 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernelBench-X: A Comprehensive Benchmark for Evaluating LLM-Generated GPU Kernels
May 06, 2026LLM-based Triton kernel generation has attracted significant interest, yet a fundamental empirical question remains unanswered: where does this capability break down, and why? We present KernelBench-X, a benchmark designed to answer this question through category-aware evaluation of correctness and hardware efficiency across 176 tasks in 15 categories. Our systematic comparison of five representative methods yields three main findings. First, task structure determines correctness more than method design. Category explains nearly three times more variance in semantic correctness than method (9.4% vs 3.3% explained deviance), and 72% of Fusion tasks fail across all five methods while Math tasks are solved consistently. Second, iterative refinement improves correctness, but not performance. Across GEAK iterations, compile rate rises from 52.3% to 68.8% while average speedup declines from $1.58\times$ to $1.44\times$; newly rescued kernels consistently underperform persistently correct ones ($1.16\times$ vs $1.58\times$ speedup in round~0$\to$1). Third, correctness does not imply efficiency. 46.6% of correct kernels are slower than the PyTorch eager baseline, and cross-hardware speedup variance reaches $21.4\times$. Besides, quantization remains completely unsolved (0/30 successes) despite non-trivial compilation rates, revealing systematic misunderstanding of numerical computation contracts rather than surface-level syntax errors. These findings suggest that future progress depends on handling global coordination, explicitly modeling numerical precision, and incorporating hardware efficiency into generation. The code is available at https://github.com/BonnieW05/KernelBenchX
SageBwd: A Trainable Low-bit Attention
Mar 02, 2026Low-bit attention, such as SageAttention, has emerged as an effective approach for accelerating model inference, but its applicability to training remains poorly understood. In prior work, we introduced SageBwd, a trainable INT8 attention that quantizes six of seven attention matrix multiplications while preserving fine-tuning performance. However, SageBwd exhibited a persistent performance gap to full-precision attention (FPA) during pre-training. In this work, we investigate why this gap occurs and demonstrate that SageBwd matches full-precision attention during pretraining. Through experiments and theoretical analysis, we reach a few important insights and conclusions: (i) QK-norm is necessary for stable training at large tokens per step, (ii) quantization errors primarily arise from the backward-pass score gradient dS, (iii) reducing tokens per step enables SageBwd to match FPA performance in pre-training, and (iv) K-smoothing remains essential for training stability, while Q-smoothing provides limited benefit during pre-training.
SpargeAttention2: Trainable Sparse Attention via Hybrid Top-k+Top-p Masking and Distillation Fine-Tuning
Feb 13, 2026Many training-free sparse attention methods are effective for accelerating diffusion models. Recently, several works suggest that making sparse attention trainable can further increase sparsity while preserving generation quality. We study three key questions: (1) when do the two common masking rules, i.e., Top-k and Top-p, fail, and how can we avoid these failures? (2) why can trainable sparse attention reach higher sparsity than training-free methods? (3) what are the limitations of fine-tuning sparse attention using the diffusion loss, and how can we address them? Based on this analysis, we propose SpargeAttention2, a trainable sparse attention method that achieves high sparsity without degrading generation quality. SpargeAttention2 includes (i) a hybrid masking rule that combines Top-k and Top-p for more robust masking at high sparsity, (ii) an efficient trainable sparse attention implementation, and (iii) a distillation-inspired fine-tuning objective to better preserve generation quality during fine-tuning using sparse attention. Experiments on video diffusion models show that SpargeAttention2 reaches 95% attention sparsity and a 16.2x attention speedup while maintaining generation quality, consistently outperforming prior sparse attention methods.
SLA2: Sparse-Linear Attention with Learnable Routing and QAT
Feb 13, 2026Sparse-Linear Attention (SLA) combines sparse and linear attention to accelerate diffusion models and has shown strong performance in video generation. However, (i) SLA relies on a heuristic split that assigns computations to the sparse or linear branch based on attention-weight magnitude, which can be suboptimal. Additionally, (ii) after formally analyzing the attention error in SLA, we identify a mismatch between SLA and a direct decomposition into sparse and linear attention. We propose SLA2, which introduces (I) a learnable router that dynamically selects whether each attention computation should use sparse or linear attention, (II) a more faithful and direct sparse-linear attention formulation that uses a learnable ratio to combine the sparse and linear attention branches, and (III) a sparse + low-bit attention design, where low-bit attention is introduced via quantization-aware fine-tuning to reduce quantization error. Experiments show that on video diffusion models, SLA2 can achieve 97% attention sparsity and deliver an 18.6x attention speedup while preserving generation quality.
