 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Scalable Cross-modal Hashing
Paper and Code
Jul 26, 2022

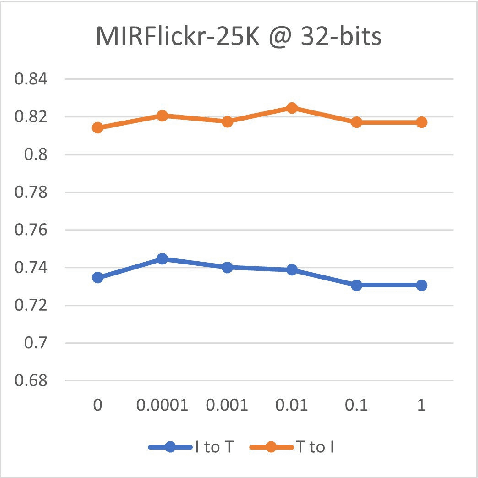

Cross-modal hashing is a successful method to solve large-scale multimedia retrieval issue. A lot of matrix factorization-based hashing methods are proposed. However, the existing methods still struggle with a few problems, such as how to generate the binary codes efficiently rather than directly relax them to continuity. In addition, most of the existing methods choose to use an $n\times n$ similarity matrix for optimization, which makes the memory and computation unaffordable. In this paper we propose a novel Asymmetric Scalable Cross-Modal Hashing (ASCMH) to address these issues. It firstly introduces a collective matrix factorization to learn a common latent space from the kernelized features of different modalities, and then transforms the similarity matrix optimization to a distance-distance difference problem minimization with the help of semantic labels and common latent space. Hence, the computational complexity of the $n\times n$ asymmetric optimization is relieved. In the generation of hash codes we also employ an orthogonal constraint of label information, which is indispensable for search accuracy. So the redundancy of computation can be much reduced. For efficient optimization and scalable to large-scale datasets, we adopt the two-step approach rather than optimizing simultaneously. Extensive experiments on three benchmark datasets: Wiki, MIRFlickr-25K, and NUS-WIDE, demonstrate that our ASCMH outperforms the state-of-the-art cross-modal hashing methods in terms of accuracy and efficiency.