 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFEC: Multivariate Time-Series Clustering via Temporal-Frequency Enhanced Contrastive Learning
Jan 12, 2026Multivariate Time-Series (MTS) clustering is crucial for signal processing and data analysis. Although deep learning approaches, particularly those leveraging Contrastive Learning (CL), are prominent for MTS representation, existing CL-based models face two key limitations: 1) neglecting clustering information during positive/negative sample pair construction, and 2) introducing unreasonable inductive biases, e.g., destroying time dependence and periodicity through augmentation strategies, compromising representation quality. This paper, therefore, proposes a Temporal-Frequency Enhanced Contrastive (TFEC) learning framework. To preserve temporal structure while generating low-distortion representations, a temporal-frequency Co-EnHancement (CoEH) mechanism is introduced. Accordingly, a synergistic dual-path representation and cluster distribution learning framework is designed to jointly optimize cluster structure and representation fidelity. Experiments on six real-world benchmark datasets demonstrate TFEC's superiority, achieving 4.48% average NMI gains over SOTA methods, with ablation studies validating the design. The code of the paper is available at: https://github.com/yueliangy/TFEC.
Multi-scale Quaternion CNN and BiGRU with Cross Self-attention Feature Fusion for Fault Diagnosis of Bearing
May 25, 2024In recent years, deep learning has led to significant advances in bearing fault diagnosis (FD). Most techniques aim to achieve greater accuracy. However, they are sensitive to noise and lack robustness, resulting in insufficient domain adaptation and anti-noise ability. The comparison of studies reveals that giving equal attention to all features does not differentiate their significance. In this work, we propose a novel FD model by integrating multi-scale quaternion convolutional neural network (MQCNN), bidirectional gated recurrent unit (BiGRU), and cross self-attention feature fusion (CSAFF). We have developed innovative designs in two modules, namely MQCNN and CSAFF. Firstly, MQCNN applies quaternion convolution to multi-scale architecture for the first time, aiming to extract the rich hidden features of the original signal from multiple scales. Then, the extracted multi-scale information is input into CSAFF for feature fusion, where CSAFF innovatively incorporates cross self-attention mechanism to enhance discriminative interaction representation within features. Finally, BiGRU captures temporal dependencies while a softmax layer is employed for fault classification, achieving accurate FD. To assess the efficacy of our approach, we experiment on three public datasets (CWRU, MFPT, and Ottawa) and compare it with other excellent methods. The results confirm its state-of-the-art, which the average accuracies can achieve up to 99.99%, 100%, and 99.21% on CWRU, MFPT, and Ottawa datasets. Moreover, we perform practical tests and ablation experiments to validate the efficacy and robustness of the proposed approach. Code is available at https://github.com/mubai011/MQCCAF.
QEAN: Quaternion-Enhanced Attention Network for Visual Dance Generation
Mar 18, 2024The study of music-generated dance is a novel and challenging Image generation task. It aims to input a piece of music and seed motions, then generate natural dance movements for the subsequent music. Transformer-based methods face challenges in time series prediction tasks related to human movements and music due to their struggle in capturing the nonlinear relationship and temporal aspects. This can lead to issues like joint deformation, role deviation, floating, and inconsistencies in dance movements generated in response to the music. In this paper, we propose a Quaternion-Enhanced Attention Network (QEAN) for visual dance synthesis from a quaternion perspective, which consists of a Spin Position Embedding (SPE) module and a Quaternion Rotary Attention (QRA) module. First, SPE embeds position information into self-attention in a rotational manner, leading to better learning of features of movement sequences and audio sequences, and improved understanding of the connection between music and dance. Second, QRA represents and fuses 3D motion features and audio features in the form of a series of quaternions, enabling the model to better learn the temporal coordination of music and dance under the complex temporal cycle conditions of dance generation. Finally, we conducted experiments on the dataset AIST++, and the results show that our approach achieves better and more robust performance in generating accurate, high-quality dance movements. Our source code and dataset can be available from https://github.com/MarasyZZ/QEAN and https://google.github.io/aistplusplus_dataset respectively.
