 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARMOR-MAD: Adaptive Routing for Heterogeneous Multi-Agent Debate in Large Language Model Reasoning
Jun 11, 2026Multi-agent debate (MAD) can improve large language model reasoning, but fixed debate pipelines often waste computation and can amplify correlated errors among similar agents. We propose ARMOR-MAD, a training-free heterogeneous MAD framework that treats debate as conditional computation. ARMOR-MAD combines three components: Pre-debate Agreement Routing (PAR) decides whether independently generated Round-0 answers require debate; Early Agreement Stopping Evaluator (EASE) stops debate after convergence; and Semantic Outlier Detection (SOD) down-weights abnormal final answers during aggregation. Across MATH Level 5, GSM8K, MMLU, and MMLU-Pro, ARMOR-MAD consistently improves over fixed-round heterogeneous debate with the same model pool, reaching 65.5\%, 96.5\%, 90.0\%, and 81.5\% accuracy, respectively. The results suggest that genuine model heterogeneity and agreement-based control are both important for making MAD more accurate and efficient.
SICI: A Semantic-Pragmatic Complexity Index Reveals Regime Shifts in LLM Stance Detection
Jun 11, 2026Prompt-based LLMs are increasingly used for stance detection, but harder examples are not always repaired by clearer instructions, reasoning prompts, retrieval, or debate. We introduce SICI (Stance Inference Complexity Index), a seven-dimensional diagnostic measure of the semantic-pragmatic burden imposed by a target--text pair. Across SemEval-2016 and VAST, SICI predicts LLM accuracy better than surface proxies and shows substantial cross-scorer reliability ($α=0.771$). More importantly, LLM errors change regime as SICI increases: low-complexity examples invite over-attribution, especially Against predictions; intermediate examples form an unstable boundary; and high-complexity examples rapidly concentrate on None. This phase-transition-like structure persists across GPT-3.5, GPT-4o-mini, DeepSeek-V3, and GPT-4o, although stronger models move the boundaries. A 15-method intervention study further shows that prompting, retrieval, and debate often shift models along the attribution--abstention axis rather than removing the high-complexity bottleneck.
A Context-Aware Dataset for Stance Detection in Bioethical Controversies on Reddit
Jun 11, 2026Bioethical debates increasingly unfold on social media, yet stance detection research lacks large-scale, domain-specific resources for modeling such context-dependent discourse. We present BioStance, a context-aware dataset of 39,600 annotated Post-Comment pairs from Reddit bioethical discussions. BioStance covers six controversial targets across three dimensions of bioethical controversy: fundamental value conflicts, individual liberty versus collective responsibility, and technological uncertainty. Each instance preserves hierarchical conversational context and is labeled by three independent annotators using a three-class stance scheme: Favor, Against, and None. The annotations achieve a mean Krippendorff's $α$ of 0.82, indicating substantial reliability. By combining thematic diversity, conversational structure, and high-quality human annotation, BioStance supports research on context-aware stance detection, argument mining, and computational analysis of bioethical discourse.
Abstract, Align, Predict: Zero-Shot Stance Detection via Cognitive Inductive Reasoning
Jun 16, 2025Zero-shot stance detection (ZSSD) aims to identify the stance of text toward previously unseen targets, a setting where conventional supervised models often fail due to reliance on labeled data and shallow lexical cues. Inspired by human cognitive reasoning, we propose the Cognitive Inductive Reasoning Framework (CIRF), which abstracts transferable reasoning schemas from unlabeled text and encodes them as concept-level logic. To integrate these schemas with input arguments, we introduce a Schema-Enhanced Graph Kernel Model (SEGKM) that dynamically aligns local and global reasoning structures. Experiments on SemEval-2016, VAST, and COVID-19-Stance benchmarks show that CIRF establishes new state-of-the-art results, outperforming strong ZSSD baselines by 1.0, 4.5, and 3.3 percentage points in macro-F1, respectively, and achieving comparable accuracy with 70\% fewer labeled examples. We will release the full code upon publication.
