 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^3$amba: CLIP-driven Mamba Model for Multi-modal Remote Sensing Classification
Mar 09, 2025Multi-modal fusion holds great promise for integrating information from different modalities. However, due to a lack of consideration for modal consistency, existing multi-modal fusion methods in the field of remote sensing still face challenges of incomplete semantic information and low computational efficiency in their fusion designs. Inspired by the observation that the visual language pre-training model CLIP can effectively extract strong semantic information from visual features, we propose M$^3$amba, a novel end-to-end CLIP-driven Mamba model for multi-modal fusion to address these challenges. Specifically, we introduce CLIP-driven modality-specific adapters in the fusion architecture to avoid the bias of understanding specific domains caused by direct inference, making the original CLIP encoder modality-specific perception. This unified framework enables minimal training to achieve a comprehensive semantic understanding of different modalities, thereby guiding cross-modal feature fusion. To further enhance the consistent association between modality mappings, a multi-modal Mamba fusion architecture with linear complexity and a cross-attention module Cross-SS2D are designed, which fully considers effective and efficient information interaction to achieve complete fusion. Extensive experiments have shown that M$^3$amba has an average performance improvement of at least 5.98\% compared with the state-of-the-art methods in multi-modal hyperspectral image classification tasks in the remote sensing field, while also demonstrating excellent training efficiency, achieving a double improvement in accuracy and efficiency. The code is released at https://github.com/kaka-Cao/M3amba.
DiffCLIP: Few-shot Language-driven Multimodal Classifier
Dec 10, 2024



Visual language models like Contrastive Language-Image Pretraining (CLIP) have shown impressive performance in analyzing natural images with language information. However, these models often encounter challenges when applied to specialized domains such as remote sensing due to the limited availability of image-text pairs for training. To tackle this issue, we introduce DiffCLIP, a novel framework that extends CLIP to effectively convey comprehensive language-driven semantic information for accurate classification of high-dimensional multimodal remote sensing images. DiffCLIP is a few-shot learning method that leverages unlabeled images for pretraining. It employs unsupervised mask diffusion learning to capture the distribution of diverse modalities without requiring labels. The modality-shared image encoder maps multimodal data into a unified subspace, extracting shared features with consistent parameters across modalities. A well-trained image encoder further enhances learning by aligning visual representations with class-label text information from CLIP. By integrating these approaches, DiffCLIP significantly boosts CLIP performance using a minimal number of image-text pairs. We evaluate DiffCLIP on widely used high-dimensional multimodal datasets, demonstrating its effectiveness in addressing few-shot annotated classification tasks. DiffCLIP achieves an overall accuracy improvement of 10.65% across three remote sensing datasets compared with CLIP, while utilizing only 2-shot image-text pairs. The code has been released at https://github.com/icey-zhang/DiffCLIP.
FusionSAM: Latent Space driven Segment Anything Model for Multimodal Fusion and Segmentation
Aug 26, 2024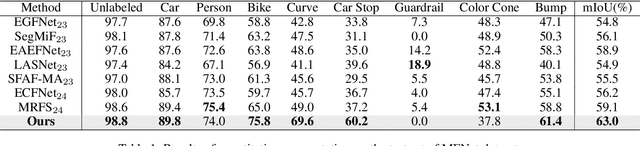
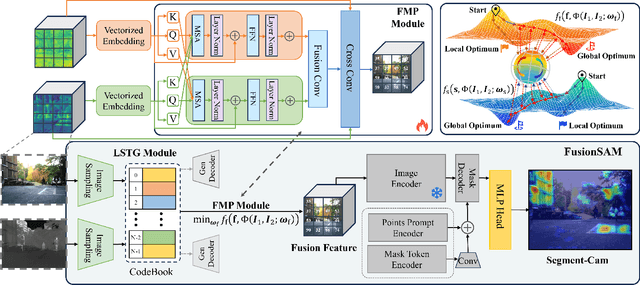
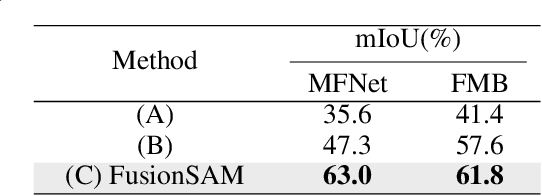

