 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeER-FSL: Experience Replay with Feature Subspace Learning for Online Continual Learning
Jul 17, 2024Online continual learning (OCL) involves deep neural networks retaining knowledge from old data while adapting to new data, which is accessible only once. A critical challenge in OCL is catastrophic forgetting, reflected in reduced model performance on old data. Existing replay-based methods mitigate forgetting by replaying buffered samples from old data and learning current samples of new data. In this work, we dissect existing methods and empirically discover that learning and replaying in the same feature space is not conducive to addressing the forgetting issue. Since the learned features associated with old data are readily changed by the features related to new data due to data imbalance, leading to the forgetting problem. Based on this observation, we intuitively explore learning and replaying in different feature spaces. Learning in a feature subspace is sufficient to capture novel knowledge from new data while replaying in a larger feature space provides more feature space to maintain historical knowledge from old data. To this end, we propose a novel OCL approach called experience replay with feature subspace learning (ER-FSL). Firstly, ER-FSL divides the entire feature space into multiple subspaces, with each subspace used to learn current samples. Moreover, it introduces a subspace reuse mechanism to address situations where no blank subspaces exist. Secondly, ER-FSL replays previous samples using an accumulated space comprising all learned subspaces. Extensive experiments on three datasets demonstrate the superiority of ER-FSL over various state-of-the-art methods.
HPCR: Holistic Proxy-based Contrastive Replay for Online Continual Learning
Sep 26, 2023Online continual learning (OCL) aims to continuously learn new data from a single pass over the online data stream. It generally suffers from the catastrophic forgetting issue. Existing replay-based methods effectively alleviate this issue by replaying part of old data in a proxy-based or contrastive-based replay manner. In this paper, we conduct a comprehensive analysis of these two replay manners and find they can be complementary. Inspired by this finding, we propose a novel replay-based method called proxy-based contrastive replay (PCR), which replaces anchor-to-sample pairs with anchor-to-proxy pairs in the contrastive-based loss to alleviate the phenomenon of forgetting. Based on PCR, we further develop a more advanced method named holistic proxy-based contrastive replay (HPCR), which consists of three components. The contrastive component conditionally incorporates anchor-to-sample pairs to PCR, learning more fine-grained semantic information with a large training batch. The second is a temperature component that decouples the temperature coefficient into two parts based on their impacts on the gradient and sets different values for them to learn more novel knowledge. The third is a distillation component that constrains the learning process to keep more historical knowledge. Experiments on four datasets consistently demonstrate the superiority of HPCR over various state-of-the-art methods.
UER: A Heuristic Bias Addressing Approach for Online Continual Learning
Sep 08, 2023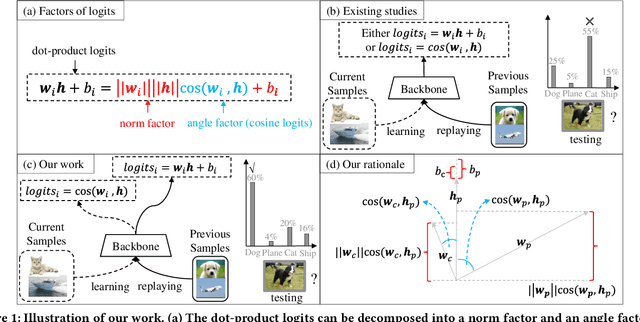
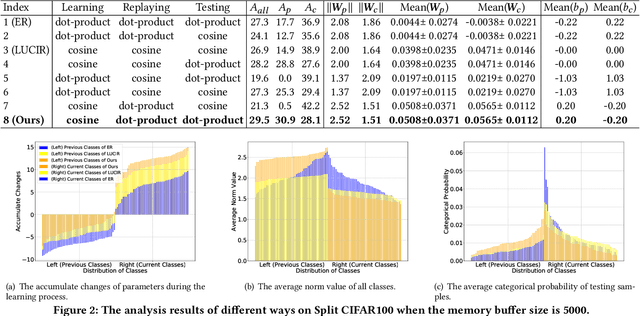
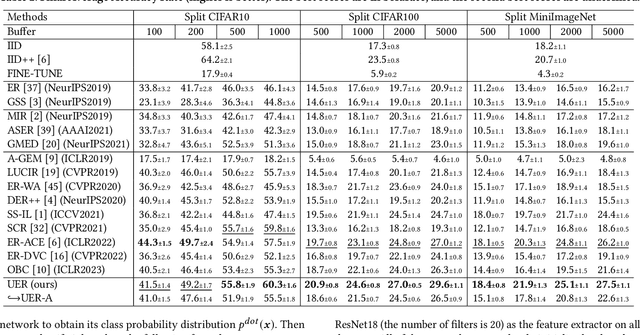
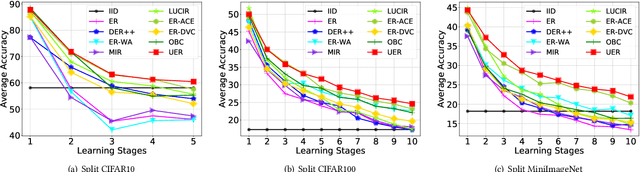
Online continual learning aims to continuously train neural networks from a continuous data stream with a single pass-through data. As the most effective approach, the rehearsal-based methods replay part of previous data. Commonly used predictors in existing methods tend to generate biased dot-product logits that prefer to the classes of current data, which is known as a bias issue and a phenomenon of forgetting. Many approaches have been proposed to overcome the forgetting problem by correcting the bias; however, they still need to be improved in online fashion. In this paper, we try to address the bias issue by a more straightforward and more efficient method. By decomposing the dot-product logits into an angle factor and a norm factor, we empirically find that the bias problem mainly occurs in the angle factor, which can be used to learn novel knowledge as cosine logits. On the contrary, the norm factor abandoned by existing methods helps remember historical knowledge. Based on this observation, we intuitively propose to leverage the norm factor to balance the new and old knowledge for addressing the bias. To this end, we develop a heuristic approach called unbias experience replay (UER). UER learns current samples only by the angle factor and further replays previous samples by both the norm and angle factors. Extensive experiments on three datasets show that UER achieves superior performance over various state-of-the-art methods. The code is in https://github.com/FelixHuiweiLin/UER.
PCR: Proxy-based Contrastive Replay for Online Class-Incremental Continual Learning
Apr 10, 2023Online class-incremental continual learning is a specific task of continual learning. It aims to continuously learn new classes from data stream and the samples of data stream are seen only once, which suffers from the catastrophic forgetting issue, i.e., forgetting historical knowledge of old classes. Existing replay-based methods effectively alleviate this issue by saving and replaying part of old data in a proxy-based or contrastive-based replay manner. Although these two replay manners are effective, the former would incline to new classes due to class imbalance issues, and the latter is unstable and hard to converge because of the limited number of samples. In this paper, we conduct a comprehensive analysis of these two replay manners and find that they can be complementary. Inspired by this finding, we propose a novel replay-based method called proxy-based contrastive replay (PCR). The key operation is to replace the contrastive samples of anchors with corresponding proxies in the contrastive-based way. It alleviates the phenomenon of catastrophic forgetting by effectively addressing the imbalance issue, as well as keeps a faster convergence of the model. We conduct extensive experiments on three real-world benchmark datasets, and empirical results consistently demonstrate the superiority of PCR over various state-of-the-art methods.
* To appear in CVPR 2023. 10 pages, 8 figures and 3 tables