 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Single to Multiple: Leveraging Multi-level Prediction Spaces for Video Forecasting
Paper and Code
Jul 21, 2021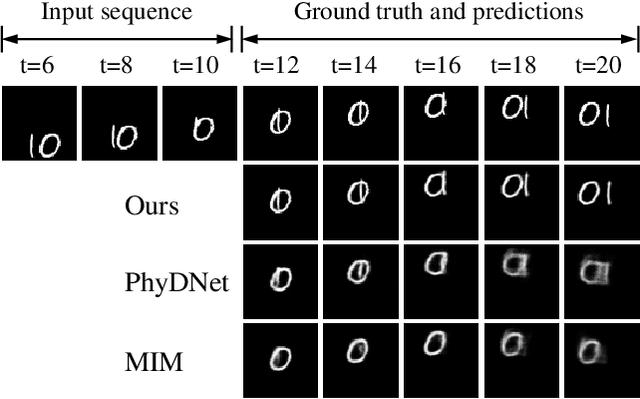
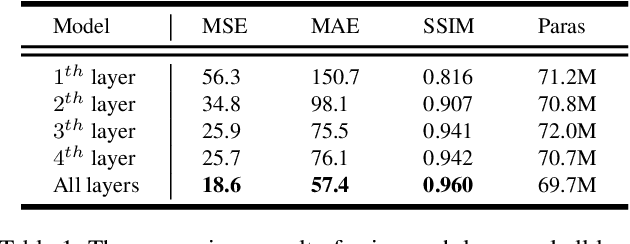
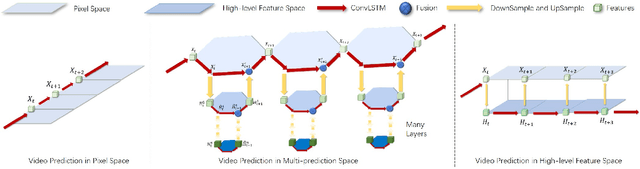
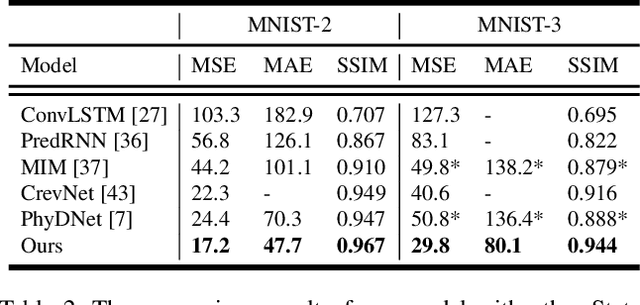
Despite video forecasting has been a widely explored topic in recent years, the mainstream of the existing work still limits their models with a single prediction space but completely neglects the way to leverage their model with multi-prediction spaces. This work fills this gap. For the first time, we deeply study numerous strategies to perform video forecasting in multi-prediction spaces and fuse their results together to boost performance. The prediction in the pixel space usually lacks the ability to preserve the semantic and structure content of the video however the prediction in the high-level feature space is prone to generate errors in the reduction and recovering process. Therefore, we build a recurrent connection between different feature spaces and incorporate their generations in the upsampling process. Rather surprisingly, this simple idea yields a much more significant performance boost than PhyDNet (performance improved by 32.1% MAE on MNIST-2 dataset, and 21.4% MAE on KTH dataset). Both qualitative and quantitative evaluations on four datasets demonstrate the generalization ability and effectiveness of our approach. We show that our model significantly reduces the troublesome distortions and blurry artifacts and brings remarkable improvements to the accuracy in long term video prediction. The code will be released soon.