HiGR: Efficient Generative Slate Recommendation via Hierarchical Planning and Multi-Objective Preference Alignment
Dec 31, 2025Slate recommendation, where users are presented with a ranked list of items simultaneously, is widely adopted in online platforms. Recent advances in generative models have shown promise in slate recommendation by modeling sequences of discrete semantic IDs autoregressively. However, existing autoregressive approaches suffer from semantically entangled item tokenization and inefficient sequential decoding that lacks holistic slate planning. To address these limitations, we propose HiGR, an efficient generative slate recommendation framework that integrates hierarchical planning with listwise preference alignment. First, we propose an auto-encoder utilizing residual quantization and contrastive constraints to tokenize items into semantically structured IDs for controllable generation. Second, HiGR decouples generation into a list-level planning stage for global slate intent, followed by an item-level decoding stage for specific item selection. Third, we introduce a listwise preference alignment objective to directly optimize slate quality using implicit user feedback. Experiments on our large-scale commercial media platform demonstrate that HiGR delivers consistent improvements in both offline evaluations and online deployment. Specifically, it outperforms state-of-the-art methods by over 10% in offline recommendation quality with a 5x inference speedup, while further achieving a 1.22% and 1.73% increase in Average Watch Time and Average Video Views in online A/B tests.
PhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times
Dec 18, 2025We introduce TurboDiffusion, a video generation acceleration framework that can speed up end-to-end diffusion generation by 100-200x while maintaining video quality. TurboDiffusion mainly relies on several components for acceleration: (1) Attention acceleration: TurboDiffusion uses low-bit SageAttention and trainable Sparse-Linear Attention (SLA) to speed up attention computation. (2) Step distillation: TurboDiffusion adopts rCM for efficient step distillation. (3) W8A8 quantization: TurboDiffusion quantizes model parameters and activations to 8 bits to accelerate linear layers and compress the model. In addition, TurboDiffusion incorporates several other engineering optimizations. We conduct experiments on the Wan2.2-I2V-14B-720P, Wan2.1-T2V-1.3B-480P, Wan2.1-T2V-14B-720P, and Wan2.1-T2V-14B-480P models. Experimental results show that TurboDiffusion achieves 100-200x speedup for video generation even on a single RTX 5090 GPU, while maintaining comparable video quality. The GitHub repository, which includes model checkpoints and easy-to-use code, is available at https://github.com/thu-ml/TurboDiffusion.
SpikeATac: A Multimodal Tactile Finger with Taxelized Dynamic Sensing for Dexterous Manipulation
Oct 30, 2025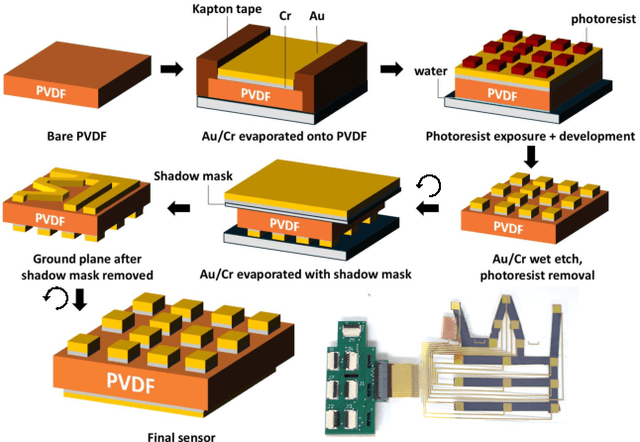
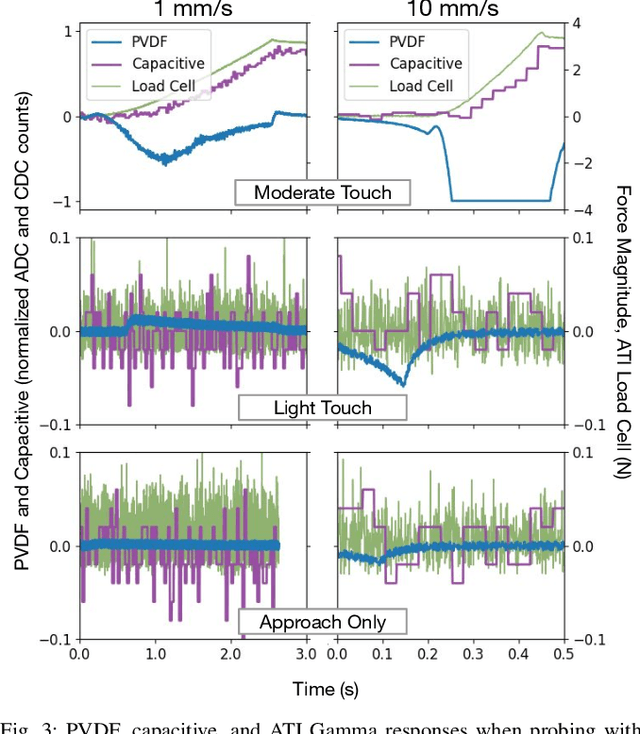
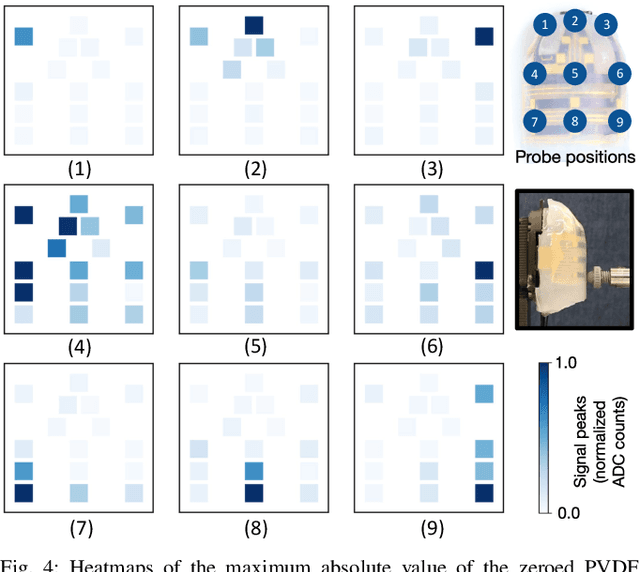
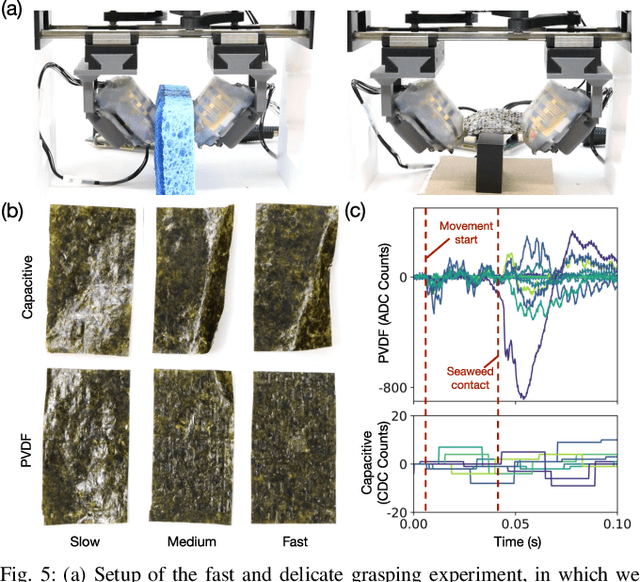