C-MTCSD: A Chinese Multi-Turn Conversational Stance Detection Dataset
Apr 14, 2025Stance detection has become an essential tool for analyzing public discussions on social media. Current methods face significant challenges, particularly in Chinese language processing and multi-turn conversational analysis. To address these limitations, we introduce C-MTCSD, the largest Chinese multi-turn conversational stance detection dataset, comprising 24,264 carefully annotated instances from Sina Weibo, which is 4.2 times larger than the only prior Chinese conversational stance detection dataset. Our comprehensive evaluation using both traditional approaches and large language models reveals the complexity of C-MTCSD: even state-of-the-art models achieve only 64.07% F1 score in the challenging zero-shot setting, while performance consistently degrades with increasing conversation depth. Traditional models particularly struggle with implicit stance detection, achieving below 50% F1 score. This work establishes a challenging new benchmark for Chinese stance detection research, highlighting significant opportunities for future improvements.
DualCoTs: Dual Chain-of-Thoughts Prompting for Sentiment Lexicon Expansion of Idioms
Sep 26, 2024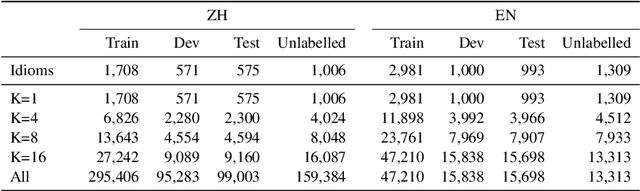
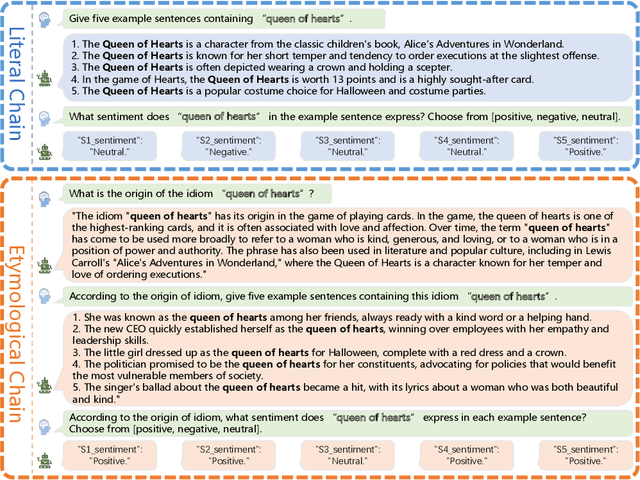
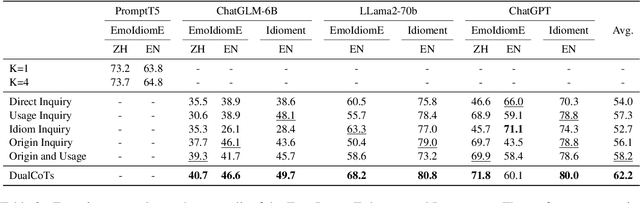

Idioms represent a ubiquitous vehicle for conveying sentiments in the realm of everyday discourse, rendering the nuanced analysis of idiom sentiment crucial for a comprehensive understanding of emotional expression within real-world texts. Nevertheless, the existing corpora dedicated to idiom sentiment analysis considerably limit research in text sentiment analysis. In this paper, we propose an innovative approach to automatically expand the sentiment lexicon for idioms, leveraging the capabilities of large language models through the application of Chain-of-Thought prompting. To demonstrate the effectiveness of this approach, we integrate multiple existing resources and construct an emotional idiom lexicon expansion dataset (called EmoIdiomE), which encompasses a comprehensive repository of Chinese and English idioms. Then we designed the Dual Chain-of-Thoughts (DualCoTs) method, which combines insights from linguistics and psycholinguistics, to demonstrate the effectiveness of using large models to automatically expand the sentiment lexicon for idioms. Experiments show that DualCoTs is effective in idioms sentiment lexicon expansion in both Chinese and English. For reproducibility, we will release the data and code upon acceptance.
