 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Quaternion CNN and BiGRU with Cross Self-attention Feature Fusion for Fault Diagnosis of Bearing
May 25, 2024In recent years, deep learning has led to significant advances in bearing fault diagnosis (FD). Most techniques aim to achieve greater accuracy. However, they are sensitive to noise and lack robustness, resulting in insufficient domain adaptation and anti-noise ability. The comparison of studies reveals that giving equal attention to all features does not differentiate their significance. In this work, we propose a novel FD model by integrating multi-scale quaternion convolutional neural network (MQCNN), bidirectional gated recurrent unit (BiGRU), and cross self-attention feature fusion (CSAFF). We have developed innovative designs in two modules, namely MQCNN and CSAFF. Firstly, MQCNN applies quaternion convolution to multi-scale architecture for the first time, aiming to extract the rich hidden features of the original signal from multiple scales. Then, the extracted multi-scale information is input into CSAFF for feature fusion, where CSAFF innovatively incorporates cross self-attention mechanism to enhance discriminative interaction representation within features. Finally, BiGRU captures temporal dependencies while a softmax layer is employed for fault classification, achieving accurate FD. To assess the efficacy of our approach, we experiment on three public datasets (CWRU, MFPT, and Ottawa) and compare it with other excellent methods. The results confirm its state-of-the-art, which the average accuracies can achieve up to 99.99%, 100%, and 99.21% on CWRU, MFPT, and Ottawa datasets. Moreover, we perform practical tests and ablation experiments to validate the efficacy and robustness of the proposed approach. Code is available at https://github.com/mubai011/MQCCAF.
Scalable and Modular Robustness Analysis of Deep Neural Networks
Aug 31, 2021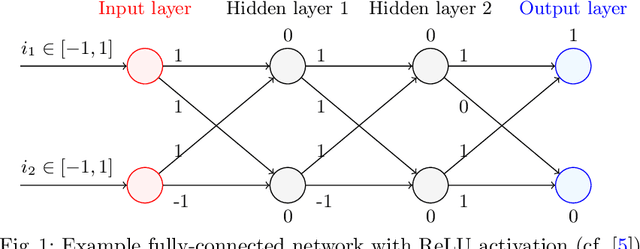
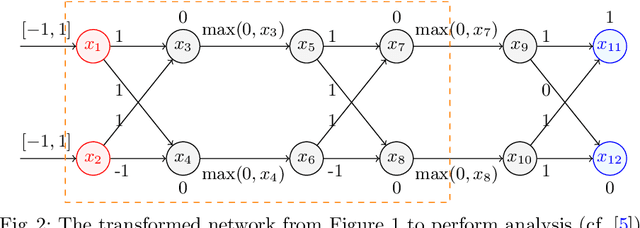
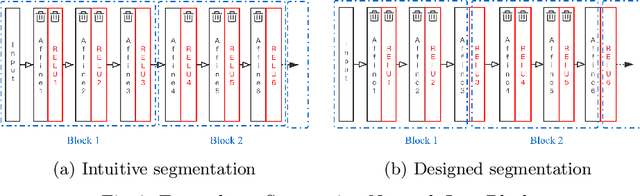
As neural networks are trained to be deeper and larger, the scalability of neural network analyzers is urgently required. The main technical insight of our method is modularly analyzing neural networks by segmenting a network into blocks and conduct the analysis for each block. In particular, we propose the network block summarization technique to capture the behaviors within a network block using a block summary and leverage the summary to speed up the analysis process. We instantiate our method in the context of a CPU-version of the state-of-the-art analyzer DeepPoly and name our system as Bounded-Block Poly (BBPoly). We evaluate BBPoly extensively on various experiment settings. The experimental result indicates that our method yields comparable precision as DeepPoly but runs faster and requires less computational resources. For example, BBPoly can analyze really large neural networks like SkipNet or ResNet which contain up to one million neurons in less than around 1 hour per input image, while DeepPoly needs to spend even 40 hours to analyze one image.
