 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXtraGPT: LLMs for Human-AI Collaboration on Controllable Academic Paper Revision
May 16, 2025Despite the growing adoption of large language models (LLMs) in academic workflows, their capabilities remain limited when it comes to supporting high-quality scientific writing. Most existing systems are designed for general-purpose scientific text generation and fail to meet the sophisticated demands of research communication beyond surface-level polishing, such as conceptual coherence across sections. Furthermore, academic writing is inherently iterative and revision-driven, a process not well supported by direct prompting-based paradigms. To address these scenarios, we propose a human-AI collaboration framework for academic paper revision. We first introduce a comprehensive dataset of 7,040 research papers from top-tier venues annotated with over 140,000 instruction-response pairs that reflect realistic, section-level scientific revisions. Building on the dataset, we develop XtraGPT, the first suite of open-source LLMs, designed to provide context-aware, instruction-guided writing assistance, ranging from 1.5B to 14B parameters. Extensive experiments validate that XtraGPT significantly outperforms same-scale baselines and approaches the quality of proprietary systems. Both automated preference assessments and human evaluations confirm the effectiveness of our models in improving scientific drafts.
LogQuant: Log-Distributed 2-Bit Quantization of KV Cache with Superior Accuracy Preservation
Mar 25, 2025



We introduce LogQuant, a groundbreaking 2-bit quantization technique for KV Cache in large language model (LLM) inference, delivering substantial memory savings while preserving superior performance. Previous methods either assume that later tokens are more important or attempt to predict important tokens based on earlier attention patterns. Both approaches, however, can result in performance bottlenecks or frequent mispredictions. LogQuant takes a different approach. By applying a log-based filtering mechanism, it selectively compresses the KV Cache across the entire context, achieving better performance with the same or even reduced memory footprint compared to existing methods. In benchmark tests, it enhances throughput by 25% and boosts batch size by 60% without increasing memory consumption. For challenging tasks such as Math and Code Completion, LogQuant improves accuracy by 40% to 200% at the same compression ratio, outperforming comparable techniques.LogQuant integrates effortlessly with popular inference frameworks like Python's transformers library. Implementation can be available in https://github.com/Concyclics/LogQuantKV.
PCB Renewal: Iterative Reuse of PCB Substrates for Sustainable Electronic Making
Feb 18, 2025PCB (printed circuit board) substrates are often single-use, leading to material waste in electronics making. We introduce PCB Renewal, a novel technique that "erases" and "reconfigures" PCB traces by selectively depositing conductive epoxy onto outdated areas, transforming isolated paths into conductive planes that support new traces. We present the PCB Renewal workflow, evaluate its electrical performance and mechanical durability, and model its sustainability impact, including material usage, cost, energy consumption, and time savings. We develop a software plug-in that guides epoxy deposition, generates updated PCB profiles, and calculates resource usage. To demonstrate PCB Renewal's effectiveness and versatility, we repurpose a single PCB across four design iterations spanning three projects: a camera roller, a WiFi radio, and an ESPboy game console. We also show how an outsourced double-layer PCB can be reconfigured, transforming it from an LED watch to an interactive cat toy. The paper concludes with limitations and future directions.
Aggressive Post-Training Compression on Extremely Large Language Models
Sep 30, 2024The increasing size and complexity of Large Language Models (LLMs) pose challenges for their deployment on personal computers and mobile devices. Aggressive post-training model compression is necessary to reduce the models' size, but it often results in significant accuracy loss. To address this challenge, we propose a novel network pruning technology that utilizes over 0.7 sparsity and less than 8 bits of quantization. Our approach enables the compression of prevailing LLMs within a couple of hours while maintaining a relatively small accuracy loss. In experimental evaluations, our method demonstrates effectiveness and potential for practical deployment. By making LLMs available on domestic devices, our work can facilitate a new era of natural language processing applications with wide-ranging impacts.
HARL: Hierarchical Adaptive Reinforcement Learning Based Auto Scheduler for Neural Networks
Nov 21, 2022



To efficiently perform inference with neural networks, the underlying tensor programs require sufficient tuning efforts before being deployed into production environments. Usually, enormous tensor program candidates need to be sufficiently explored to find the one with the best performance. This is necessary to make the neural network products meet the high demand of real-world applications such as natural language processing, auto-driving, etc. Auto-schedulers are being developed to avoid the need for human intervention. However, due to the gigantic search space and lack of intelligent search guidance, current auto-schedulers require hours to days of tuning time to find the best-performing tensor program for the entire neural network. In this paper, we propose HARL, a reinforcement learning (RL) based auto-scheduler specifically designed for efficient tensor program exploration. HARL uses a hierarchical RL architecture in which learning-based decisions are made at all different levels of search granularity. It also automatically adjusts exploration configurations in real-time for faster performance convergence. As a result, HARL improves the tensor operator performance by 22% and the search speed by 4.3x compared to the state-of-the-art auto-scheduler. Inference performance and search speed are also significantly improved on end-to-end neural networks.
TransMask: A Compact and Fast Speech Separation Model Based on Transformer
Feb 19, 2021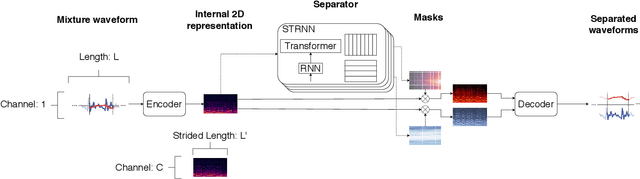
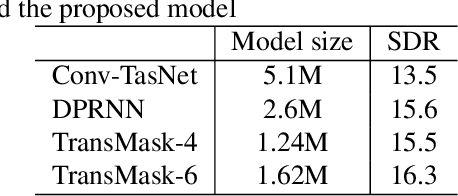
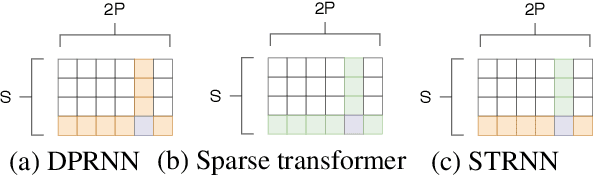
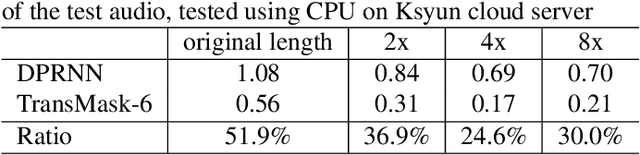
Speech separation is an important problem in speech processing, which targets to separate and generate clean speech from a mixed audio containing speech from different speakers. Empowered by the deep learning technologies over sequence-to-sequence domain, recent neural speech separation models are now capable of generating highly clean speech audios. To make these models more practical by reducing the model size and inference time while maintaining high separation quality, we propose a new transformer-based speech separation approach, called TransMask. By fully un-leashing the power of self-attention on long-term dependency exception, we demonstrate the size of TransMask is more than 60% smaller and the inference is more than 2 times faster than state-of-the-art solutions. TransMask fully utilizes the parallelism during inference, and achieves nearly linear inference time within reasonable input audio lengths. It also outperforms existing solutions on output speech audio quality, achieving SDR above 16 over Librimix benchmark.