matrix factorization models, and new types of information can be utilized by simply defining new features, without modifying any lines of code. Using the toolkit, we built the best single model reported on track 1 of KDDCup'11.