Nuclear Norm based Matrix Regression with Applications to Face Recognition with Occlusion and Illumination Changes
May 06, 2014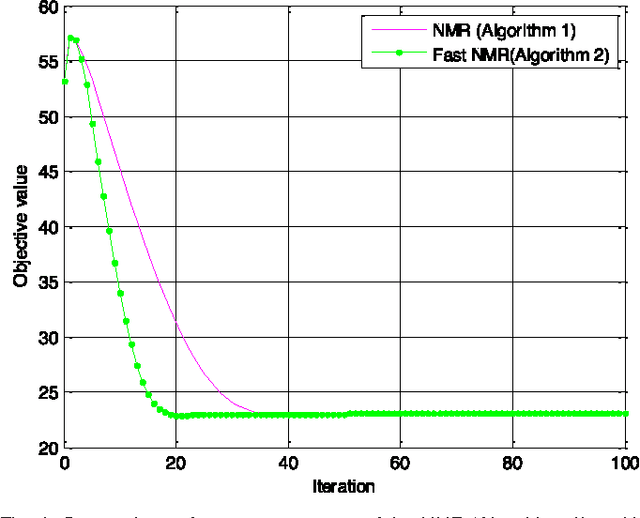
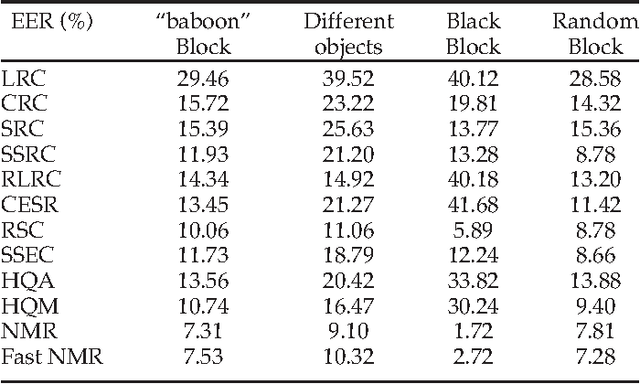
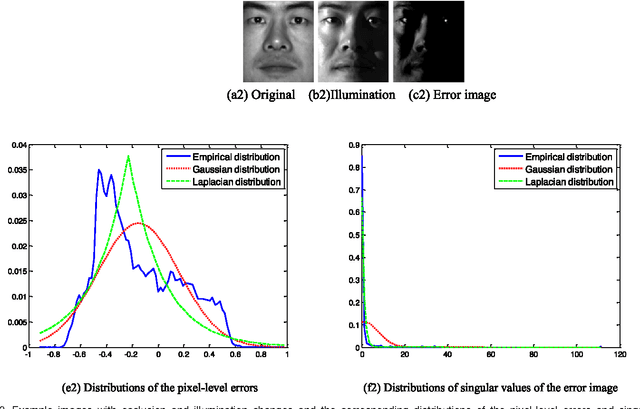
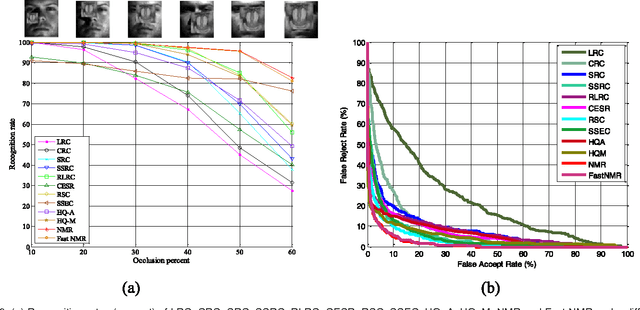
Recently regression analysis becomes a popular tool for face recognition. The existing regression methods all use the one-dimensional pixel-based error model, which characterizes the representation error pixel by pixel individually and thus neglects the whole structure of the error image. We observe that occlusion and illumination changes generally lead to a low-rank error image. To make use of this low-rank structural information, this paper presents a two-dimensional image matrix based error model, i.e. matrix regression, for face representation and classification. Our model uses the minimal nuclear norm of representation error image as a criterion, and the alternating direction method of multipliers method to calculate the regression coefficients. Compared with the current regression methods, the proposed Nuclear Norm based Matrix Regression (NMR) model is more robust for alleviating the effect of illumination, and more intuitive and powerful for removing the structural noise caused by occlusion. We experiment using four popular face image databases, the Extended Yale B database, the AR database, the Multi-PIE and the FRGC database. Experimental results demonstrate the performance advantage of NMR over the state-of-the-art regression based face recognition methods.