Multimodal Multi-turn Conversation Stance Detection: A Challenge Dataset and Effective Model
Sep 01, 2024



Stance detection, which aims to identify public opinion towards specific targets using social media data, is an important yet challenging task. With the proliferation of diverse multimodal social media content including text, and images multimodal stance detection (MSD) has become a crucial research area. However, existing MSD studies have focused on modeling stance within individual text-image pairs, overlooking the multi-party conversational contexts that naturally occur on social media. This limitation stems from a lack of datasets that authentically capture such conversational scenarios, hindering progress in conversational MSD. To address this, we introduce a new multimodal multi-turn conversational stance detection dataset (called MmMtCSD). To derive stances from this challenging dataset, we propose a novel multimodal large language model stance detection framework (MLLM-SD), that learns joint stance representations from textual and visual modalities. Experiments on MmMtCSD show state-of-the-art performance of our proposed MLLM-SD approach for multimodal stance detection. We believe that MmMtCSD will contribute to advancing real-world applications of stance detection research.
MIPS at SemEval-2024 Task 3: Multimodal Emotion-Cause Pair Extraction in Conversations with Multimodal Language Models
Apr 11, 2024



This paper presents our winning submission to Subtask 2 of SemEval 2024 Task 3 on multimodal emotion cause analysis in conversations. We propose a novel Multimodal Emotion Recognition and Multimodal Emotion Cause Extraction (MER-MCE) framework that integrates text, audio, and visual modalities using specialized emotion encoders. Our approach sets itself apart from top-performing teams by leveraging modality-specific features for enhanced emotion understanding and causality inference. Experimental evaluation demonstrates the advantages of our multimodal approach, with our submission achieving a competitive weighted F1 score of 0.3435, ranking third with a margin of only 0.0339 behind the 1st team and 0.0025 behind the 2nd team. Project: https://github.com/MIPS-COLT/MER-MCE.git
A Challenge Dataset and Effective Models for Conversational Stance Detection
Mar 21, 2024



Previous stance detection studies typically concentrate on evaluating stances within individual instances, thereby exhibiting limitations in effectively modeling multi-party discussions concerning the same specific topic, as naturally transpire in authentic social media interactions. This constraint arises primarily due to the scarcity of datasets that authentically replicate real social media contexts, hindering the research progress of conversational stance detection. In this paper, we introduce a new multi-turn conversation stance detection dataset (called \textbf{MT-CSD}), which encompasses multiple targets for conversational stance detection. To derive stances from this challenging dataset, we propose a global-local attention network (\textbf{GLAN}) to address both long and short-range dependencies inherent in conversational data. Notably, even state-of-the-art stance detection methods, exemplified by GLAN, exhibit an accuracy of only 50.47\%, highlighting the persistent challenges in conversational stance detection. Furthermore, our MT-CSD dataset serves as a valuable resource to catalyze advancements in cross-domain stance detection, where a classifier is adapted from a different yet related target. We believe that MT-CSD will contribute to advancing real-world applications of stance detection research. Our source code, data, and models are available at \url{https://github.com/nfq729/MT-CSD}.
MoZIP: A Multilingual Benchmark to Evaluate Large Language Models in Intellectual Property
Feb 26, 2024Large language models (LLMs) have demonstrated impressive performance in various natural language processing (NLP) tasks. However, there is limited understanding of how well LLMs perform in specific domains (e.g, the intellectual property (IP) domain). In this paper, we contribute a new benchmark, the first Multilingual-oriented quiZ on Intellectual Property (MoZIP), for the evaluation of LLMs in the IP domain. The MoZIP benchmark includes three challenging tasks: IP multiple-choice quiz (IPQuiz), IP question answering (IPQA), and patent matching (PatentMatch). In addition, we also develop a new IP-oriented multilingual large language model (called MoZi), which is a BLOOMZ-based model that has been supervised fine-tuned with multilingual IP-related text data. We evaluate our proposed MoZi model and four well-known LLMs (i.e., BLOOMZ, BELLE, ChatGLM and ChatGPT) on the MoZIP benchmark. Experimental results demonstrate that MoZi outperforms BLOOMZ, BELLE and ChatGLM by a noticeable margin, while it had lower scores compared with ChatGPT. Notably, the performance of current LLMs on the MoZIP benchmark has much room for improvement, and even the most powerful ChatGPT does not reach the passing level. Our source code, data, and models are available at \url{https://github.com/AI-for-Science/MoZi}.