ImageCAS: A Large-Scale Dataset and Benchmark for Coronary Artery Segmentation based on Computed Tomography Angiography Images
Nov 03, 2022Cardiovascular disease (CVD) accounts for about half of non-communicable diseases. Vessel stenosis in the coronary artery is considered to be the major risk of CVD. Computed tomography angiography (CTA) is one of the widely used noninvasive imaging modalities in coronary artery diagnosis due to its superior image resolution. Clinically, segmentation of coronary arteries is essential for the diagnosis and quantification of coronary artery disease. Recently, a variety of works have been proposed to address this problem. However, on one hand, most works rely on in-house datasets, and only a few works published their datasets to the public which only contain tens of images. On the other hand, their source code have not been published, and most follow-up works have not made comparison with existing works, which makes it difficult to judge the effectiveness of the methods and hinders the further exploration of this challenging yet critical problem in the community. In this paper, we propose a large-scale dataset for coronary artery segmentation on CTA images. In addition, we have implemented a benchmark in which we have tried our best to implement several typical existing methods. Furthermore, we propose a strong baseline method which combines multi-scale patch fusion and two-stage processing to extract the details of vessels. Comprehensive experiments show that the proposed method achieves better performance than existing works on the proposed large-scale dataset. The benchmark and the dataset are published at https://github.com/XiaoweiXu/ImageCAS-A-Large-Scale-Dataset-and-Benchmark-for-Coronary-Artery-Segmentation-based-on-CT.
Predicting missing links via correlation between nodes
Sep 30, 2014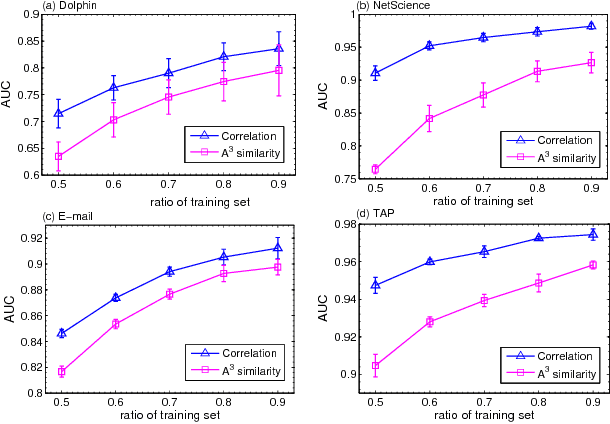
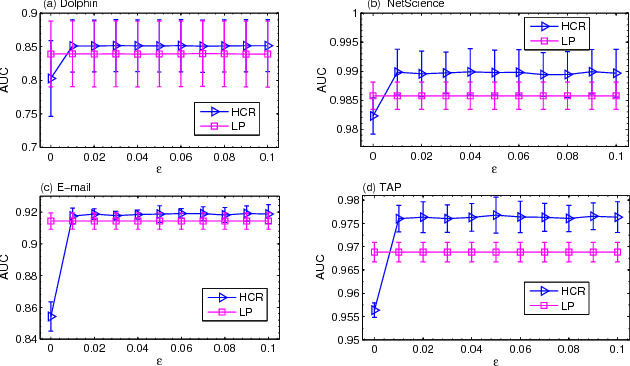
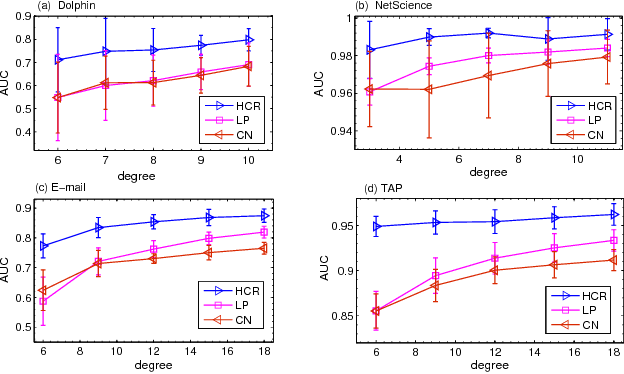
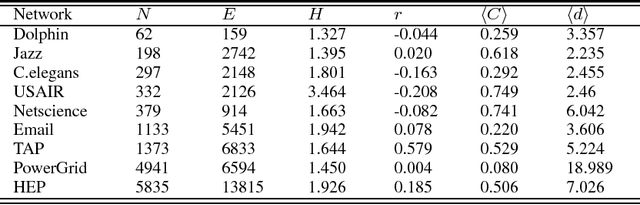
As a fundamental problem in many different fields, link prediction aims to estimate the likelihood of an existing link between two nodes based on the observed information. Since this problem is related to many applications ranging from uncovering missing data to predicting the evolution of networks, link prediction has been intensively investigated recently and many methods have been proposed so far. The essential challenge of link prediction is to estimate the similarity between nodes. Most of the existing methods are based on the common neighbor index and its variants. In this paper, we propose to calculate the similarity between nodes by the correlation coefficient. This method is found to be very effective when applied to calculate similarity based on high order paths. We finally fuse the correlation-based method with the resource allocation method, and find that the combined method can substantially outperform the existing methods, especially in sparse networks.