 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAGE: Trustworthy Attribute Group Editing for Stable Few-shot Image Generation
Oct 23, 2024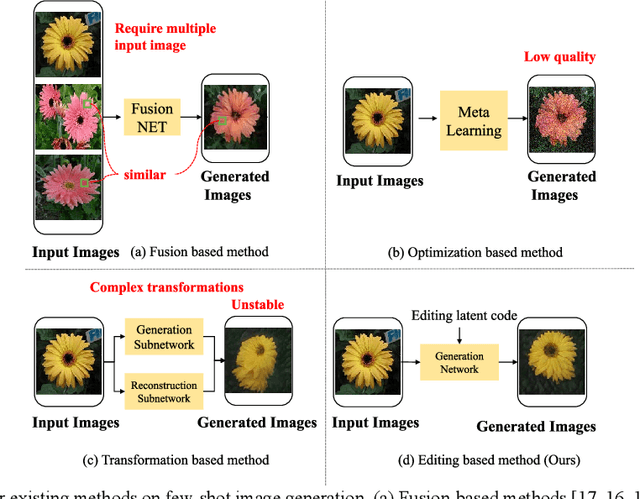
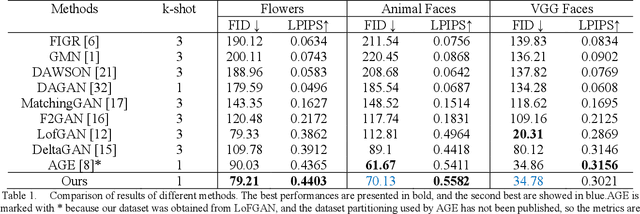


Generative Adversarial Networks (GANs) have emerged as a prominent research focus for image editing tasks, leveraging the powerful image generation capabilities of the GAN framework to produce remarkable results.However, prevailing approaches are contingent upon extensive training datasets and explicit supervision, presenting a significant challenge in manipulating the diverse attributes of new image classes with limited sample availability. To surmount this hurdle, we introduce TAGE, an innovative image generation network comprising three integral modules: the Codebook Learning Module (CLM), the Code Prediction Module (CPM) and the Prompt-driven Semantic Module (PSM). The CPM module delves into the semantic dimensions of category-agnostic attributes, encapsulating them within a discrete codebook. This module is predicated on the concept that images are assemblages of attributes, and thus, by editing these category-independent attributes, it is theoretically possible to generate images from unseen categories. Subsequently, the CPM module facilitates naturalistic image editing by predicting indices of category-independent attribute vectors within the codebook. Additionally, the PSM module generates semantic cues that are seamlessly integrated into the Transformer architecture of the CPM, enhancing the model's comprehension of the targeted attributes for editing. With these semantic cues, the model can generate images that accentuate desired attributes more prominently while maintaining the integrity of the original category, even with a limited number of samples. We have conducted extensive experiments utilizing the Animal Faces, Flowers, and VGGFaces datasets. The results of these experiments demonstrate that our proposed method not only achieves superior performance but also exhibits a high degree of stability when compared to other few-shot image generation techniques.
QEAN: Quaternion-Enhanced Attention Network for Visual Dance Generation
Mar 18, 2024The study of music-generated dance is a novel and challenging Image generation task. It aims to input a piece of music and seed motions, then generate natural dance movements for the subsequent music. Transformer-based methods face challenges in time series prediction tasks related to human movements and music due to their struggle in capturing the nonlinear relationship and temporal aspects. This can lead to issues like joint deformation, role deviation, floating, and inconsistencies in dance movements generated in response to the music. In this paper, we propose a Quaternion-Enhanced Attention Network (QEAN) for visual dance synthesis from a quaternion perspective, which consists of a Spin Position Embedding (SPE) module and a Quaternion Rotary Attention (QRA) module. First, SPE embeds position information into self-attention in a rotational manner, leading to better learning of features of movement sequences and audio sequences, and improved understanding of the connection between music and dance. Second, QRA represents and fuses 3D motion features and audio features in the form of a series of quaternions, enabling the model to better learn the temporal coordination of music and dance under the complex temporal cycle conditions of dance generation. Finally, we conducted experiments on the dataset AIST++, and the results show that our approach achieves better and more robust performance in generating accurate, high-quality dance movements. Our source code and dataset can be available from https://github.com/MarasyZZ/QEAN and https://google.github.io/aistplusplus_dataset respectively.