In this work, we introduce SpikeATac, a multimodal tactile finger combining a taxelized and highly sensitive dynamic response (PVDF) with a static transduction method (capacitive) for multimodal touch sensing. Named for its `spiky' response, SpikeATac's 16-taxel PVDF film sampled at 4 kHz provides fast, sensitive dynamic signals to the very onset and breaking of contact. We characterize the sensitivity of the different modalities, and show that SpikeATac provides the ability to stop quickly and delicately when grasping fragile, deformable objects. Beyond parallel grasping, we show that SpikeATac can be used in a learning-based framework to achieve new capabilities on a dexterous multifingered robot hand. We use a learning recipe that combines reinforcement learning from human feedback with tactile-based rewards to fine-tune the behavior of a policy to modulate force. Our hardware platform and learning pipeline together enable a difficult dexterous and contact-rich task that has not previously been achieved: in-hand manipulation of fragile objects. Videos are available at \href{https://roamlab.github.io/spikeatac/}{roamlab.github.io/spikeatac}.
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Sep 19, 2025Online reinforcement learning (RL) has been central to post-training language models, but its extension to diffusion models remains challenging due to intractable likelihoods. Recent works discretize the reverse sampling process to enable GRPO-style training, yet they inherit fundamental drawbacks, including solver restrictions, forward-reverse inconsistency, and complicated integration with classifier-free guidance (CFG). We introduce Diffusion Negative-aware FineTuning (DiffusionNFT), a new online RL paradigm that optimizes diffusion models directly on the forward process via flow matching. DiffusionNFT contrasts positive and negative generations to define an implicit policy improvement direction, naturally incorporating reinforcement signals into the supervised learning objective. This formulation enables training with arbitrary black-box solvers, eliminates the need for likelihood estimation, and requires only clean images rather than sampling trajectories for policy optimization. DiffusionNFT is up to $25\times$ more efficient than FlowGRPO in head-to-head comparisons, while being CFG-free. For instance, DiffusionNFT improves the GenEval score from 0.24 to 0.98 within 1k steps, while FlowGRPO achieves 0.95 with over 5k steps and additional CFG employment. By leveraging multiple reward models, DiffusionNFT significantly boosts the performance of SD3.5-Medium in every benchmark tested.
SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
May 16, 2025The efficiency of attention is important due to its quadratic time complexity. We enhance the efficiency of attention through two key contributions: First, we leverage the new FP4 Tensor Cores in Blackwell GPUs to accelerate attention computation. Our implementation achieves 1038 TOPS on RTX5090, which is a 5x speedup over the fastest FlashAttention on RTX5090. Experiments show that our FP4 attention can accelerate inference of various models in a plug-and-play way. Second, we pioneer low-bit attention to training tasks. Existing low-bit attention works like FlashAttention3 and SageAttention focus only on inference. However, the efficiency of training large models is also important. To explore whether low-bit attention can be effectively applied to training tasks, we design an accurate and efficient 8-bit attention for both forward and backward propagation. Experiments indicate that 8-bit attention achieves lossless performance in fine-tuning tasks but exhibits slower convergence in pretraining tasks. The code will be available at https://github.com/thu-ml/SageAttention.