 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMap-Agnostic And Interactive Safety-Critical Scenario Generation via Multi-Objective Tree Search
Mar 04, 2026Generating safety-critical scenarios is essential for validating the robustness of autonomous driving systems, yet existing methods often struggle to produce collisions that are both realistic and diverse while ensuring explicit interaction logic among traffic participants. This paper presents a novel framework for traffic-flow level safety-critical scenario generation via multi-objective Monte Carlo Tree Search (MCTS). We reframe trajectory feasibility and naturalistic behavior as optimization objectives within a unified evaluation function, enabling the discovery of diverse collision events without compromising realism. A hybrid Upper Confidence Bound (UCB) and Lower Confidence Bound (LCB) search strategy is introduced to balance exploratory efficiency with risk-averse decision-making. Furthermore, our method is map-agnostic and supports interactive scenario generation with each vehicle individually powered by SUMO's microscopic traffic models, enabling realistic agent behaviors in arbitrary geographic locations imported from OpenStreetMap. We validate our approach across four high-risk accident zones in Hong Kong's complex urban environments. Experimental results demonstrate that our framework achieves an 85\% collision failure rate while generating trajectories with superior feasibility and comfort metrics. The resulting scenarios exhibit greater complexity, as evidenced by increased vehicle mileage and CO\(_2\) emissions. Our work provides a principled solution for stress testing autonomous vehicles through the generation of realistic yet infrequent corner cases at traffic-flow level.
Generalizable Trajectory Prediction via Inverse Reinforcement Learning with Mamba-Graph Architecture
Jun 14, 2025Accurate driving behavior modeling is fundamental to safe and efficient trajectory prediction, yet remains challenging in complex traffic scenarios. This paper presents a novel Inverse Reinforcement Learning (IRL) framework that captures human-like decision-making by inferring diverse reward functions, enabling robust cross-scenario adaptability. The learned reward function is utilized to maximize the likelihood of output by the encoder-decoder architecture that combines Mamba blocks for efficient long-sequence dependency modeling with graph attention networks to encode spatial interactions among traffic agents. Comprehensive evaluations on urban intersections and roundabouts demonstrate that the proposed method not only outperforms various popular approaches in prediction accuracy but also achieves 2 times higher generalization performance to unseen scenarios compared to other IRL-based method.
Shaping Sparse Rewards in Reinforcement Learning: A Semi-supervised Approach
Jan 31, 2025



In many real-world scenarios, reward signal for agents are exceedingly sparse, making it challenging to learn an effective reward function for reward shaping. To address this issue, our approach performs reward shaping not only by utilizing non-zero-reward transitions but also by employing the Semi-Supervised Learning (SSL) technique combined with a novel data augmentation to learn trajectory space representations from the majority of transitions, zero-reward transitions, thereby improving the efficacy of reward shaping. Experimental results in Atari and robotic manipulation demonstrate that our method effectively generalizes reward shaping to sparse reward scenarios, achieving up to four times better performance in reaching higher best scores compared to curiosity-driven methods. The proposed double entropy data augmentation enhances performance, showcasing a 15.8\% increase in best score over other augmentation methods.
Transferable Adversarial Face Attack with Text Controlled Attribute
Dec 16, 2024



Traditional adversarial attacks typically produce adversarial examples under norm-constrained conditions, whereas unrestricted adversarial examples are free-form with semantically meaningful perturbations. Current unrestricted adversarial impersonation attacks exhibit limited control over adversarial face attributes and often suffer from low transferability. In this paper, we propose a novel Text Controlled Attribute Attack (TCA$^2$) to generate photorealistic adversarial impersonation faces guided by natural language. Specifically, the category-level personal softmax vector is employed to precisely guide the impersonation attacks. Additionally, we propose both data and model augmentation strategies to achieve transferable attacks on unknown target models. Finally, a generative model, \textit{i.e}, Style-GAN, is utilized to synthesize impersonated faces with desired attributes. Extensive experiments on two high-resolution face recognition datasets validate that our TCA$^2$ method can generate natural text-guided adversarial impersonation faces with high transferability. We also evaluate our method on real-world face recognition systems, \textit{i.e}, Face++ and Aliyun, further demonstrating the practical potential of our approach.
ELF: An End-to-end Local and Global Multimodal Fusion Framework for Glaucoma Grading
Nov 14, 2023Glaucoma is a chronic neurodegenerative condition that can lead to blindness. Early detection and curing are very important in stopping the disease from getting worse for glaucoma patients. The 2D fundus images and optical coherence tomography(OCT) are useful for ophthalmologists in diagnosing glaucoma. There are many methods based on the fundus images or 3D OCT volumes; however, the mining for multi-modality, including both fundus images and data, is less studied. In this work, we propose an end-to-end local and global multi-modal fusion framework for glaucoma grading, named ELF for short. ELF can fully utilize the complementary information between fundus and OCT. In addition, unlike previous methods that concatenate the multi-modal features together, which lack exploring the mutual information between different modalities, ELF can take advantage of local-wise and global-wise mutual information. The extensive experiment conducted on the multi-modal glaucoma grading GAMMA dataset can prove the effiectness of ELF when compared with other state-of-the-art methods.
Locality Preserving Multiview Graph Hashing for Large Scale Remote Sensing Image Search
Apr 10, 2023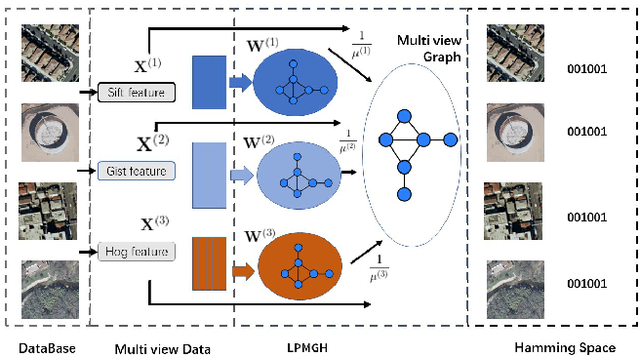

