 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Wise Feature Metric of Semantic-Pixel Matching for Few-Shot Learning
Nov 10, 2024



In Few-Shot Learning (FSL), traditional metric-based approaches often rely on global metrics to compute similarity. However, in natural scenes, the spatial arrangement of key instances is often inconsistent across images. This spatial misalignment can result in mismatched semantic pixels, leading to inaccurate similarity measurements. To address this issue, we propose a novel method called the Layer-Wise Features Metric of Semantic-Pixel Matching (LWFM-SPM) to make finer comparisons. Our method enhances model performance through two key modules: (1) the Layer-Wise Embedding (LWE) Module, which refines the cross-correlation of image pairs to generate well-focused feature maps for each layer; (2)the Semantic-Pixel Matching (SPM) Module, which aligns critical pixels based on semantic embeddings using an assignment algorithm. We conducted extensive experiments to evaluate our method on four widely used few-shot classification benchmarks: miniImageNet, tieredImageNet, CUB-200-2011, and CIFAR-FS. The results indicate that LWFM-SPM achieves competitive performance across these benchmarks. Our code will be publicly available on https://github.com/Halo2Tang/Code-for-LWFM-SPM.
IMAN: An Adaptive Network for Robust NPC Mortality Prediction with Missing Modalities
Oct 24, 2024Accurate prediction of mortality in nasopharyngeal carcinoma (NPC), a complex malignancy particularly challenging in advanced stages, is crucial for optimizing treatment strategies and improving patient outcomes. However, this predictive process is often compromised by the high-dimensional and heterogeneous nature of NPC-related data, coupled with the pervasive issue of incomplete multi-modal data, manifesting as missing radiological images or incomplete diagnostic reports. Traditional machine learning approaches suffer significant performance degradation when faced with such incomplete data, as they fail to effectively handle the high-dimensionality and intricate correlations across modalities. Even advanced multi-modal learning techniques like Transformers struggle to maintain robust performance in the presence of missing modalities, as they lack specialized mechanisms to adaptively integrate and align the diverse data types, while also capturing nuanced patterns and contextual relationships within the complex NPC data. To address these problem, we introduce IMAN: an adaptive network for robust NPC mortality prediction with missing modalities.
TAGE: Trustworthy Attribute Group Editing for Stable Few-shot Image Generation
Oct 23, 2024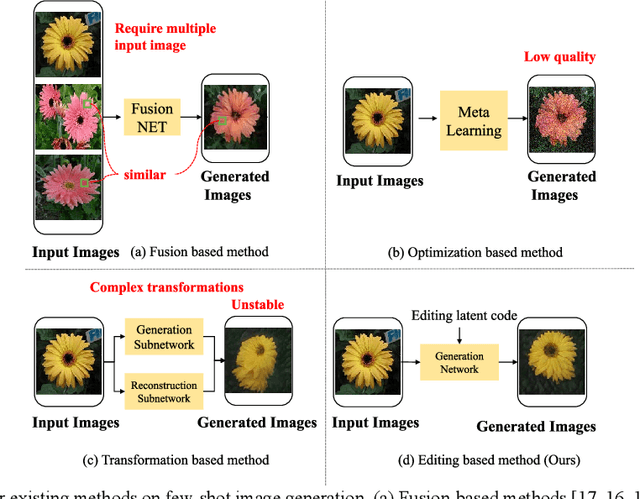
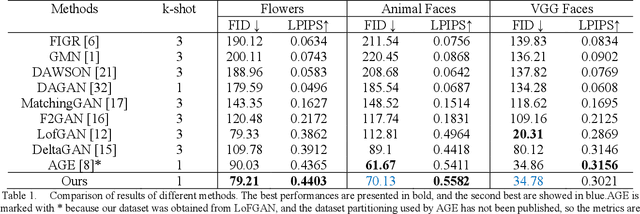


