 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionSAM: Latent Space driven Segment Anything Model for Multimodal Fusion and Segmentation
Paper and Code
Aug 26, 2024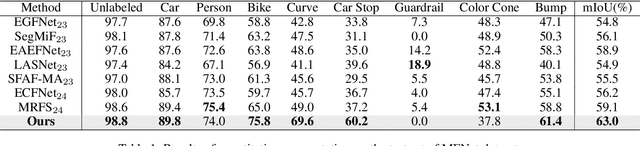
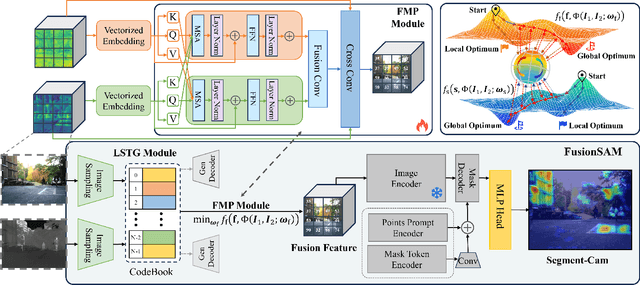
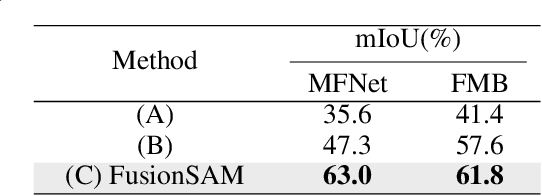

Multimodal image fusion and segmentation enhance scene understanding in autonomous driving by integrating data from various sensors. However, current models struggle to efficiently segment densely packed elements in such scenes, due to the absence of comprehensive fusion features that can guide mid-process fine-tuning and focus attention on relevant areas. The Segment Anything Model (SAM) has emerged as a transformative segmentation method. It provides more effective prompts through its flexible prompt encoder, compared to transformers lacking fine-tuned control. Nevertheless, SAM has not been extensively studied in the domain of multimodal fusion for natural images. In this paper, we introduce SAM into multimodal image segmentation for the first time, proposing a novel framework that combines Latent Space Token Generation (LSTG) and Fusion Mask Prompting (FMP) modules to enhance SAM's multimodal fusion and segmentation capabilities. Specifically, we first obtain latent space features of the two modalities through vector quantization and embed them into a cross-attention-based inter-domain fusion module to establish long-range dependencies between modalities. Then, we use these comprehensive fusion features as prompts to guide precise pixel-level segmentation. Extensive experiments on several public datasets demonstrate that the proposed method significantly outperforms SAM and SAM2 in multimodal autonomous driving scenarios, achieving at least 3.9$\%$ higher segmentation mIoU than the state-of-the-art approaches.