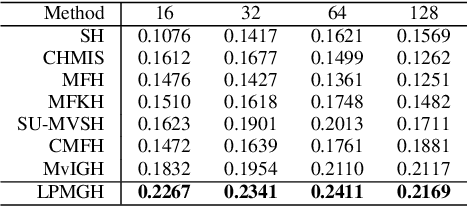
Hashing is very popular for remote sensing image search. This article proposes a multiview hashing with learnable parameters to retrieve the queried images for a large-scale remote sensing dataset. Existing methods always neglect that real-world remote sensing data lies on a low-dimensional manifold embedded in high-dimensional ambient space. Unlike previous methods, this article proposes to learn the consensus compact codes in a view-specific low-dimensional subspace. Furthermore, we have added a hyperparameter learnable module to avoid complex parameter tuning. In order to prove the effectiveness of our method, we carried out experiments on three widely used remote sensing data sets and compared them with seven state-of-the-art methods. Extensive experiments show that the proposed method can achieve competitive results compared to the other method.
Asymmetric Scalable Cross-modal Hashing
Jul 26, 2022

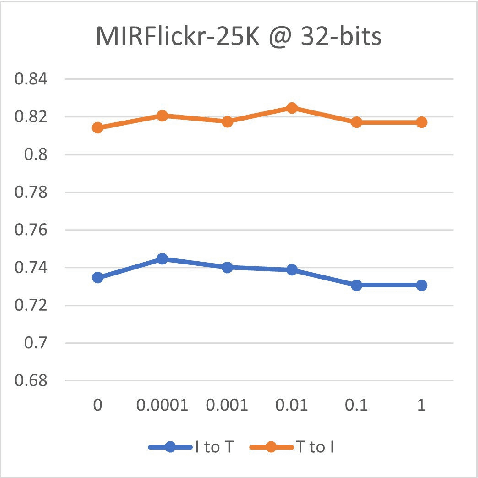

Cross-modal hashing is a successful method to solve large-scale multimedia retrieval issue. A lot of matrix factorization-based hashing methods are proposed. However, the existing methods still struggle with a few problems, such as how to generate the binary codes efficiently rather than directly relax them to continuity. In addition, most of the existing methods choose to use an $n\times n$ similarity matrix for optimization, which makes the memory and computation unaffordable. In this paper we propose a novel Asymmetric Scalable Cross-Modal Hashing (ASCMH) to address these issues. It firstly introduces a collective matrix factorization to learn a common latent space from the kernelized features of different modalities, and then transforms the similarity matrix optimization to a distance-distance difference problem minimization with the help of semantic labels and common latent space. Hence, the computational complexity of the $n\times n$ asymmetric optimization is relieved. In the generation of hash codes we also employ an orthogonal constraint of label information, which is indispensable for search accuracy. So the redundancy of computation can be much reduced. For efficient optimization and scalable to large-scale datasets, we adopt the two-step approach rather than optimizing simultaneously. Extensive experiments on three benchmark datasets: Wiki, MIRFlickr-25K, and NUS-WIDE, demonstrate that our ASCMH outperforms the state-of-the-art cross-modal hashing methods in terms of accuracy and efficiency.
A Single-Target License Plate Detection with Attention
Dec 12, 2021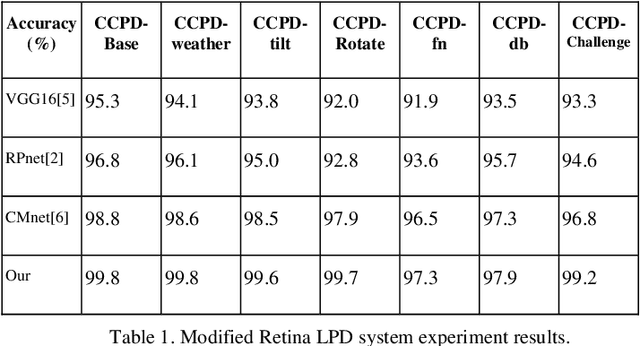
With the development of deep learning, Neural Network is commonly adopted to the License Plate Detection (LPD) task and achieves much better performance and precision, especially CNN-based networks can achieve state of the art RetinaNet[1]. For a single object detection task such as LPD, modified general object detection would be time-consuming, unable to cope with complex scenarios and a cumbersome weights file that is too hard to deploy on the embedded device.