Generative Adversarial Networks (GANs) have emerged as a prominent research focus for image editing tasks, leveraging the powerful image generation capabilities of the GAN framework to produce remarkable results.However, prevailing approaches are contingent upon extensive training datasets and explicit supervision, presenting a significant challenge in manipulating the diverse attributes of new image classes with limited sample availability. To surmount this hurdle, we introduce TAGE, an innovative image generation network comprising three integral modules: the Codebook Learning Module (CLM), the Code Prediction Module (CPM) and the Prompt-driven Semantic Module (PSM). The CPM module delves into the semantic dimensions of category-agnostic attributes, encapsulating them within a discrete codebook. This module is predicated on the concept that images are assemblages of attributes, and thus, by editing these category-independent attributes, it is theoretically possible to generate images from unseen categories. Subsequently, the CPM module facilitates naturalistic image editing by predicting indices of category-independent attribute vectors within the codebook. Additionally, the PSM module generates semantic cues that are seamlessly integrated into the Transformer architecture of the CPM, enhancing the model's comprehension of the targeted attributes for editing. With these semantic cues, the model can generate images that accentuate desired attributes more prominently while maintaining the integrity of the original category, even with a limited number of samples. We have conducted extensive experiments utilizing the Animal Faces, Flowers, and VGGFaces datasets. The results of these experiments demonstrate that our proposed method not only achieves superior performance but also exhibits a high degree of stability when compared to other few-shot image generation techniques.
Medical Visual Prompting (MVP): A Unified Framework for Versatile and High-Quality Medical Image Segmentation
Apr 01, 2024



Accurate segmentation of lesion regions is crucial for clinical diagnosis and treatment across various diseases. While deep convolutional networks have achieved satisfactory results in medical image segmentation, they face challenges such as loss of lesion shape information due to continuous convolution and downsampling, as well as the high cost of manually labeling lesions with varying shapes and sizes. To address these issues, we propose a novel medical visual prompting (MVP) framework that leverages pre-training and prompting concepts from natural language processing (NLP). The framework utilizes three key components: Super-Pixel Guided Prompting (SPGP) for superpixelating the input image, Image Embedding Guided Prompting (IEGP) for freezing patch embedding and merging with superpixels to provide visual prompts, and Adaptive Attention Mechanism Guided Prompting (AAGP) for pinpointing prompt content and efficiently adapting all layers. By integrating SPGP, IEGP, and AAGP, the MVP enables the segmentation network to better learn shape prompting information and facilitates mutual learning across different tasks. Extensive experiments conducted on five datasets demonstrate superior performance of this method in various challenging medical image tasks, while simplifying single-task medical segmentation models. This novel framework offers improved performance with fewer parameters and holds significant potential for accurate segmentation of lesion regions in various medical tasks, making it clinically valuable.
Adaptive Query Prompting for Multi-Domain Landmark Detection
Apr 01, 2024



Medical landmark detection is crucial in various medical imaging modalities and procedures. Although deep learning-based methods have achieve promising performance, they are mostly designed for specific anatomical regions or tasks. In this work, we propose a universal model for multi-domain landmark detection by leveraging transformer architecture and developing a prompting component, named as Adaptive Query Prompting (AQP). Instead of embedding additional modules in the backbone network, we design a separate module to generate prompts that can be effectively extended to any other transformer network. In our proposed AQP, prompts are learnable parameters maintained in a memory space called prompt pool. The central idea is to keep the backbone frozen and then optimize prompts to instruct the model inference process. Furthermore, we employ a lightweight decoder to decode landmarks from the extracted features, namely Light-MLD. Thanks to the lightweight nature of the decoder and AQP, we can handle multiple datasets by sharing the backbone encoder and then only perform partial parameter tuning without incurring much additional cost. It has the potential to be extended to more landmark detection tasks. We conduct experiments on three widely used X-ray datasets for different medical landmark detection tasks. Our proposed Light-MLD coupled with AQP achieves SOTA performance on many metrics even without the use of elaborate structural designs or complex frameworks.
RBA-GCN: Relational Bilevel Aggregation Graph Convolutional Network for Emotion Recognition
Aug 31, 2023Emotion recognition in conversation (ERC) has received increasing attention from researchers due to its wide range of applications.As conversation has a natural graph structure,numerous approaches used to model ERC based on graph convolutional networks (GCNs) have yielded significant results.However,the aggregation approach of traditional GCNs suffers from the node information redundancy problem,leading to node discriminant information loss.Additionally,single-layer GCNs lack the capacity to capture long-range contextual information from the graph. Furthermore,the majority of approaches are based on textual modality or stitching together different modalities, resulting in a weak ability to capture interactions between modalities. To address these problems, we present the relational bilevel aggregation graph convolutional network (RBA-GCN), which consists of three modules: the graph generation module (GGM), similarity-based cluster building module (SCBM) and bilevel aggregation module (BiAM). First, GGM constructs a novel graph to reduce the redundancy of target node information.Then,SCBM calculates the node similarity in the target node and its structural neighborhood, where noisy information with low similarity is filtered out to preserve the discriminant information of the node. Meanwhile, BiAM is a novel aggregation method that can preserve the information of nodes during the aggregation process. This module can construct the interaction between different modalities and capture long-range contextual information based on similarity clusters. On both the IEMOCAP and MELD datasets, the weighted average F1 score of RBA-GCN has a 2.17$\sim$5.21\% improvement over that of the most advanced method.Our code is available at https://github.com/luftmenscher/RBA-GCN and our article with the same name has been published in IEEE/ACM Transactions on Audio,Speech,and Language Processing,vol.31,2023
TempEE: Temporal-Spatial Parallel Transformer for Radar Echo Extrapolation Beyond Auto-Regression
Apr 27, 2023



