 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERE: Structural Example Retrieval for Enhancing LLMs in Event Causality Identification
May 05, 2026Event Causality Identification (ECI) requires models to determine whether a given pair of events in a context exhibits a causal relationship. While Large Language Models (LLMs) have demonstrated strong performance across various NLP tasks, their effectiveness in ECI remains limited due to biases in causal reasoning, often leading to overprediction of causal relationships (causal hallucination). To mitigate these issues and enhance LLM performance in ECI, we propose SERE, a structural example retrieval framework that leverages LLMs' few-shot learning capabilities. SERE introduces an innovative retrieval mechanism based on three structural concepts: (i) Conceptual Path Metric, which measures the conceptual relationship between events using edit distance in ConceptNet; (ii) Syntactic Metric, which quantifies structural similarity through tree edit distance on syntactic trees; and (iii) Causal Pattern Filtering, which filters examples based on predefined causal structures using LLMs. By integrating these structural retrieval strategies, SERE selects more relevant examples to guide LLMs in causal reasoning, mitigating bias and improving accuracy in ECI tasks. Extensive experiments on multiple ECI datasets validate the effectiveness of SERE. The source code is publicly available at https://github.com/DMIRLAB-Group/SERE.
Human Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
Layer-Wise Feature Metric of Semantic-Pixel Matching for Few-Shot Learning
Nov 10, 2024



In Few-Shot Learning (FSL), traditional metric-based approaches often rely on global metrics to compute similarity. However, in natural scenes, the spatial arrangement of key instances is often inconsistent across images. This spatial misalignment can result in mismatched semantic pixels, leading to inaccurate similarity measurements. To address this issue, we propose a novel method called the Layer-Wise Features Metric of Semantic-Pixel Matching (LWFM-SPM) to make finer comparisons. Our method enhances model performance through two key modules: (1) the Layer-Wise Embedding (LWE) Module, which refines the cross-correlation of image pairs to generate well-focused feature maps for each layer; (2)the Semantic-Pixel Matching (SPM) Module, which aligns critical pixels based on semantic embeddings using an assignment algorithm. We conducted extensive experiments to evaluate our method on four widely used few-shot classification benchmarks: miniImageNet, tieredImageNet, CUB-200-2011, and CIFAR-FS. The results indicate that LWFM-SPM achieves competitive performance across these benchmarks. Our code will be publicly available on https://github.com/Halo2Tang/Code-for-LWFM-SPM.
Mutual Information calculation on different appearances
Jul 10, 2024Mutual information has many applications in image alignment and matching, mainly due to its ability to measure the statistical dependence between two images, even if the two images are from different modalities (e.g., CT and MRI). It considers not only the pixel intensities of the images but also the spatial relationships between the pixels. In this project, we apply the mutual information formula to image matching, where image A is the moving object and image B is the target object and calculate the mutual information between them to evaluate the similarity between the images. For comparison, we also used entropy and information-gain methods to test the dependency of the images. We also investigated the effect of different environments on the mutual information of the same image and used experiments and plots to demonstrate.
Rotate to Scan: UNet-like Mamba with Triplet SSM Module for Medical Image Segmentation
Apr 01, 2024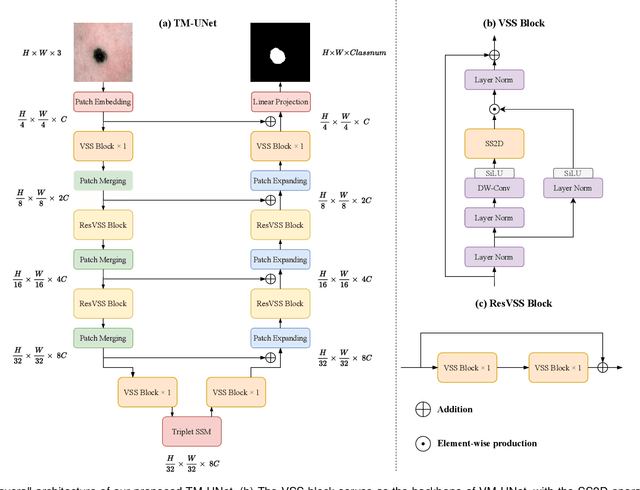
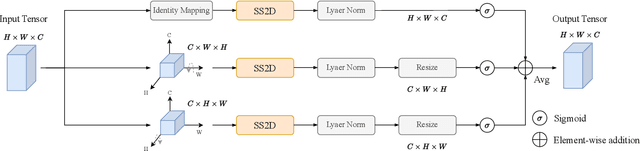
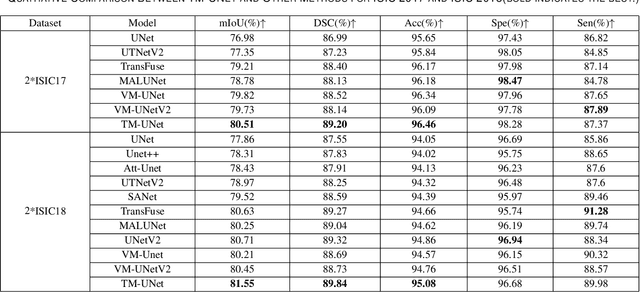
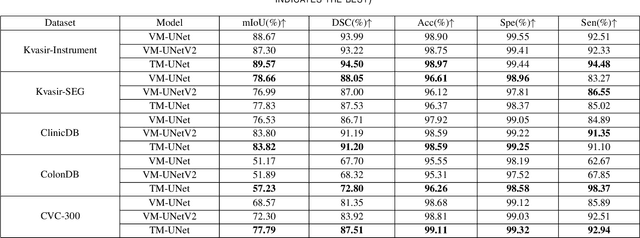
Image segmentation holds a vital position in the realms of diagnosis and treatment within the medical domain. Traditional convolutional neural networks (CNNs) and Transformer models have made significant advancements in this realm, but they still encounter challenges because of limited receptive field or high computing complexity. Recently, State Space Models (SSMs), particularly Mamba and its variants, have demonstrated notable performance in the field of vision. However, their feature extraction methods may not be sufficiently effective and retain some redundant structures, leaving room for parameter reduction. Motivated by previous spatial and channel attention methods, we propose Triplet Mamba-UNet. The method leverages residual VSS Blocks to extract intensive contextual features, while Triplet SSM is employed to fuse features across spatial and channel dimensions. We conducted experiments on ISIC17, ISIC18, CVC-300, CVC-ClinicDB, Kvasir-SEG, CVC-ColonDB, and Kvasir-Instrument datasets, demonstrating the superior segmentation performance of our proposed TM-UNet. Additionally, compared to the previous VM-UNet, our model achieves a one-third reduction in parameters.