 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotate to Scan: UNet-like Mamba with Triplet SSM Module for Medical Image Segmentation
Apr 01, 2024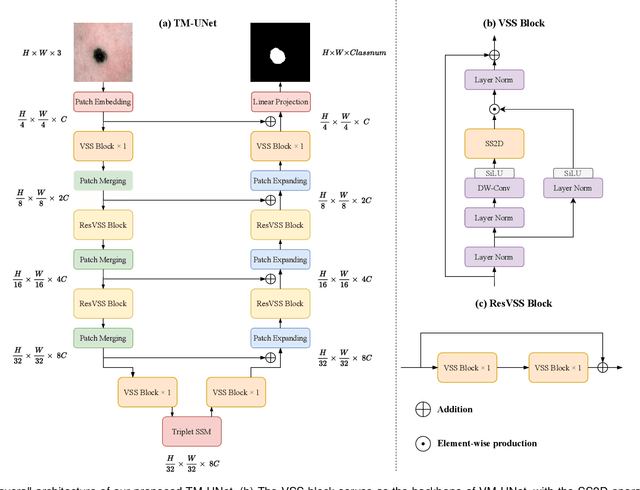
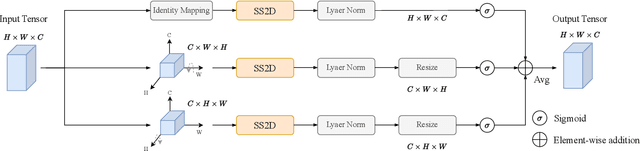
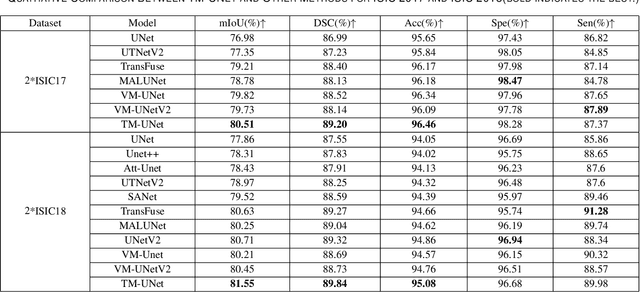
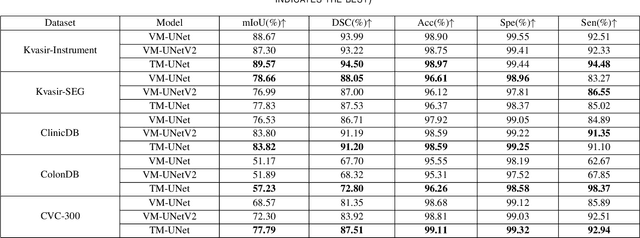
Image segmentation holds a vital position in the realms of diagnosis and treatment within the medical domain. Traditional convolutional neural networks (CNNs) and Transformer models have made significant advancements in this realm, but they still encounter challenges because of limited receptive field or high computing complexity. Recently, State Space Models (SSMs), particularly Mamba and its variants, have demonstrated notable performance in the field of vision. However, their feature extraction methods may not be sufficiently effective and retain some redundant structures, leaving room for parameter reduction. Motivated by previous spatial and channel attention methods, we propose Triplet Mamba-UNet. The method leverages residual VSS Blocks to extract intensive contextual features, while Triplet SSM is employed to fuse features across spatial and channel dimensions. We conducted experiments on ISIC17, ISIC18, CVC-300, CVC-ClinicDB, Kvasir-SEG, CVC-ColonDB, and Kvasir-Instrument datasets, demonstrating the superior segmentation performance of our proposed TM-UNet. Additionally, compared to the previous VM-UNet, our model achieves a one-third reduction in parameters.