The meteorological radar reflectivity data, also known as echo, plays a crucial role in predicting precipitation and enabling accurate and fast forecasting of short-term heavy rainfall without the need for complex Numerical Weather Prediction (NWP) model. Compared to conventional model, Deep Learning (DL)-based radar echo extrapolation algorithms are more effective and efficient. However, the development of highly reliable and generalized algorithms is hindered by three main bottlenecks: cumulative error spreading, imprecise representation of sparse echo distribution, and inaccurate description of non-stationary motion process. To address these issues, this paper presents a novel radar echo extrapolation algorithm that utilizes temporal-spatial correlation features and the Transformer technology. The algorithm extracts features from multi-frame echo images that accurately represent non-stationary motion processes for precipitation prediction. The proposed algorithm uses a novel parallel encoder based on Transformer technology to effectively and automatically extract echoes' temporal-spatial features. Furthermore, a Multi-level Temporal-Spatial attention mechanism is adopted to enhance the ability to perceive global-local information and highlight the task-related feature regions in a lightweight way. The proposed method's effectiveness has been valided on the classic radar echo extrapolation task using the real-world dataset. Numerous experiments have further demonstrated the effectiveness and necessity of various components of the proposed method.
Locality Preserving Multiview Graph Hashing for Large Scale Remote Sensing Image Search
Apr 10, 2023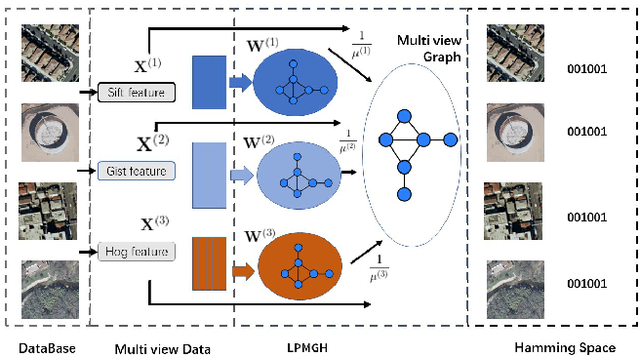

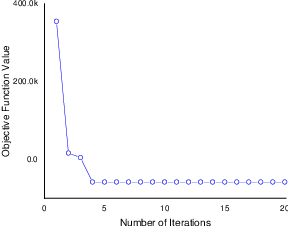
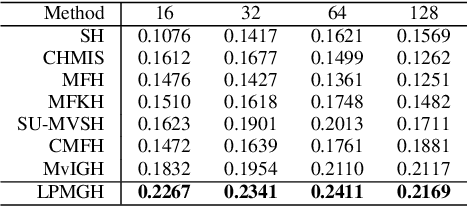
Hashing is very popular for remote sensing image search. This article proposes a multiview hashing with learnable parameters to retrieve the queried images for a large-scale remote sensing dataset. Existing methods always neglect that real-world remote sensing data lies on a low-dimensional manifold embedded in high-dimensional ambient space. Unlike previous methods, this article proposes to learn the consensus compact codes in a view-specific low-dimensional subspace. Furthermore, we have added a hyperparameter learnable module to avoid complex parameter tuning. In order to prove the effectiveness of our method, we carried out experiments on three widely used remote sensing data sets and compared them with seven state-of-the-art methods. Extensive experiments show that the proposed method can achieve competitive results compared to the other method.