Multimodal image fusion and segmentation enhance scene understanding in autonomous driving by integrating data from various sensors. However, current models struggle to efficiently segment densely packed elements in such scenes, due to the absence of comprehensive fusion features that can guide mid-process fine-tuning and focus attention on relevant areas. The Segment Anything Model (SAM) has emerged as a transformative segmentation method. It provides more effective prompts through its flexible prompt encoder, compared to transformers lacking fine-tuned control. Nevertheless, SAM has not been extensively studied in the domain of multimodal fusion for natural images. In this paper, we introduce SAM into multimodal image segmentation for the first time, proposing a novel framework that combines Latent Space Token Generation (LSTG) and Fusion Mask Prompting (FMP) modules to enhance SAM's multimodal fusion and segmentation capabilities. Specifically, we first obtain latent space features of the two modalities through vector quantization and embed them into a cross-attention-based inter-domain fusion module to establish long-range dependencies between modalities. Then, we use these comprehensive fusion features as prompts to guide precise pixel-level segmentation. Extensive experiments on several public datasets demonstrate that the proposed method significantly outperforms SAM and SAM2 in multimodal autonomous driving scenarios, achieving at least 3.9$\%$ higher segmentation mIoU than the state-of-the-art approaches.
EfficientMFD: Towards More Efficient Multimodal Synchronous Fusion Detection
Mar 14, 2024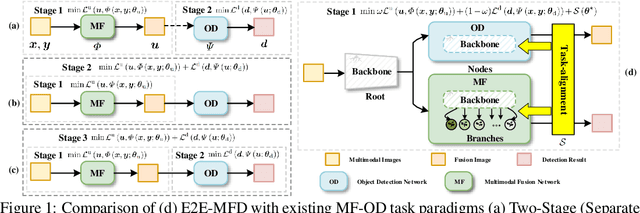
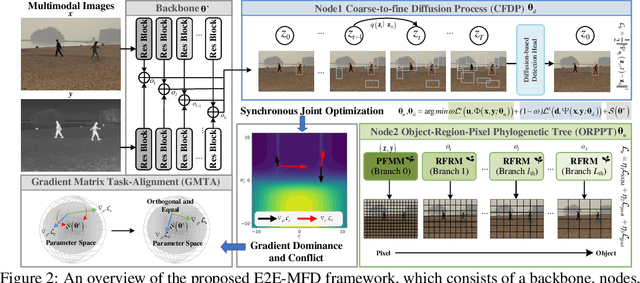
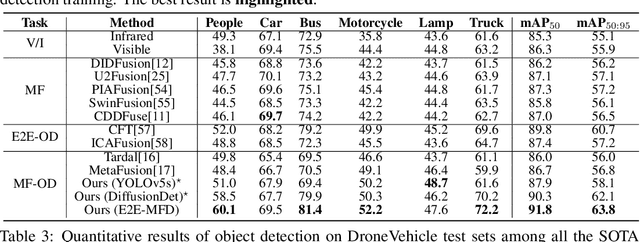

Multimodal image fusion and object detection play a vital role in autonomous driving. Current joint learning methods have made significant progress in the multimodal fusion detection task combining the texture detail and objective semantic information. However, the tedious training steps have limited its applications to wider real-world industrial deployment. To address this limitation, we propose a novel end-to-end multimodal fusion detection algorithm, named EfficientMFD, to simplify models that exhibit decent performance with only one training step. Synchronous joint optimization is utilized in an end-to-end manner between two components, thus not being affected by the local optimal solution of the individual task. Besides, a comprehensive optimization is established in the gradient matrix between the shared parameters for both tasks. It can converge to an optimal point with fusion detection weights. We extensively test it on several public datasets, demonstrating superior performance on not only visually appealing fusion but also favorable detection performance (e.g., 6.6% mAP50:95) over other state-of-the-art approaches.
Distribution-aware Interactive Attention Network and Large-scale Cloud Recognition Benchmark on FY-4A Satellite Image
Jan 06, 2024



Accurate cloud recognition and warning are crucial for various applications, including in-flight support, weather forecasting, and climate research. However, recent deep learning algorithms have predominantly focused on detecting cloud regions in satellite imagery, with insufficient attention to the specificity required for accurate cloud recognition. This limitation inspired us to develop the novel FY-4A-Himawari-8 (FYH) dataset, which includes nine distinct cloud categories and uses precise domain adaptation methods to align 70,419 image-label pairs in terms of projection, temporal resolution, and spatial resolution, thereby facilitating the training of supervised deep learning networks. Given the complexity and diversity of cloud formations, we have thoroughly analyzed the challenges inherent to cloud recognition tasks, examining the intricate characteristics and distribution of the data. To effectively address these challenges, we designed a Distribution-aware Interactive-Attention Network (DIAnet), which preserves pixel-level details through a high-resolution branch and a parallel multi-resolution cross-branch. We also integrated a distribution-aware loss (DAL) to mitigate the imbalance across cloud categories. An Interactive Attention Module (IAM) further enhances the robustness of feature extraction combined with spatial and channel information. Empirical evaluations on the FYH dataset demonstrate that our method outperforms other cloud recognition networks, achieving superior performance in terms of mean Intersection over Union (mIoU). The code for implementing DIAnet is available at https://github.com/icey-zhang/DIAnet.
SAR-Net: Multi-scale Direction-aware SAR Network via Global Information Fusion
Dec 28, 2023



Deep learning has driven significant progress in object detection using Synthetic Aperture Radar (SAR) imagery. Existing methods, while achieving promising results, often struggle to effectively integrate local and global information, particularly direction-aware features. This paper proposes SAR-Net, a novel framework specifically designed for global fusion of direction-aware information in SAR object detection. SAR-Net leverages two key innovations: the Unity Compensation Mechanism (UCM) and the Direction-aware Attention Module (DAM). UCM facilitates the establishment of complementary relationships among features across different scales, enabling efficient global information fusion. Among them, Multi-scale Alignment Module (MAM) and distinct Multi-level Fusion Module (MFM) enhance feature integration by capturing both texture detail and semantic information. Then, Multi-feature Embedding Module (MEM) feeds back global features into the primary branches, further improving information transmission. Additionally, DAM, through bidirectional attention polymerization, captures direction-aware information, effectively eliminating background interference. Extensive experiments demonstrate the effectiveness of SAR-Net, achieving state-of-the-art results on aircraft (SAR-AIRcraft-1.0) and ship datasets (SSDD, HRSID), confirming its generalization capability and robustness.